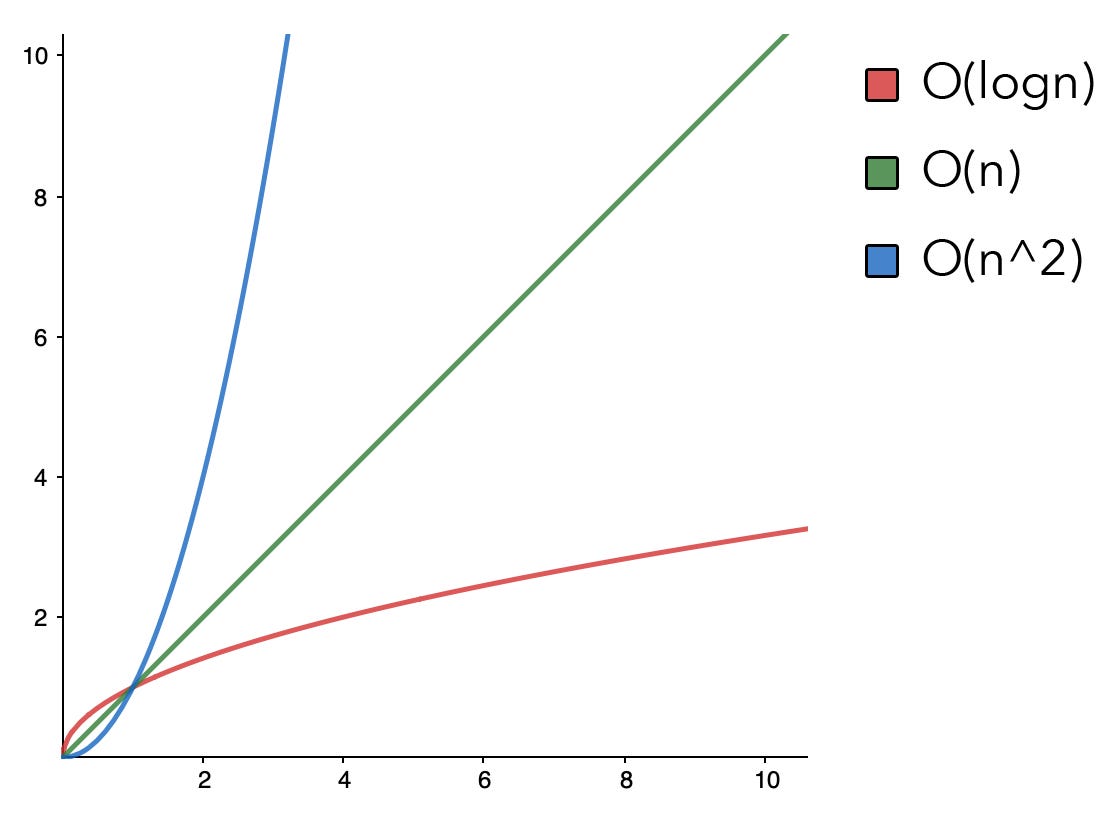
Is N Log N Greater Than N . If we assume n ≥ 1 n ≥ 1, we have log n ≥ 1 log n ≥ 1. Logarithmic time complexity is denoted as o(log n). O(1) means the running time of an algorithm is independent of the input size and is bounded by. When using data structures, if one more element is needed every time n increases by one, then the algorithm will use o (n) space. $\log n$ is the inverse of $2^n$. O (nlogn) is known as loglinear complexity. With that we have log2. To understand this let us. It is a measure of how the runtime of an algorithm scales as the input size. Just as $2^n$ grows faster than any polynomial $n^k$ regardless of how large a finite $k$ is, $\log n$ will grow slower than any polynomial functions $n^k$. Yes, there is a huge difference. To demonstrate with a counterexample, let $f(n) = 10^{100} \log n$ (an $o(\log n)$ algorithm; Is o(1) always faster than o(log n)? Regarding your follow up question: Thus, binary search o(log(n)) and heapsort o(n log(n)) are efficient algorithms, while linear search o(n) and bubblesort o(n²).
from medium.com
Yes, there is a huge difference. When using data structures, if one more element is needed every time n increases by one, then the algorithm will use o (n) space. One thing to understand about n*log (n) is that it is relatively close to a linear complexity of o (n). With that we have log2. O (nlogn) is known as loglinear complexity. $\log n$ is the inverse of $2^n$. It is a measure of how the runtime of an algorithm scales as the input size. To understand this let us. O(1) means the running time of an algorithm is independent of the input size and is bounded by. Regarding your follow up question:
What is O(n)? — Big O Notation + How to use it by Timo Makhlay Medium
Is N Log N Greater Than N O (nlogn) is known as loglinear complexity. Logarithmic time complexity is denoted as o(log n). Is o(1) always faster than o(log n)? O (nlogn) is known as loglinear complexity. With that we have log2. To understand this let us. If we assume n ≥ 1 n ≥ 1, we have log n ≥ 1 log n ≥ 1. Regarding your follow up question: One thing to understand about n*log (n) is that it is relatively close to a linear complexity of o (n). O(1) means the running time of an algorithm is independent of the input size and is bounded by. Thus, binary search o(log(n)) and heapsort o(n log(n)) are efficient algorithms, while linear search o(n) and bubblesort o(n²). Just as $2^n$ grows faster than any polynomial $n^k$ regardless of how large a finite $k$ is, $\log n$ will grow slower than any polynomial functions $n^k$. To demonstrate with a counterexample, let $f(n) = 10^{100} \log n$ (an $o(\log n)$ algorithm; It is a measure of how the runtime of an algorithm scales as the input size. Yes, there is a huge difference. $\log n$ is the inverse of $2^n$.
From leetcode.com
Why is O(n log n) solution faster than O(n) ? LeetCode Discuss Is N Log N Greater Than N When using data structures, if one more element is needed every time n increases by one, then the algorithm will use o (n) space. If we assume n ≥ 1 n ≥ 1, we have log n ≥ 1 log n ≥ 1. Logarithmic time complexity is denoted as o(log n). O(1) means the running time of an algorithm is. Is N Log N Greater Than N.
From www.youtube.com
An Exact Formula for the Primes Willans' Formula YouTube Is N Log N Greater Than N Is o(1) always faster than o(log n)? $\log n$ is the inverse of $2^n$. When using data structures, if one more element is needed every time n increases by one, then the algorithm will use o (n) space. O (nlogn) is known as loglinear complexity. One thing to understand about n*log (n) is that it is relatively close to a. Is N Log N Greater Than N.
From www.slideserve.com
PPT The Lower Bounds of Problems PowerPoint Presentation, free Is N Log N Greater Than N Logarithmic time complexity is denoted as o(log n). Thus, binary search o(log(n)) and heapsort o(n log(n)) are efficient algorithms, while linear search o(n) and bubblesort o(n²). O (nlogn) is known as loglinear complexity. Is o(1) always faster than o(log n)? O(1) means the running time of an algorithm is independent of the input size and is bounded by. With that. Is N Log N Greater Than N.
From www.youtube.com
15 proof prove induction 2^n is greater than or equal to 1+n Is N Log N Greater Than N One thing to understand about n*log (n) is that it is relatively close to a linear complexity of o (n). Is o(1) always faster than o(log n)? With that we have log2. Logarithmic time complexity is denoted as o(log n). O (nlogn) is known as loglinear complexity. Thus, binary search o(log(n)) and heapsort o(n log(n)) are efficient algorithms, while linear. Is N Log N Greater Than N.
From 9to5answer.com
[Solved] Is O(n) greater than O(2^log n) 9to5Answer Is N Log N Greater Than N When using data structures, if one more element is needed every time n increases by one, then the algorithm will use o (n) space. If we assume n ≥ 1 n ≥ 1, we have log n ≥ 1 log n ≥ 1. Is o(1) always faster than o(log n)? To demonstrate with a counterexample, let $f(n) = 10^{100} \log. Is N Log N Greater Than N.
From science.slc.edu
Running Time Graphs Is N Log N Greater Than N Thus, binary search o(log(n)) and heapsort o(n log(n)) are efficient algorithms, while linear search o(n) and bubblesort o(n²). When using data structures, if one more element is needed every time n increases by one, then the algorithm will use o (n) space. To demonstrate with a counterexample, let $f(n) = 10^{100} \log n$ (an $o(\log n)$ algorithm; One thing to. Is N Log N Greater Than N.
From www.chegg.com
Solved Determine complexities of the following functions Is N Log N Greater Than N O (nlogn) is known as loglinear complexity. O(1) means the running time of an algorithm is independent of the input size and is bounded by. If we assume n ≥ 1 n ≥ 1, we have log n ≥ 1 log n ≥ 1. One thing to understand about n*log (n) is that it is relatively close to a linear. Is N Log N Greater Than N.
From buildersaceto.weebly.com
Derivative of log n buildersaceto Is N Log N Greater Than N To demonstrate with a counterexample, let $f(n) = 10^{100} \log n$ (an $o(\log n)$ algorithm; Thus, binary search o(log(n)) and heapsort o(n log(n)) are efficient algorithms, while linear search o(n) and bubblesort o(n²). Logarithmic time complexity is denoted as o(log n). Regarding your follow up question: O (nlogn) is known as loglinear complexity. Just as $2^n$ grows faster than any. Is N Log N Greater Than N.
From www.chegg.com
Solved 1. Is the series 1 Σ n(log n) n=2 convergent or Is N Log N Greater Than N O (nlogn) is known as loglinear complexity. It is a measure of how the runtime of an algorithm scales as the input size. With that we have log2. Is o(1) always faster than o(log n)? Yes, there is a huge difference. O(1) means the running time of an algorithm is independent of the input size and is bounded by. One. Is N Log N Greater Than N.
From www.youtube.com
Write each of the following expressions as log N YouTube Is N Log N Greater Than N Logarithmic time complexity is denoted as o(log n). If we assume n ≥ 1 n ≥ 1, we have log n ≥ 1 log n ≥ 1. It is a measure of how the runtime of an algorithm scales as the input size. Yes, there is a huge difference. Just as $2^n$ grows faster than any polynomial $n^k$ regardless of. Is N Log N Greater Than N.
From learn2torials.com
Part5 Logarithmic Time Complexity O(log n) Is N Log N Greater Than N Yes, there is a huge difference. Logarithmic time complexity is denoted as o(log n). Regarding your follow up question: It is a measure of how the runtime of an algorithm scales as the input size. To demonstrate with a counterexample, let $f(n) = 10^{100} \log n$ (an $o(\log n)$ algorithm; O (nlogn) is known as loglinear complexity. When using data. Is N Log N Greater Than N.
From www.slideserve.com
PPT Finding the Largest Area AxisParallel Rectangle in a Polygon in Is N Log N Greater Than N Yes, there is a huge difference. When using data structures, if one more element is needed every time n increases by one, then the algorithm will use o (n) space. With that we have log2. It is a measure of how the runtime of an algorithm scales as the input size. Is o(1) always faster than o(log n)? If we. Is N Log N Greater Than N.
From www.chegg.com
Problem 4 . Let sequence An be 2n^3 + n^2 log n (n Is N Log N Greater Than N O (nlogn) is known as loglinear complexity. O(1) means the running time of an algorithm is independent of the input size and is bounded by. $\log n$ is the inverse of $2^n$. Is o(1) always faster than o(log n)? When using data structures, if one more element is needed every time n increases by one, then the algorithm will use. Is N Log N Greater Than N.
From www.chegg.com
Solved Short Answer (5) Order the following growth rates Is N Log N Greater Than N With that we have log2. When using data structures, if one more element is needed every time n increases by one, then the algorithm will use o (n) space. Regarding your follow up question: O(1) means the running time of an algorithm is independent of the input size and is bounded by. Just as $2^n$ grows faster than any polynomial. Is N Log N Greater Than N.
From big-o.io
Algorithms with an average case performance of O(n log (n)) BigO Is N Log N Greater Than N One thing to understand about n*log (n) is that it is relatively close to a linear complexity of o (n). With that we have log2. $\log n$ is the inverse of $2^n$. O(1) means the running time of an algorithm is independent of the input size and is bounded by. Is o(1) always faster than o(log n)? It is a. Is N Log N Greater Than N.
From saylordotorg.github.io
Logarithmic Functions and Their Graphs Is N Log N Greater Than N O (nlogn) is known as loglinear complexity. To demonstrate with a counterexample, let $f(n) = 10^{100} \log n$ (an $o(\log n)$ algorithm; Yes, there is a huge difference. Logarithmic time complexity is denoted as o(log n). If we assume n ≥ 1 n ≥ 1, we have log n ≥ 1 log n ≥ 1. With that we have log2.. Is N Log N Greater Than N.
From medium.com
Time Complexity A Simple Explanation (with Code Examples) by Brahim Is N Log N Greater Than N Thus, binary search o(log(n)) and heapsort o(n log(n)) are efficient algorithms, while linear search o(n) and bubblesort o(n²). Is o(1) always faster than o(log n)? It is a measure of how the runtime of an algorithm scales as the input size. With that we have log2. One thing to understand about n*log (n) is that it is relatively close to. Is N Log N Greater Than N.
From www.chegg.com
Solved We write logº n to denote (log n)" (i.e., log n Is N Log N Greater Than N Thus, binary search o(log(n)) and heapsort o(n log(n)) are efficient algorithms, while linear search o(n) and bubblesort o(n²). When using data structures, if one more element is needed every time n increases by one, then the algorithm will use o (n) space. If we assume n ≥ 1 n ≥ 1, we have log n ≥ 1 log n ≥. Is N Log N Greater Than N.
From saylordotorg.github.io
Logarithmic Functions and Their Graphs Is N Log N Greater Than N Just as $2^n$ grows faster than any polynomial $n^k$ regardless of how large a finite $k$ is, $\log n$ will grow slower than any polynomial functions $n^k$. O (nlogn) is known as loglinear complexity. It is a measure of how the runtime of an algorithm scales as the input size. When using data structures, if one more element is needed. Is N Log N Greater Than N.
From www.quora.com
Does exp (log n) grow faster than n? Quora Is N Log N Greater Than N Regarding your follow up question: To demonstrate with a counterexample, let $f(n) = 10^{100} \log n$ (an $o(\log n)$ algorithm; It is a measure of how the runtime of an algorithm scales as the input size. O (nlogn) is known as loglinear complexity. To understand this let us. Logarithmic time complexity is denoted as o(log n). One thing to understand. Is N Log N Greater Than N.
From www.youtube.com
Prove that 2^n is greater than n for all positive integers n Is N Log N Greater Than N O(1) means the running time of an algorithm is independent of the input size and is bounded by. One thing to understand about n*log (n) is that it is relatively close to a linear complexity of o (n). O (nlogn) is known as loglinear complexity. When using data structures, if one more element is needed every time n increases by. Is N Log N Greater Than N.
From markettay.com
Dlaczego sortowanie jest O(N log N) The Art of Machinery Market tay Is N Log N Greater Than N It is a measure of how the runtime of an algorithm scales as the input size. To understand this let us. Is o(1) always faster than o(log n)? Regarding your follow up question: O (nlogn) is known as loglinear complexity. With that we have log2. One thing to understand about n*log (n) is that it is relatively close to a. Is N Log N Greater Than N.
From www.numerade.com
SOLVEDShow that log n ! is greater than (n logn) / 4 for n>4. [Hint Is N Log N Greater Than N Yes, there is a huge difference. It is a measure of how the runtime of an algorithm scales as the input size. To understand this let us. Just as $2^n$ grows faster than any polynomial $n^k$ regardless of how large a finite $k$ is, $\log n$ will grow slower than any polynomial functions $n^k$. When using data structures, if one. Is N Log N Greater Than N.
From plot.ly
logn, 2logn, nlogn, 2nlogn, n(logn)^2, 2n(logn)^2, n log(logn), 2n log Is N Log N Greater Than N If we assume n ≥ 1 n ≥ 1, we have log n ≥ 1 log n ≥ 1. One thing to understand about n*log (n) is that it is relatively close to a linear complexity of o (n). It is a measure of how the runtime of an algorithm scales as the input size. O (nlogn) is known as. Is N Log N Greater Than N.
From www.youtube.com
Convergence of the series (1/(log n)^(log n )) YouTube Is N Log N Greater Than N Just as $2^n$ grows faster than any polynomial $n^k$ regardless of how large a finite $k$ is, $\log n$ will grow slower than any polynomial functions $n^k$. O(1) means the running time of an algorithm is independent of the input size and is bounded by. Is o(1) always faster than o(log n)? If we assume n ≥ 1 n ≥. Is N Log N Greater Than N.
From www.slideserve.com
PPT Sorting PowerPoint Presentation, free download ID1112947 Is N Log N Greater Than N To demonstrate with a counterexample, let $f(n) = 10^{100} \log n$ (an $o(\log n)$ algorithm; Yes, there is a huge difference. To understand this let us. It is a measure of how the runtime of an algorithm scales as the input size. One thing to understand about n*log (n) is that it is relatively close to a linear complexity of. Is N Log N Greater Than N.
From www.chilimath.com
Logarithm Rules ChiliMath Is N Log N Greater Than N When using data structures, if one more element is needed every time n increases by one, then the algorithm will use o (n) space. Thus, binary search o(log(n)) and heapsort o(n log(n)) are efficient algorithms, while linear search o(n) and bubblesort o(n²). Just as $2^n$ grows faster than any polynomial $n^k$ regardless of how large a finite $k$ is, $\log. Is N Log N Greater Than N.
From www.chegg.com
Solved f(n) = n^(1/log n), and g(n) = log (n). (Since the Is N Log N Greater Than N $\log n$ is the inverse of $2^n$. O (nlogn) is known as loglinear complexity. Thus, binary search o(log(n)) and heapsort o(n log(n)) are efficient algorithms, while linear search o(n) and bubblesort o(n²). Regarding your follow up question: Is o(1) always faster than o(log n)? To demonstrate with a counterexample, let $f(n) = 10^{100} \log n$ (an $o(\log n)$ algorithm; With. Is N Log N Greater Than N.
From medium.com
What is O(n)? — Big O Notation + How to use it by Timo Makhlay Medium Is N Log N Greater Than N Yes, there is a huge difference. Logarithmic time complexity is denoted as o(log n). Regarding your follow up question: O (nlogn) is known as loglinear complexity. When using data structures, if one more element is needed every time n increases by one, then the algorithm will use o (n) space. If we assume n ≥ 1 n ≥ 1, we. Is N Log N Greater Than N.
From www.chegg.com
Solved 1. Prove or disprove the following statements (ii) Is N Log N Greater Than N O (nlogn) is known as loglinear complexity. Just as $2^n$ grows faster than any polynomial $n^k$ regardless of how large a finite $k$ is, $\log n$ will grow slower than any polynomial functions $n^k$. If we assume n ≥ 1 n ≥ 1, we have log n ≥ 1 log n ≥ 1. To understand this let us. It is. Is N Log N Greater Than N.
From www.youtube.com
Proof 2^n is Greater than n^2 YouTube Is N Log N Greater Than N Just as $2^n$ grows faster than any polynomial $n^k$ regardless of how large a finite $k$ is, $\log n$ will grow slower than any polynomial functions $n^k$. If we assume n ≥ 1 n ≥ 1, we have log n ≥ 1 log n ≥ 1. Thus, binary search o(log(n)) and heapsort o(n log(n)) are efficient algorithms, while linear search. Is N Log N Greater Than N.
From science.slc.edu
Running Time Graphs Is N Log N Greater Than N Thus, binary search o(log(n)) and heapsort o(n log(n)) are efficient algorithms, while linear search o(n) and bubblesort o(n²). Is o(1) always faster than o(log n)? Logarithmic time complexity is denoted as o(log n). To demonstrate with a counterexample, let $f(n) = 10^{100} \log n$ (an $o(\log n)$ algorithm; When using data structures, if one more element is needed every time. Is N Log N Greater Than N.
From velog.io
Algorithm(빅오 표기법BigO Notation) Is N Log N Greater Than N To understand this let us. To demonstrate with a counterexample, let $f(n) = 10^{100} \log n$ (an $o(\log n)$ algorithm; Is o(1) always faster than o(log n)? Logarithmic time complexity is denoted as o(log n). Thus, binary search o(log(n)) and heapsort o(n log(n)) are efficient algorithms, while linear search o(n) and bubblesort o(n²). One thing to understand about n*log (n). Is N Log N Greater Than N.
From www.youtube.com
Why is Comparison Sorting Ω(n*log(n))? Asymptotic Bounding & Time Is N Log N Greater Than N When using data structures, if one more element is needed every time n increases by one, then the algorithm will use o (n) space. $\log n$ is the inverse of $2^n$. Thus, binary search o(log(n)) and heapsort o(n log(n)) are efficient algorithms, while linear search o(n) and bubblesort o(n²). Regarding your follow up question: O(1) means the running time of. Is N Log N Greater Than N.
From learn2torials.com
Part5 Logarithmic Time Complexity O(log n) Is N Log N Greater Than N O(1) means the running time of an algorithm is independent of the input size and is bounded by. It is a measure of how the runtime of an algorithm scales as the input size. One thing to understand about n*log (n) is that it is relatively close to a linear complexity of o (n). Just as $2^n$ grows faster than. Is N Log N Greater Than N.