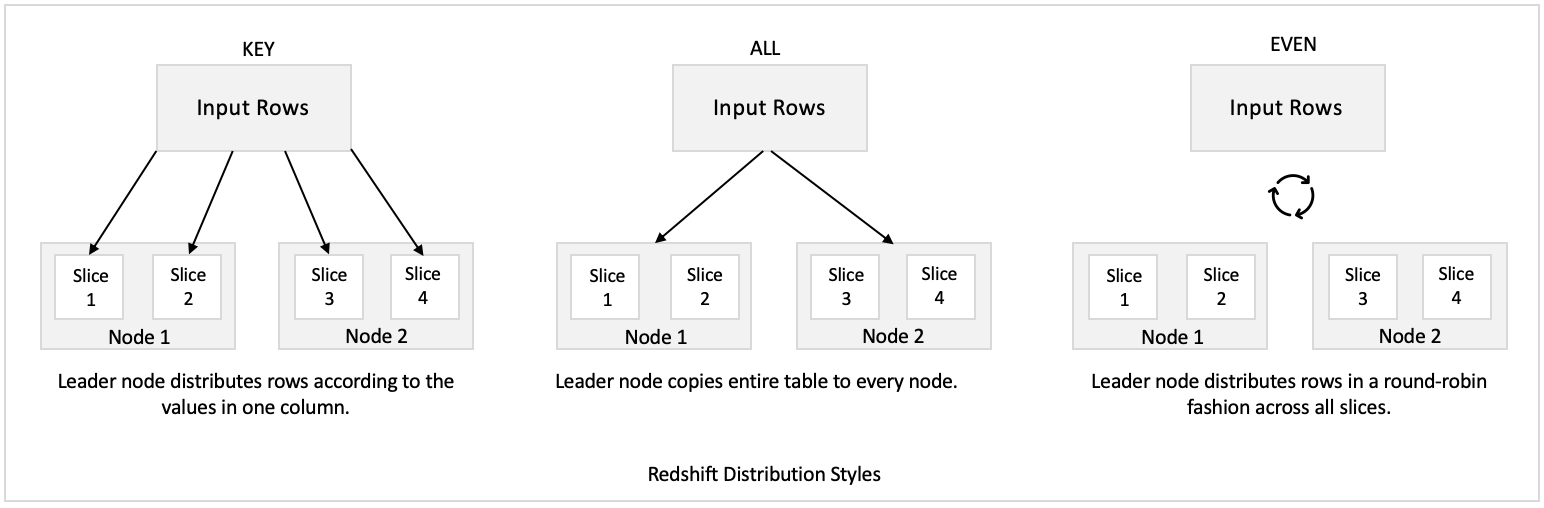
Partition Key Redshift . Key requires a single column to be defined as a distkey. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. If you don't specify a distribution style,. Auto, even, key, or all. On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice consistently. According to this page, you can partition data in redshift spectrum by a key which is based on the source s3 folder where your. When you create a table, you can designate one of the following distribution styles: When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file' } a clause that sets.
from klayplaqu.blob.core.windows.net
When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. When you create a table, you can designate one of the following distribution styles: Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. If you don't specify a distribution style,. Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file' } a clause that sets. Auto, even, key, or all. According to this page, you can partition data in redshift spectrum by a key which is based on the source s3 folder where your. Key requires a single column to be defined as a distkey. On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice consistently.
How To Change Sort Key In Redshift at Vincent Hammons blog
Partition Key Redshift Key requires a single column to be defined as a distkey. Key requires a single column to be defined as a distkey. Auto, even, key, or all. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. If you don't specify a distribution style,. Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. According to this page, you can partition data in redshift spectrum by a key which is based on the source s3 folder where your. Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file' } a clause that sets. When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. When you create a table, you can designate one of the following distribution styles: On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice consistently.
From docs.aws.amazon.com
Partitions and data distribution Amazon DynamoDB Partition Key Redshift On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice consistently. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. If you don't specify a distribution style,. When you create a table, you can designate one of the following distribution styles: When you load data. Partition Key Redshift.
From cezqrctw.blob.core.windows.net
Multiple Partition Key Dynamodb at Jason Lowry blog Partition Key Redshift Auto, even, key, or all. On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice consistently. When you create a table, you can designate one of the following distribution styles: According to this page, you can partition data in redshift spectrum by a key which is based on the source s3 folder where your.. Partition Key Redshift.
From www.youtube.com
24 Implementing Dist key and Sort key in Redshift YouTube Partition Key Redshift Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file' } a clause that sets. Auto, even, key, or all. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice consistently. When you load data into a. Partition Key Redshift.
From www.yugabyte.com
Distributed SQL Sharding and Partitioning YugabyteDB Partition Key Redshift If you don't specify a distribution style,. Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. When. Partition Key Redshift.
From aws.amazon.com
Migrate Google BigQuery to Amazon Redshift using AWS Schema Conversion Partition Key Redshift Auto, even, key, or all. According to this page, you can partition data in redshift spectrum by a key which is based on the source s3 folder where your. Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. When you load data into. Partition Key Redshift.
From aws.plainenglish.io
Partitioning in AWS Redshift A Guide to Boosting Performance by Partition Key Redshift According to this page, you can partition data in redshift spectrum by a key which is based on the source s3 folder where your. Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file' } a clause that sets. If you don't specify a distribution style,. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically. Partition Key Redshift.
From in.pinterest.com
How Redshift distributes Table Data and Importance of right Partition Key Redshift When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. According to this page, you can partition data in redshift spectrum by a key which is. Partition Key Redshift.
From www.blazeclan.com
Amazon Redshift 11 Key Points to Remember Blazeclan Partition Key Redshift Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file' } a clause that sets. When you create a table, you can designate one of the following distribution styles: On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice consistently. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically. Partition Key Redshift.
From noise.getoto.net
Migrate Google BigQuery to Amazon Redshift using AWS Schema Conversion Partition Key Redshift Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. When you create a table, you can designate one of the following distribution styles: According to this page, you can partition data in redshift spectrum by a key which is based on the source. Partition Key Redshift.
From github.com
Redshift Spectrum to Delta Lake integration using manifest files (an Partition Key Redshift Auto, even, key, or all. According to this page, you can partition data in redshift spectrum by a key which is based on the source s3 folder where your. When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. Indexes, partitions, constraints (pk, fk). Partition Key Redshift.
From medium.com
Data Partitioning in Kinesis, Dynamodb, Redshift and Athena by Partition Key Redshift Auto, even, key, or all. Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. Key requires a single column to be defined as a distkey. According to this page, you can partition data in redshift spectrum by a key which is based on. Partition Key Redshift.
From www.site24x7.net.au
Azure Cosmos DB Partitioning A Complete Guide Site24x7 Partition Key Redshift According to this page, you can partition data in redshift spectrum by a key which is based on the source s3 folder where your. When you create a table, you can designate one of the following distribution styles: Auto, even, key, or all. When you load data into a table, amazon redshift distributes the rows of the table to each. Partition Key Redshift.
From video2.skills-academy.com
Hierarchical partition keys Azure Cosmos DB Microsoft Learn Partition Key Redshift Auto, even, key, or all. Key requires a single column to be defined as a distkey. Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar.. Partition Key Redshift.
From joizfnjer.blob.core.windows.net
Partition Key Guid at Grace Jones blog Partition Key Redshift When you create a table, you can designate one of the following distribution styles: Auto, even, key, or all. If you don't specify a distribution style,. When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. Key requires a single column to be defined. Partition Key Redshift.
From learn.microsoft.com
Partitioning in Azure Cosmos DB for Apache Cassandra Microsoft Learn Partition Key Redshift Auto, even, key, or all. According to this page, you can partition data in redshift spectrum by a key which is based on the source s3 folder where your. When you create a table, you can designate one of the following distribution styles: While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve. Partition Key Redshift.
From dineshshankar.com
AWS Redshift Best Practices Partition Key Redshift According to this page, you can partition data in redshift spectrum by a key which is based on the source s3 folder where your. On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice consistently. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. When. Partition Key Redshift.
From awesomehome.co
Create Table Syntax Redshift Awesome Home Partition Key Redshift When you create a table, you can designate one of the following distribution styles: When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. According to this page, you can partition data in redshift spectrum by a key which is based on the source. Partition Key Redshift.
From docs.aws.amazon.com
Loading your data in sort key order Amazon Redshift Partition Key Redshift Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file' } a clause that sets. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. On ingest,. Partition Key Redshift.
From stackoverflow.com
java DynamoDB Table Partition key and sort key are 11 how to go Partition Key Redshift If you don't specify a distribution style,. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. When you create a table, you can designate one of the following distribution styles: Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t. Partition Key Redshift.
From learn.microsoft.com
Partitioning in Azure Cosmos DB for Apache Cassandra Microsoft Learn Partition Key Redshift On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice consistently. When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but. Partition Key Redshift.
From quadexcel.com
Partitioning Key vs Clustering Keys in Cassandra Cassandra Partition Key Redshift While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. When you create a table, you can designate one of the following distribution styles: Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file' } a clause that sets. When you load data into a table, amazon redshift distributes the rows of the. Partition Key Redshift.
From github.com
redshiftrenderfree · GitHub Topics · GitHub Partition Key Redshift Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file' } a clause that sets. Auto, even, key, or all. Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. When you create a table, you can designate one of the following distribution styles: If. Partition Key Redshift.
From klayplaqu.blob.core.windows.net
How To Change Sort Key In Redshift at Vincent Hammons blog Partition Key Redshift Key requires a single column to be defined as a distkey. When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. If you don't specify a distribution style,. On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice. Partition Key Redshift.
From www.youtube.com
SQL Redshift defining composite primary key YouTube Partition Key Redshift Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice consistently. Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file' } a clause that sets. According to this. Partition Key Redshift.
From www.scylladb.com
Best Practices for Data Modeling ScyllaDB Partition Key Redshift While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. If you don't specify a distribution style,. Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file'. Partition Key Redshift.
From github.com
Redshift Spectrum to Delta Lake integration using manifest files (an Partition Key Redshift On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice consistently. Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file' } a clause that sets. When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. Auto, even, key,. Partition Key Redshift.
From thedataguy.in
Why You Should Not Compress RedShift Sort Key Column Partition Key Redshift Key requires a single column to be defined as a distkey. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. If you don't specify a. Partition Key Redshift.
From velog.io
AWS Redshift 02 분산방식Diststyle (ALL, KEY, EVEN, AUTO) Partition Key Redshift While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. When you create a table, you can designate one of the following distribution styles: Key requires a single column to be defined as a distkey. On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice consistently.. Partition Key Redshift.
From learn.microsoft.com
Create Azure Cosmos DB containers with large partition key Microsoft Partition Key Redshift Key requires a single column to be defined as a distkey. When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. On ingest, amazon redshift hashes. Partition Key Redshift.
From medium.com
Dynamic Partition Pruning in Redshift Spectrum by Michael Boyar Medium Partition Key Redshift Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice consistently. Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file' } a clause that sets. If you don't. Partition Key Redshift.
From devblogs.microsoft.com
Now in private preview optimize your data distribution with Partition Key Redshift On ingest, amazon redshift hashes each distkey column value, and route hashes to the same slice consistently. Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file' } a clause that sets. Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. If you don't. Partition Key Redshift.
From medium.com
How to select the Best Partition key in Azure Cosmos DB by chamathka Partition Key Redshift Indexes, partitions, constraints (pk, fk) are often used in the traditional databases to improve query performance but redshift table natively doesn’t have indexes or partition keys. Key requires a single column to be defined as a distkey. When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to. Partition Key Redshift.
From thedataguy.in
Why You Should Not Compress RedShift Sort Key Column Partition Key Redshift Auto, even, key, or all. Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' | 's3://bucket/manifest_file' } a clause that sets. While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. According to this page, you can partition data in redshift spectrum by a key which is based on the source s3 folder where. Partition Key Redshift.
From exonyseru.blob.core.windows.net
Redshift Sort Key Auto at Emanuel Bundy blog Partition Key Redshift While redshift lacks traditional partitioning, here are techniques you can use to partition data logically and achieve similar. When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. According to this page, you can partition data in redshift spectrum by a key which is. Partition Key Redshift.
From velog.io
AWS Redshift 02 분산방식Diststyle (ALL, KEY, EVEN, AUTO) Partition Key Redshift When you load data into a table, amazon redshift distributes the rows of the table to each of the node slices according to the table's distribution. If you don't specify a distribution style,. When you create a table, you can designate one of the following distribution styles: Auto, even, key, or all. Partition ( partition_column=partition_value [,.] set location {'s3://bucket/folder' |. Partition Key Redshift.