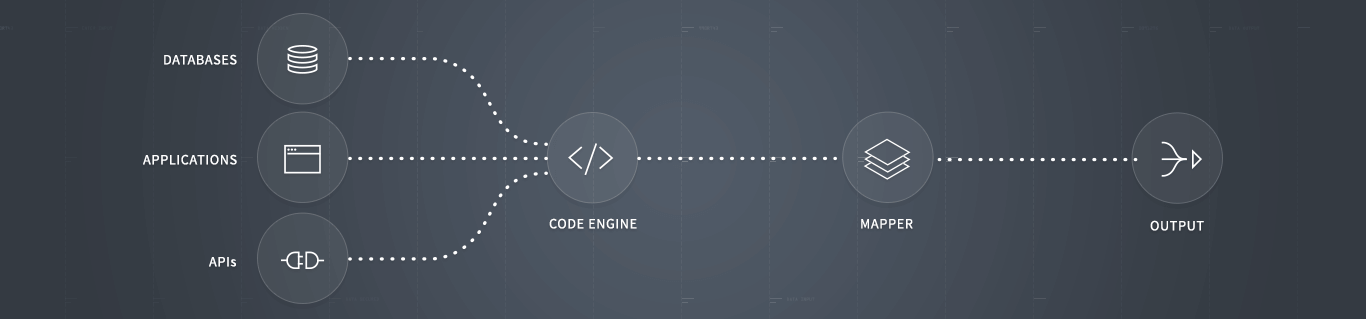
4 Internet Creeping Versions Web Scratching With Python, Second Version Book
4 Internet Creeping Models Web Scratching With Python, Second Edition Publication You're not making 10s of How to choose the right custom ETL service provider thousands of requests to one web site simultaneously; you're making 10 demands, waiting a couple of mins, making an additional 10 requests, waiting a couple of minutes, and so forth. The searchUrl specifies where you need to go to get search results if you append the topic you are looking for. The resultListing defines the "box" that holds details regarding each outcome, and the resultUrl specifies the tag inside this box that will give you the specific link for the result. The absoluteUrl building is a boolean that tells you whether these search engine result are outright or family member Links. Information crawling is used for data extraction and describes gathering information from either the around the world web or from any kind of file or data. The requirement for web information crawling has actually been on the increase in the previous few years. The information crawled can be utilized for evaluation or forecast purposes under different scenarios, such as market evaluation, rate monitoring, list building, and so on. Here, I wish to present 3 methods to creep information from a site, as well as the pros and cons of each strategy. By having it Custom Business Intelligence Services resemble a browser, you minimize the likelihood of being blocked by the site and make it most likely that you'll get the information you need. Tools like ScrapingBee provide a checklist of rotating proxies and produce valid customer agents; this is a terrific aid when scuffing large quantities of data.
Browserless Arrangement
The Crawler class has methods as well as habits that define how to follow Links and also essence information from the web pages it locates, yet it does not know where to look or what data to seek. The scraper will certainly be easily expanding so you can tinker about with it and use it as a structure for your very own projects scuffing data from the internet. We have the tools to make some rather complex web scrapes now, but there's still the issue with Javascript rendering. This is something that deserves its own write-up, but for currently we can do rather a lot.
Contact Us
Datahen
Email: services@datahen.com
Phone: +1 6476979191
2 Bloor St W
Toronto, Ontario, Canada M4W 3E2
Specific sites reject to supply any kind of public APIs as a result of technological limitations or other reasons. In such situations, some individuals might select RSS feeds, yet I don't recommend using them because they have a number limit. What I wish to go over right here is just how to develop a spider on our own to handle this situation.
Contrast And Comparison Between Data Scraping And Also Crawling
In the above paragraph, I discussed these tools with corresponding links. I very recommend you inspect them out prior to diving right into the instance. Once you have that, you want to determine the distinct tags that are around the price so you can utilize that in your data scraper. Some great tags Web Scraping Services would certainly be div tags with IDs or extremely certain course names. There are now information scrapingAI on the market that can utilize machine learningto keep on improving at acknowledging inputs which only people have actually typically been able to analyze-- like photos. Feeding item data from your website to Google Purchasing and various other 3rd party vendors is a key application of data scuffing for ecommerce.
What is the distinction between ditching and also crawling?
Web scratching purposes to remove the data on websites, as well as internet creeping purposes to index and also find web pages. Web crawling entails complying with web links permanently based upon links. In comparison, web scraping indicates creating a program computer that can stealthily accumulate data from several websites.
The web crawler can access just website permitted by the site. Web crawling is an extra nuanced and also intricate process as contrasted to information scratching. Scrapers do not have to stress over being courteous or complying with any type of moral guidelines. To resolve a single issue, companies can leverage numerous remedy classifications with numerous vendors in each classification. We bring transparency and also data-driven choice making to arising technology procurement of ventures. Utilize our vendor listings or research study posts to determine how modern technologies like AI/ artificial intelligence/ information science, IoT, process mining, RPA, artificial information can change your organization. Individual agents reduce the danger of being blocked while scuffing internet sites. " Crawling allows us to take disorganized, scattered data from several resources and also gather it in one area and also make it structured," says Marcin. " If you have actually numerous internet sites controlled by various entities, you can combine it all right into one feed. Data scraping and also data crawling relate techniques to make it perplexing for you. Yet after reviewing this article, we wish you'll be clear regarding the context, the factors of distinction, and the use of both. Data scuffing services can carry out tasks that are unable to be completed by software crawling tools, such as implementing javascript, sending data formats, resisting robotics, etc.
What is the distinction between information scraping as well as data crawling?
Data creeping is a wider procedure of systematically checking out as well as indexing information sources, while data scuffing is an extra particular procedure of drawing out targeted information from those sources. Both techniques can be made use of together to remove information from internet sites, databases, or various other sources.
Alexander Sinclair is an acclaimed author known for his captivating storytelling and imaginative literary works. With a passion for literature that began in his early childhood, he has dedicated his life to the written word, creating engaging narratives that transport readers to extraordinary worlds.
Professionally, Alexander is a seasoned journalist and investigative reporter. His background in journalism has honed his ability to research and delve deep into subjects, unraveling hidden truths and presenting them in a compelling and thought-provoking manner. This skillset naturally translates into his fiction writing, where he masterfully weaves together intricate plotlines and richly developed characters.
Beyond his writing career, Alexander is a curious soul with a wide range of hobbies and interests. A lover of nature, he finds solace in spending time outdoors, exploring forests, and observing the wonders of the natural world. This connection to nature often finds its way into...