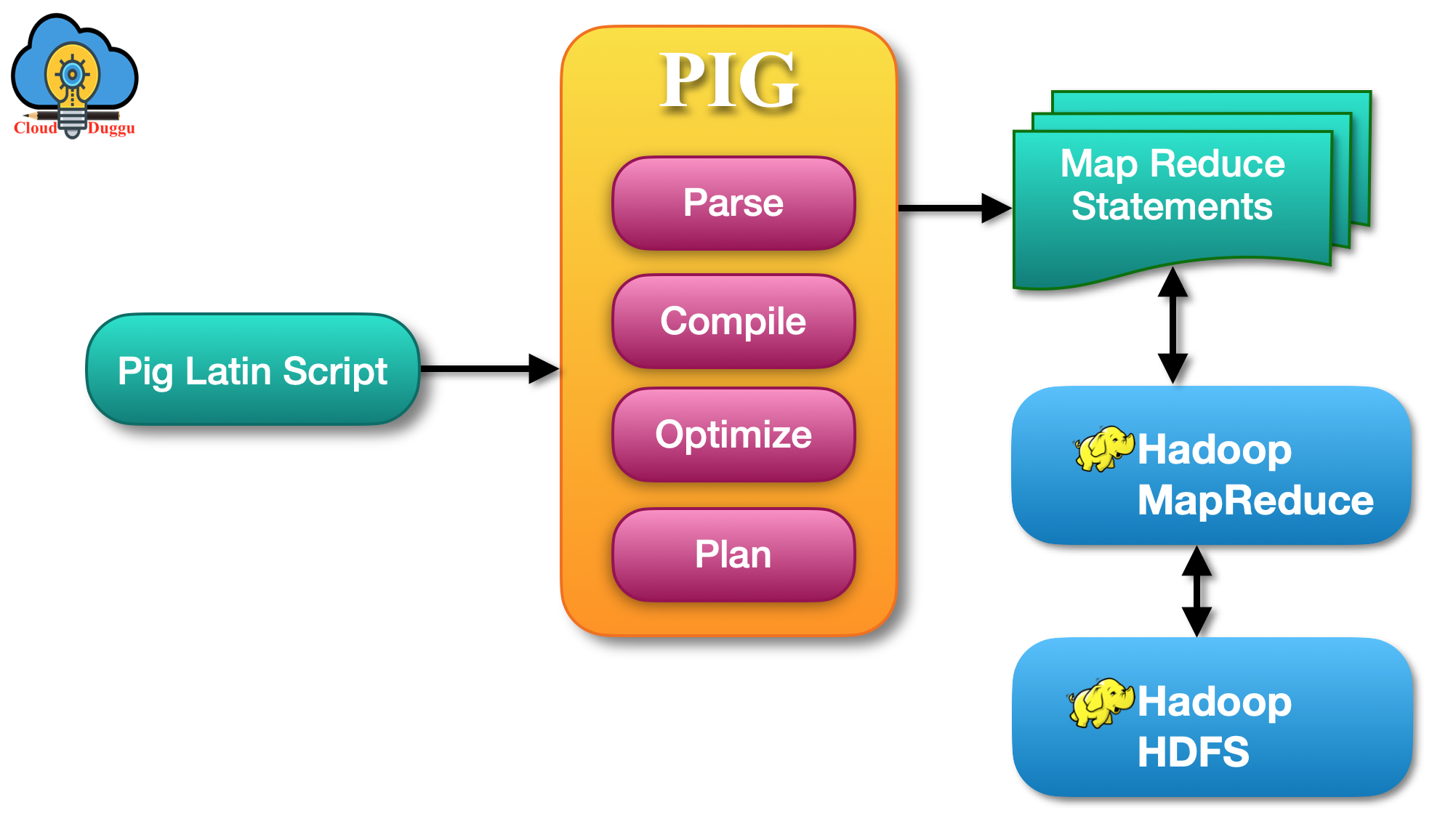
How Does Hadoop Work . Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. Learn how hadoop works as an open source framework for storing and processing large datasets in parallel across multiple computers. Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. Find out how to migrate from hadoop to the databricks. The client should submit the. It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers.
from www.cloudduggu.com
Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. Find out how to migrate from hadoop to the databricks. The client should submit the. It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. Learn how hadoop works as an open source framework for storing and processing large datasets in parallel across multiple computers. Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software.
Apache Hadoop Ecosystem Tutorial CloudDuggu
How Does Hadoop Work Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. The client should submit the. Find out how to migrate from hadoop to the databricks. It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. Learn how hadoop works as an open source framework for storing and processing large datasets in parallel across multiple computers. It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel.
From www.projectpro.io
Hadoop Explained How does Hadoop work and how to use it? How Does Hadoop Work It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. Find out how to migrate from hadoop to the databricks. The client should submit the. Learn how hadoop works as an open source framework for storing and processing large datasets in parallel across multiple computers. Learn. How Does Hadoop Work.
From data-flair.training
Hadoop Ecosystem and Their Components A Complete Tutorial DataFlair How Does Hadoop Work The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. Find out how to migrate from hadoop to the databricks. Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. The client should submit the. It enables organizations to. How Does Hadoop Work.
From data-flair.training
Hadoop RecordReader How RecordReader Works in Hadoop? DataFlair How Does Hadoop Work Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. Find out how to migrate from hadoop to the databricks. The client should submit the. It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. The. How Does Hadoop Work.
From techvidvan.com
Phases of MapReduce How Hadoop MapReduce Works TechVidvan How Does Hadoop Work Learn how hadoop works as an open source framework for storing and processing large datasets in parallel across multiple computers. The client should submit the. Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. The primary function of hadoop is to process the data in an organised manner among. How Does Hadoop Work.
From www.geeksforgeeks.org
Hadoop Architecture How Does Hadoop Work Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. The client should submit the. Find out how to migrate from hadoop to the databricks. It is designed to. How Does Hadoop Work.
From www.slideserve.com
PPT O’Reilly Hadoop The Definitive Guide Ch.6 How MapReduce Works How Does Hadoop Work Find out how to migrate from hadoop to the databricks. Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. The client should submit the. The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. Learn how hadoop works as. How Does Hadoop Work.
From www.codewithfaraz.com
Kerberos Authentication in Hadoop 2024 How It Works How Does Hadoop Work It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. Learn how hadoop works as an open source framework for storing and processing large datasets in parallel across multiple computers. Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. Apache hadoop. How Does Hadoop Work.
From www.youtube.com
How Does Hadoop Work? A Quick 3Minute Overview YouTube How Does Hadoop Work It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. Find out how to migrate from hadoop to the databricks. The primary function of hadoop is to process. How Does Hadoop Work.
From www.oreilly.com
7. How MapReduce Works Hadoop The Definitive Guide, 4th Edition [Book] How Does Hadoop Work Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. Find out how to migrate from hadoop to the databricks. Learn how hadoop works as an open source framework for storing and processing large datasets in parallel across multiple computers. The client should submit the. It is designed to handle. How Does Hadoop Work.
From trainings.internshala.com
What is Hadoop MapReduce? Stages, Applications, Examples, & More How Does Hadoop Work Find out how to migrate from hadoop to the databricks. The client should submit the. It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. Learn. How Does Hadoop Work.
From bradhedlund.com
Understanding Hadoop Clusters and the Network Brad Hedlund How Does Hadoop Work The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. The client should submit the. It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges,. How Does Hadoop Work.
From www.odinschool.com
Know Hadoop How Does Hadoop Work Find out how to migrate from hadoop to the databricks. Learn how hadoop works as an open source framework for storing and processing large datasets in parallel across multiple computers. The client should submit the. The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. Apache hadoop is an open. How Does Hadoop Work.
From blog.matthewrathbone.com
A Beginners Guide to Hadoop How Does Hadoop Work Find out how to migrate from hadoop to the databricks. Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. Learn how hadoop works as an open source framework for storing. How Does Hadoop Work.
From www.youtube.com
How Hadoop Works YouTube How Does Hadoop Work Find out how to migrate from hadoop to the databricks. Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. It is designed to handle big data and is. How Does Hadoop Work.
From www.cloudduggu.com
Apache Hadoop Ecosystem Tutorial CloudDuggu How Does Hadoop Work The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. Find out how to migrate from hadoop to the databricks. It is designed to handle big data and is. How Does Hadoop Work.
From samjay-complete.blogspot.com
Tech Universe Hadoop Basics Horizontal Scaling instead of Vertical How Does Hadoop Work It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. Learn how hadoop works as an open source framework for storing and processing large datasets in parallel across multiple computers. Find out how to migrate from hadoop to the databricks. The primary function of hadoop is. How Does Hadoop Work.
From data-flair.training
Hadoop Ecosystem and Their Components A Complete Tutorial DataFlair How Does Hadoop Work Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. Apache hadoop is an open source software framework that stores data in a distributed manner and. How Does Hadoop Work.
From phoenixnap.com
What is Hadoop? Apache Hadoop Big Data Processing How Does Hadoop Work Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. It is designed to handle big data and is based on the mapreduce programming model, which allows for the. How Does Hadoop Work.
From www.turing.com
Hadoop Ecosystem Tools for Big Data & Data Engineering How Does Hadoop Work It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. The client should submit the. The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. Find out how to migrate from hadoop to the databricks. Learn. How Does Hadoop Work.
From techvidvan.com
How Hadoop Works Understand the Working of Hadoop TechVidvan How Does Hadoop Work It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and. How Does Hadoop Work.
From www.connectioncafe.com
Hadoop Explained The Big Data Toolkit How Does Hadoop Work It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. Find out how to migrate from hadoop to the databricks. Learn how hadoop works as an open source framework for storing and processing large datasets in parallel across multiple computers. Apache hadoop is an open source software framework that stores data in. How Does Hadoop Work.
From bradhedlund.com
Understanding Hadoop Clusters and the Network How Does Hadoop Work The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. It. How Does Hadoop Work.
From data-flair.training
Hadoop MapReduce Tutorial A Complete Guide to Mapreduce DataFlair How Does Hadoop Work Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. The client should submit the. Learn how hadoop works as an open source framework for storing. How Does Hadoop Work.
From stlplaces.com
How Does Hadoop Reducer Work in 2024? How Does Hadoop Work Find out how to migrate from hadoop to the databricks. Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. Learn about hadoop, an open. How Does Hadoop Work.
From data-flair.training
How Hadoop MapReduce Works MapReduce Tutorial DataFlair How Does Hadoop Work Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. The client should submit the. It is designed to handle big data and is based on the mapreduce programming model,. How Does Hadoop Work.
From akceptor.blogspot.com
Hadoop Distributed File System (HDFS) IT short How Does Hadoop Work Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. Learn how hadoop works as an open source framework for storing and processing large datasets in parallel across multiple computers. It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. The. How Does Hadoop Work.
From jelvix.com
Spark vs Hadoop What to Choose to Process Big Data How Does Hadoop Work Find out how to migrate from hadoop to the databricks. Learn how hadoop works as an open source framework for storing and processing large datasets in parallel across multiple computers. The client should submit the. It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. Apache. How Does Hadoop Work.
From deepstash.com
What Is Hadoop & How Does It Work? Deepstash How Does Hadoop Work Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. It enables organizations to store and process large volumes of unstructured and structured data across clusters. How Does Hadoop Work.
From hoituso.com
Hadoop Architecture How Does Hadoop Work The client should submit the. It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. Find out how to migrate from hadoop to the databricks. The primary function of hadoop is to. How Does Hadoop Work.
From www.altexsoft.com
Apache Hadoop vs Spark Main Big Data Tools Explained How Does Hadoop Work It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. Learn how hadoop works as an open source framework for storing and processing large datasets in parallel across multiple computers. Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. Apache hadoop. How Does Hadoop Work.
From data-flair.training
How Hadoop Works Internally Inside Hadoop DataFlair How Does Hadoop Work It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. Learn how hadoop works as an open source framework for storing and processing large datasets in parallel across multiple computers. The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. Find out. How Does Hadoop Work.
From www.pluralsight.com
Understanding Hadoop's Distributed File System Pluralsight How Does Hadoop Work It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. The client should submit the. Apache hadoop is an open source software framework that stores data in a distributed manner and process. How Does Hadoop Work.
From www.youtube.com
Hadoop MapReduce Example MapReduce Programming Hadoop Tutorial For How Does Hadoop Work It is designed to handle big data and is based on the mapreduce programming model, which allows for the parallel processing of large datasets. The primary function of hadoop is to process the data in an organised manner among the cluster of commodity software. Apache hadoop is an open source software framework that stores data in a distributed manner and. How Does Hadoop Work.
From www.cloudduggu.com
Apache Hadoop Introduction Tutorial CloudDuggu How Does Hadoop Work Learn about hadoop, an open source platform for big data processing and storage, and its benefits, challenges, and use cases. Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. Find out how to migrate from hadoop to the databricks. The primary function of hadoop is to process the. How Does Hadoop Work.
From developbi.blogspot.com
DevelopBI Understanding Hadoop Clusters and the Network How Does Hadoop Work Find out how to migrate from hadoop to the databricks. Apache hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. It enables organizations to store and process large volumes of unstructured and structured data across clusters of computers. Learn how hadoop works as an open source framework for storing. How Does Hadoop Work.