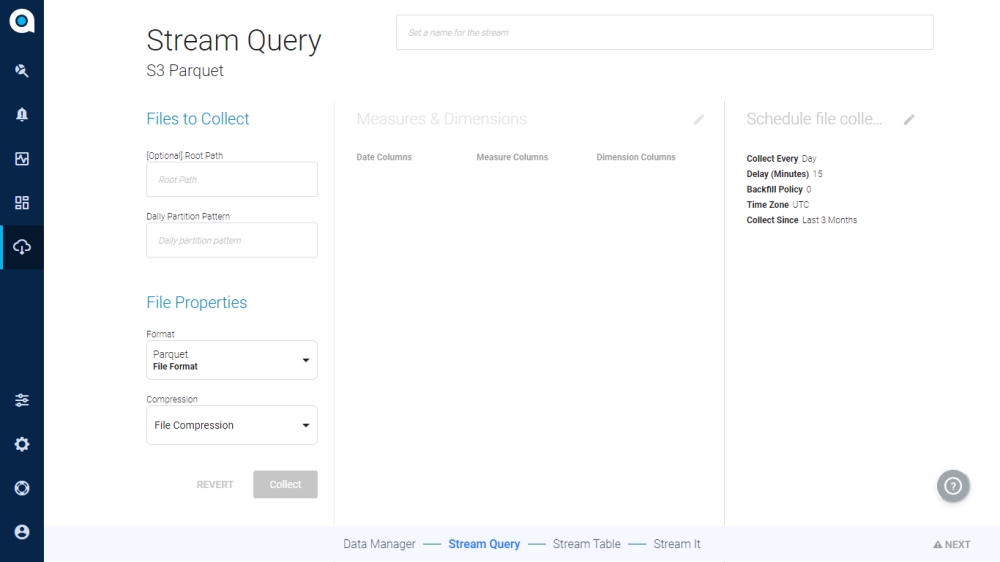
Amazon S3 Parquet . This makes it possible to. this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. an amazon s3 bucket with some parquet files in it. Create a spark session and connect to s3. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's advantages and how to 내 보낸 데이터를 amazon athena, amazon emr (spark) 및. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. The first step is to create a.
from support.anodot.com
you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. The first step is to create a. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's advantages and how to an amazon s3 bucket with some parquet files in it. this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. Create a spark session and connect to s3. 내 보낸 데이터를 amazon athena, amazon emr (spark) 및. This makes it possible to.
AWS S3 Parquet Collector Anodot
Amazon S3 Parquet this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's advantages and how to Create a spark session and connect to s3. This makes it possible to. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. The first step is to create a. an amazon s3 bucket with some parquet files in it. 내 보낸 데이터를 amazon athena, amazon emr (spark) 및.
From support.anodot.com
Amazon S3 Parquet Anodot Amazon S3 Parquet Create a spark session and connect to s3. This makes it possible to. this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. The first step is. Amazon S3 Parquet.
From webhookdb.com
Continuous Parquet Sync to Amazon S3 webhookdb Amazon S3 Parquet parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. an amazon s3 bucket with some parquet files in it. 내 보낸 데이터를 amazon athena, amazon emr (spark) 및. This makes it possible to. spark read from & write to parquet file | amazon s3 bucket in. Amazon S3 Parquet.
From www.youtube.com
AWS Glue Write Parquet With Partitions to AWS S3 YouTube Amazon S3 Parquet an amazon s3 bucket with some parquet files in it. you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's. Amazon S3 Parquet.
From www.propeldata.com
Amazon S3 Parquet Propel docs Amazon S3 Parquet 내 보낸 데이터를 amazon athena, amazon emr (spark) 및. This makes it possible to. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's advantages and how to this post shows how to incrementally load data from data sources in an amazon s3 data. Amazon S3 Parquet.
From www.datarow.io
Load Parquet file from Amazon S3 to Amazon Redshift Amazon S3 Parquet this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. Create a spark session and connect to s3. The first step is to create a. This makes. Amazon S3 Parquet.
From pipes.datavirtuality.com
How to load data from Amazon S3 to Parquet File Amazon S3 Parquet Create a spark session and connect to s3. This makes it possible to. an amazon s3 bucket with some parquet files in it. this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. spark read from & write to parquet file | amazon s3 bucket in. Amazon S3 Parquet.
From aws.amazon.com
AWS Lake Formation AWS Machine Learning Blog Amazon S3 Parquet you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. The first step is to create a. an amazon s3 bucket with some parquet files in it. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배. Amazon S3 Parquet.
From jirak.net
Amazon RDS 스냅샷, Parquet 포맷 기반 Amazon S3 내보내기 기능 출시 지락문화예술공작단 Amazon S3 Parquet The first step is to create a. Create a spark session and connect to s3. 내 보낸 데이터를 amazon athena, amazon emr (spark) 및. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. this post shows how to incrementally load data from data sources in an amazon. Amazon S3 Parquet.
From www.propeldata.com
How to set up an Amazon S3 Parquet Data Pool Propel docs Amazon S3 Parquet you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. Create a spark session and connect to s3. an amazon s3 bucket with some parquet files in it. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial,. Amazon S3 Parquet.
From support.anodot.com
Amazon S3 Parquet Anodot Amazon S3 Parquet this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. This makes it possible to. Create a spark session and connect to s3. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. you can use. Amazon S3 Parquet.
From aws.amazon.com
Amazon RDS 스냅샷, Parquet 포맷 기반 Amazon S3 내보내기 기능 출시 Amazon Amazon S3 Parquet This makes it possible to. an amazon s3 bucket with some parquet files in it. this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet. Amazon S3 Parquet.
From www.propeldata.com
How to set up an Amazon S3 Parquet Data Pool Propel docs Amazon S3 Parquet This makes it possible to. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's advantages and how to an amazon s3 bucket with some parquet files in it. The first step is to create a. this post shows how to incrementally load. Amazon S3 Parquet.
From aws.amazon.com
s3logsparquet 高效处理海量 S3 访问日志 亚马逊AWS官方博客 Amazon S3 Parquet Create a spark session and connect to s3. 내 보낸 데이터를 amazon athena, amazon emr (spark) 및. this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. an amazon s3 bucket with some parquet files in it. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데. Amazon S3 Parquet.
From docs.aws.amazon.com
Cree una canalización de servicios de ETL para cargar datos de forma Amazon S3 Parquet The first step is to create a. this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. Create a spark session and connect to s3. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache. Amazon S3 Parquet.
From www.propeldata.com
How to set up an Amazon S3 Parquet Data Pool Propel docs Amazon S3 Parquet you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. Create a spark session and connect to s3. The first step is to create a. 내 보낸 데이터를 amazon athena, amazon emr (spark) 및. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2. Amazon S3 Parquet.
From github.com
GitHub tintinthong/awss3parquet Amazon S3 Parquet This makes it possible to. you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. an amazon s3 bucket with some parquet files in it. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를. Amazon S3 Parquet.
From sparkbyexamples.com
Read and Write Parquet file from Amazon S3 Spark By {Examples} Amazon S3 Parquet an amazon s3 bucket with some parquet files in it. 내 보낸 데이터를 amazon athena, amazon emr (spark) 및. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. The first step is to create a. spark read from & write to parquet file | amazon s3. Amazon S3 Parquet.
From aws.amazon.com
s3logsparquet 高效处理海量 S3 访问日志 亚马逊AWS官方博客 Amazon S3 Parquet an amazon s3 bucket with some parquet files in it. The first step is to create a. you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. This makes it possible to. spark read from & write to parquet file | amazon s3 bucket. Amazon S3 Parquet.
From faun.dev
How to read the parquet file in data frame from AWS S3 Amazon S3 Parquet parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. The first step is to create a. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's advantages and how to This makes it. Amazon S3 Parquet.
From www.datarow.io
Load Parquet file from Amazon S3 to Amazon Redshift Amazon S3 Parquet This makes it possible to. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's advantages and how to The first step is to create a. an amazon s3 bucket with some parquet files in it. you can use aws glue to read. Amazon S3 Parquet.
From brandiscrafts.com
Aws S3 Parquet? The 15 New Answer Amazon S3 Parquet this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's advantages and how to parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는. Amazon S3 Parquet.
From aws.amazon.com
s3logsparquet 高效处理海量 S3 访问日志 亚马逊AWS官方博客 Amazon S3 Parquet parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. spark read from & write to parquet file | amazon s3 bucket in this. Amazon S3 Parquet.
From www.propeldata.com
How to set up an Amazon S3 Parquet Data Pool Propel docs Amazon S3 Parquet The first step is to create a. you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. This makes it possible to. spark read. Amazon S3 Parquet.
From github.com
GitHub redapt/pysparks3parquetexample This repo demonstrates how Amazon S3 Parquet Create a spark session and connect to s3. this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. This makes it possible to. The first step is to create a. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배. Amazon S3 Parquet.
From www.datarow.io
Load Parquet file from Amazon S3 to Amazon Redshift Amazon S3 Parquet 내 보낸 데이터를 amazon athena, amazon emr (spark) 및. you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's advantages and. Amazon S3 Parquet.
From stackoverflow.com
google cloud platform Amazon S3 parquet file Transferring to GCP Amazon S3 Parquet 내 보낸 데이터를 amazon athena, amazon emr (spark) 및. This makes it possible to. this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. The first step is to create a. an amazon s3 bucket with some parquet files in it. parquet 형식은 텍스트 형식에 비해. Amazon S3 Parquet.
From aws.amazon.com
s3logsparquet 高效处理海量 S3 访问日志 亚马逊AWS官方博客 Amazon S3 Parquet The first step is to create a. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. an amazon s3 bucket with some parquet files in. Amazon S3 Parquet.
From www.amazon.com
Jesus Hutson castillo's Shop Best Defender Case For Galaxy Amazon S3 Parquet This makes it possible to. you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's advantages and how to 내 보낸. Amazon S3 Parquet.
From support.anodot.com
AWS S3 Parquet Collector Anodot Amazon S3 Parquet this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더. Amazon S3 Parquet.
From www.tecracer.com
PushDownPredicates in Parquet and how to use them to reduce IOPS Amazon S3 Parquet spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's advantages and how to this post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. 내 보낸 데이터를 amazon athena, amazon emr (spark) 및.. Amazon S3 Parquet.
From stackoverflow.com
amazon s3 Spark write parquet job completed but have a long delay to Amazon S3 Parquet Create a spark session and connect to s3. 내 보낸 데이터를 amazon athena, amazon emr (spark) 및. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's advantages and how to you can use aws glue to read parquet files from amazon s3 and. Amazon S3 Parquet.
From www.propeldata.com
How to set up an Amazon S3 Parquet Data Pool Propel docs Amazon S3 Parquet you can use aws glue to read parquet files from amazon s3 and from streaming sources as well as write parquet files to. This makes it possible to. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. this post shows how to incrementally load data from. Amazon S3 Parquet.
From jirak.net
Amazon RDS 스냅샷, Parquet 포맷 기반 Amazon S3 내보내기 기능 출시 지락문화예술공작단 Amazon S3 Parquet parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. 내 보낸 데이터를 amazon athena, amazon emr (spark) 및. spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's advantages and how to . Amazon S3 Parquet.
From support.anodot.com
AWS S3 Parquet Collector Anodot Amazon S3 Parquet an amazon s3 bucket with some parquet files in it. Create a spark session and connect to s3. parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. 내 보낸 데이터를 amazon athena, amazon emr (spark) 및. This makes it possible to. you can use aws glue. Amazon S3 Parquet.
From www.propeldata.com
How to set up an Amazon S3 Parquet Data Pool Propel docs Amazon S3 Parquet spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it's advantages and how to parquet 형식은 텍스트 형식에 비해 amazon s3에서 내보내는 데 최대 2 배 더 빠르며 최대 6 배 적은 스토리지를 사용합니다. this post shows how to incrementally load data from. Amazon S3 Parquet.