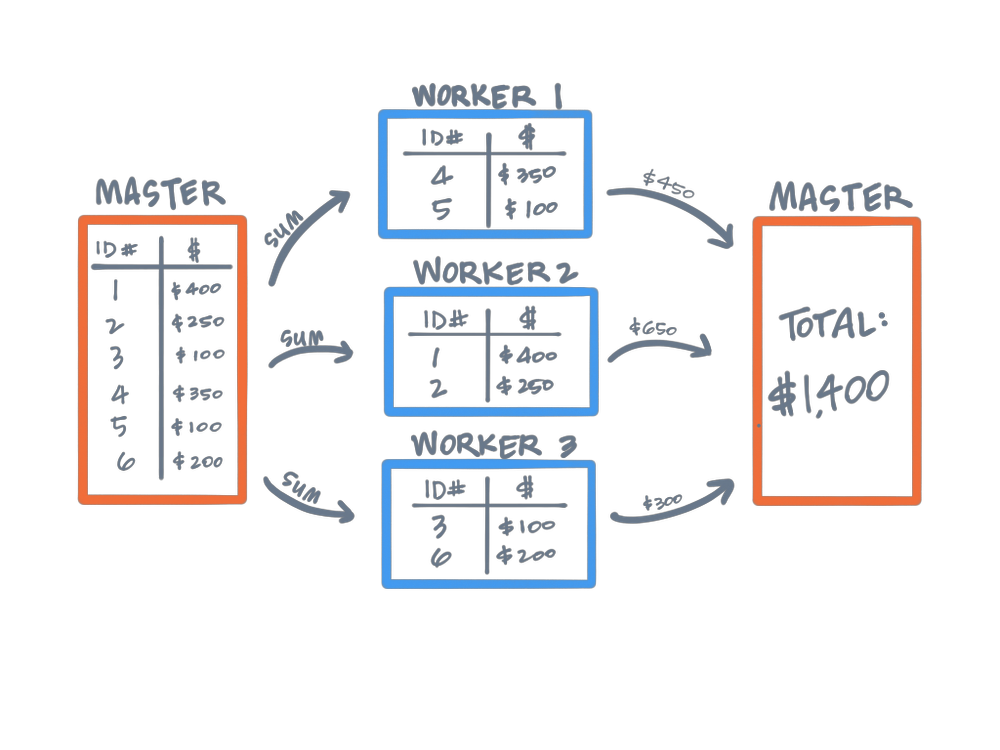
What Is Partitions In Spark . in the context of apache spark, it can be defined as a dividing the dataset into multiple parts across the cluster. partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. The main idea behind data partitioning is to optimise your job. In a distributed system like apache spark, it can be defined as a division of a dataset stored. When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. what is spark partitioning and how does it work? by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. simply put, partitions in spark are the smaller, manageable chunks of your big data. Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. what is spark partitioning ? Partitioning is nothing but dividing data structure into parts.
from www.jowanza.com
by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. in the context of apache spark, it can be defined as a dividing the dataset into multiple parts across the cluster. Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. In a distributed system like apache spark, it can be defined as a division of a dataset stored. The main idea behind data partitioning is to optimise your job. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. simply put, partitions in spark are the smaller, manageable chunks of your big data. what is spark partitioning and how does it work?
Partitions in Apache Spark — Jowanza Joseph
What Is Partitions In Spark what is spark partitioning and how does it work? what is spark partitioning and how does it work? partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. simply put, partitions in spark are the smaller, manageable chunks of your big data. what is spark partitioning ? When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. Partitioning is nothing but dividing data structure into parts. The main idea behind data partitioning is to optimise your job. In a distributed system like apache spark, it can be defined as a division of a dataset stored. Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. in the context of apache spark, it can be defined as a dividing the dataset into multiple parts across the cluster. by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of.
From www.youtube.com
Apache Spark Data Partitioning Example YouTube What Is Partitions In Spark Partitioning is nothing but dividing data structure into parts. The main idea behind data partitioning is to optimise your job. in the context of apache spark, it can be defined as a dividing the dataset into multiple parts across the cluster. When spark reads a dataset, be it from hdfs, a local file system, or any other data source,. What Is Partitions In Spark.
From izhangzhihao.github.io
Spark The Definitive Guide In Short — MyNotes What Is Partitions In Spark When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. The main idea behind data partitioning is to optimise your job. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. Partitioning is nothing but. What Is Partitions In Spark.
From medium.com
Spark Under The Hood Partition. Spark is a distributed computing What Is Partitions In Spark what is spark partitioning ? what is spark partitioning and how does it work? Partitioning is nothing but dividing data structure into parts. Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions.. What Is Partitions In Spark.
From www.dezyre.com
How Data Partitioning in Spark helps achieve more parallelism? What Is Partitions In Spark Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. simply put, partitions in spark are the smaller, manageable chunks of your big data. When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. . What Is Partitions In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo What Is Partitions In Spark spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. Partitioning is nothing but dividing data structure into parts. Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. simply put, partitions in spark are the smaller, manageable chunks of. What Is Partitions In Spark.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders What Is Partitions In Spark what is spark partitioning and how does it work? what is spark partitioning ? by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. simply put, partitions in spark are the smaller, manageable chunks of your big. What Is Partitions In Spark.
From dzone.com
Dynamic Partition Pruning in Spark 3.0 DZone What Is Partitions In Spark When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. what is spark partitioning and how does it work? in the context of apache spark, it can be defined as a dividing the dataset into multiple parts across the cluster. In a distributed. What Is Partitions In Spark.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna What Is Partitions In Spark what is spark partitioning and how does it work? spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. In a distributed system like apache spark, it can be defined as a division of a dataset stored. partitioning is the process of dividing a dataset into smaller, more. What Is Partitions In Spark.
From medium.com
Managing Partitions with Spark. If you ever wonder why everyone moved What Is Partitions In Spark by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. what is spark partitioning and how does it work? Partitioning is nothing but dividing data structure into parts. simply put, partitions in spark are the smaller, manageable chunks. What Is Partitions In Spark.
From www.ishandeshpande.com
Understanding Partitions in Apache Spark What Is Partitions In Spark Partitioning is nothing but dividing data structure into parts. in the context of apache spark, it can be defined as a dividing the dataset into multiple parts across the cluster. by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number. What Is Partitions In Spark.
From exocpydfk.blob.core.windows.net
What Is Shuffle Partitions In Spark at Joe Warren blog What Is Partitions In Spark spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. In a distributed system like apache spark, it can be defined as a division of. What Is Partitions In Spark.
From www.youtube.com
How to partition and write DataFrame in Spark without deleting What Is Partitions In Spark In a distributed system like apache spark, it can be defined as a division of a dataset stored. When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. The main idea behind data partitioning is to optimise your job. simply put, partitions in spark. What Is Partitions In Spark.
From medium.com
Spark Partitioning Partition Understanding Medium What Is Partitions In Spark Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. what is spark partitioning and how does it work? spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. Partitioning is nothing but dividing data structure into parts. When spark. What Is Partitions In Spark.
From sparkbyexamples.com
Get the Size of Each Spark Partition Spark By {Examples} What Is Partitions In Spark spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but. What Is Partitions In Spark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames What Is Partitions In Spark simply put, partitions in spark are the smaller, manageable chunks of your big data. Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. by default, spark creates one. What Is Partitions In Spark.
From nebash.com
What's new in Apache Spark 3.0 dynamic partition pruning (2023) What Is Partitions In Spark spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. Partitioning is nothing but dividing data structure into parts. The main idea behind data partitioning is to optimise your job. what is spark partitioning ? what is spark partitioning and how does it work? by default, spark. What Is Partitions In Spark.
From spaziocodice.com
Spark SQL Partitions and Sizes SpazioCodice What Is Partitions In Spark In a distributed system like apache spark, it can be defined as a division of a dataset stored. simply put, partitions in spark are the smaller, manageable chunks of your big data. in the context of apache spark, it can be defined as a dividing the dataset into multiple parts across the cluster. by default, spark creates. What Is Partitions In Spark.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions What Is Partitions In Spark what is spark partitioning and how does it work? by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. . What Is Partitions In Spark.
From techvidvan.com
Apache Spark Partitioning and Spark Partition TechVidvan What Is Partitions In Spark partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. in the context of apache spark, it can be defined as a dividing the dataset into multiple parts across the cluster. Partitioning is nothing but dividing data structure into parts. When spark reads a dataset, be it from hdfs, a local file system,. What Is Partitions In Spark.
From andr83.io
How to work with Hive tables with a lot of partitions from Spark What Is Partitions In Spark Partitioning is nothing but dividing data structure into parts. by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. simply. What Is Partitions In Spark.
From exocpydfk.blob.core.windows.net
What Is Shuffle Partitions In Spark at Joe Warren blog What Is Partitions In Spark spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. The main idea behind data partitioning is to optimise your job. what is spark partitioning ? partitioning is the. What Is Partitions In Spark.
From dzone.com
Dynamic Partition Pruning in Spark 3.0 DZone What Is Partitions In Spark partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. in the context of apache spark, it can be defined as a dividing. What Is Partitions In Spark.
From towardsdata.dev
Partitions and Bucketing in Spark towards data What Is Partitions In Spark Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. The main idea behind data partitioning is to optimise your job. partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. When spark reads a dataset, be it from hdfs, a local file system, or. What Is Partitions In Spark.
From sparkbyexamples.com
Spark Partitioning & Partition Understanding Spark By {Examples} What Is Partitions In Spark what is spark partitioning ? In a distributed system like apache spark, it can be defined as a division of a dataset stored. Partitioning is nothing but dividing data structure into parts. by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a. What Is Partitions In Spark.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions What Is Partitions In Spark by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. in the context of apache spark, it can be defined as a dividing the dataset into multiple parts across the cluster. spark/pyspark partitioning is a way to split. What Is Partitions In Spark.
From www.youtube.com
Why should we partition the data in spark? YouTube What Is Partitions In Spark by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. partitioning is the process of dividing a dataset into. What Is Partitions In Spark.
From 0x0fff.com
Spark Architecture Shuffle Distributed Systems Architecture What Is Partitions In Spark what is spark partitioning ? simply put, partitions in spark are the smaller, manageable chunks of your big data. in the context of apache spark, it can be defined as a dividing the dataset into multiple parts across the cluster. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can. What Is Partitions In Spark.
From www.youtube.com
Apache Spark Dynamic Partition Pruning Spark Tutorial Part 11 YouTube What Is Partitions In Spark partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. simply put, partitions in spark are the smaller, manageable chunks of your big data. by default, spark. What Is Partitions In Spark.
From exokeufcv.blob.core.windows.net
Max Number Of Partitions In Spark at Manda Salazar blog What Is Partitions In Spark what is spark partitioning and how does it work? The main idea behind data partitioning is to optimise your job. In a distributed system like apache spark, it can be defined as a division of a dataset stored. what is spark partitioning ? Spark partitioning is a way to divide and distribute data into multiple partitions to achieve. What Is Partitions In Spark.
From www.youtube.com
Spark Application Partition By in Spark Chapter 2 LearntoSpark What Is Partitions In Spark In a distributed system like apache spark, it can be defined as a division of a dataset stored. what is spark partitioning ? When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. simply put, partitions in spark are the smaller, manageable chunks. What Is Partitions In Spark.
From sparkbyexamples.com
Spark Get Current Number of Partitions of DataFrame Spark By {Examples} What Is Partitions In Spark what is spark partitioning and how does it work? by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Partitioning is nothing but dividing data structure into parts. simply put, partitions in spark are the smaller, manageable chunks. What Is Partitions In Spark.
From www.jowanza.com
Partitions in Apache Spark — Jowanza Joseph What Is Partitions In Spark what is spark partitioning and how does it work? spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. Partitioning is nothing but dividing. What Is Partitions In Spark.
From medium.com
Managing Spark Partitions. How data is partitioned and when do you What Is Partitions In Spark simply put, partitions in spark are the smaller, manageable chunks of your big data. When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. Partitioning is nothing but. What Is Partitions In Spark.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient What Is Partitions In Spark by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. In a distributed system like apache spark, it can be defined as a division of a dataset stored. in the context of apache spark, it can be defined as. What Is Partitions In Spark.
From techvidvan.com
Apache Spark Partitioning and Spark Partition TechVidvan What Is Partitions In Spark what is spark partitioning and how does it work? Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. what is spark partitioning ? The main idea behind data. What Is Partitions In Spark.