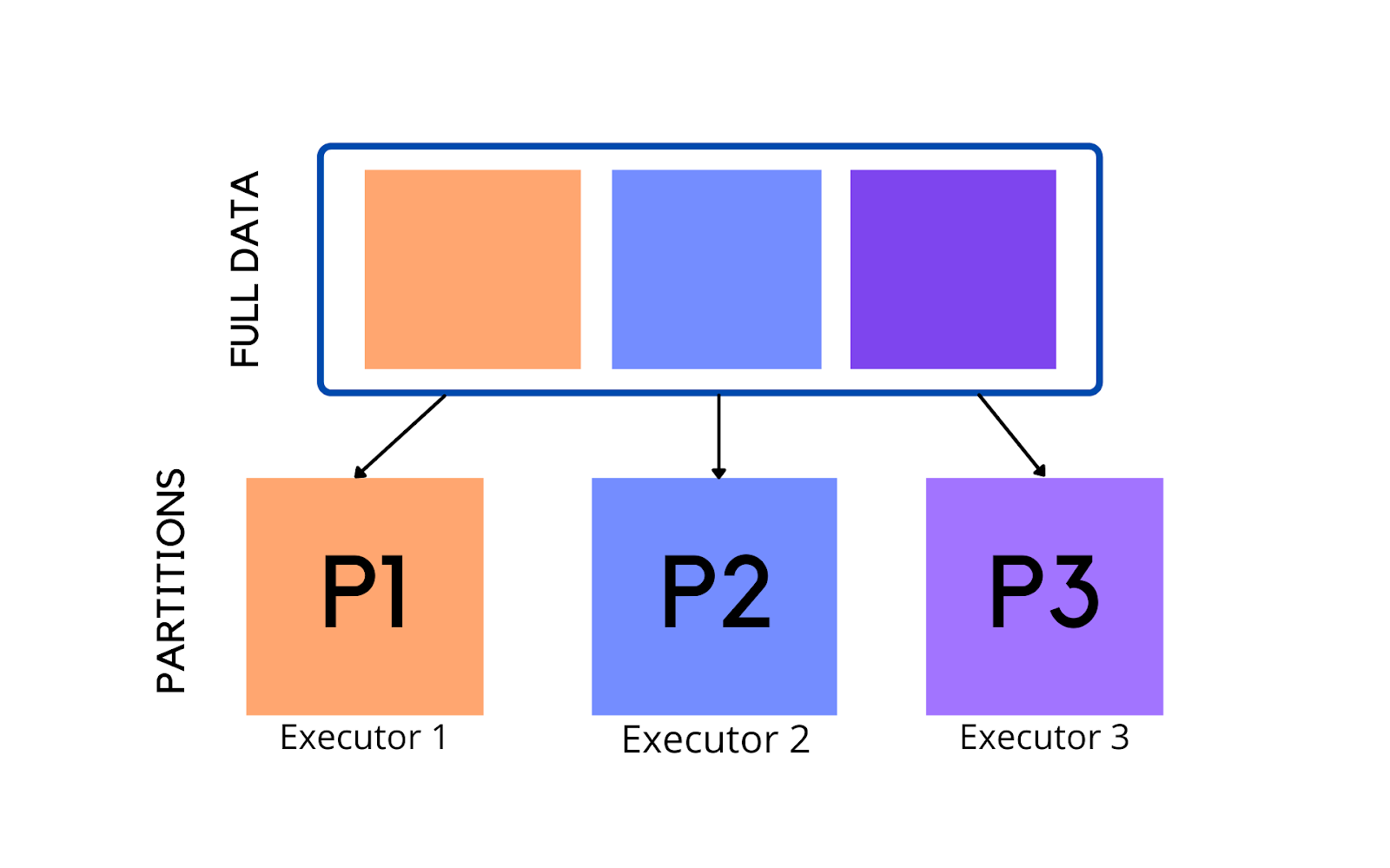
Default Number Of Partitions In Spark Dataframe . Columnorname) → dataframe [source] ¶ returns a new dataframe. Default spark shuffle partitions — 200; Let's start with some basic default and desired spark configuration parameters. Union [int, columnorname], * cols: Default number of partitions in spark. I understand that sc.parallelize and some other transformations produce the number of partitions according to. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name The coalesce method reduces the number of partitions in a dataframe. It avoids full shuffle, instead of creating new partitions, it shuffles the data using default hash. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates.
from www.projectpro.io
It avoids full shuffle, instead of creating new partitions, it shuffles the data using default hash. Default number of partitions in spark. The coalesce method reduces the number of partitions in a dataframe. Let's start with some basic default and desired spark configuration parameters. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Default spark shuffle partitions — 200; Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name Columnorname) → dataframe [source] ¶ returns a new dataframe. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. I understand that sc.parallelize and some other transformations produce the number of partitions according to.
How Data Partitioning in Spark helps achieve more parallelism?
Default Number Of Partitions In Spark Dataframe Columnorname) → dataframe [source] ¶ returns a new dataframe. It avoids full shuffle, instead of creating new partitions, it shuffles the data using default hash. I understand that sc.parallelize and some other transformations produce the number of partitions according to. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Default spark shuffle partitions — 200; Default number of partitions in spark. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Let's start with some basic default and desired spark configuration parameters. Union [int, columnorname], * cols: The coalesce method reduces the number of partitions in a dataframe. Columnorname) → dataframe [source] ¶ returns a new dataframe. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name
From medium.com
Simple Method to choose Number of Partitions in Spark by Tharun Kumar Sekar Analytics Vidhya Default Number Of Partitions In Spark Dataframe Columnorname) → dataframe [source] ¶ returns a new dataframe. The coalesce method reduces the number of partitions in a dataframe. Default number of partitions in spark. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by. Default Number Of Partitions In Spark Dataframe.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Default Number Of Partitions In Spark Dataframe Data partitioning is critical to data processing performance especially for large volume of data processing in spark. It avoids full shuffle, instead of creating new partitions, it shuffles the data using default hash. Default number of partitions in spark. Union [int, columnorname], * cols: When you read data from a source (e.g., a text file, a csv file, or a. Default Number Of Partitions In Spark Dataframe.
From stackoverflow.com
Partition a Spark DataFrame based on values in an existing column into a chosen number of Default Number Of Partitions In Spark Dataframe Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Default number of partitions in spark. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name It avoids full shuffle, instead of creating new partitions, it shuffles the data using default hash. The. Default Number Of Partitions In Spark Dataframe.
From www.jetbrains.com
Spark DataFrame coding assistance PyCharm Documentation Default Number Of Partitions In Spark Dataframe Default number of partitions in spark. Union [int, columnorname], * cols: Let's start with some basic default and desired spark configuration parameters. Default spark shuffle partitions — 200; Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name The coalesce method reduces the number of partitions in a dataframe. I. Default Number Of Partitions In Spark Dataframe.
From hadoopsters.wordpress.com
How to See Record Count Per Partition in a Spark DataFrame (i.e. Find Skew) Hadoopsters Default Number Of Partitions In Spark Dataframe The coalesce method reduces the number of partitions in a dataframe. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Let's start with some basic default and desired spark configuration parameters. It avoids full shuffle, instead of creating new partitions, it shuffles the data using default hash. I. Default Number Of Partitions In Spark Dataframe.
From medium.com
Spark Under The Hood Partition. Spark is a distributed computing engine… by Thejas Babu Medium Default Number Of Partitions In Spark Dataframe Default spark shuffle partitions — 200; I understand that sc.parallelize and some other transformations produce the number of partitions according to. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. The coalesce method reduces the number of partitions in a dataframe. Data partitioning is critical to data processing. Default Number Of Partitions In Spark Dataframe.
From www.youtube.com
Number of Partitions in Dataframe Spark Tutorial Interview Question YouTube Default Number Of Partitions In Spark Dataframe Default spark shuffle partitions — 200; Let's start with some basic default and desired spark configuration parameters. I understand that sc.parallelize and some other transformations produce the number of partitions according to. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Default number of partitions in spark. Columnorname). Default Number Of Partitions In Spark Dataframe.
From www.youtube.com
How to partition and write DataFrame in Spark without deleting partitions with no new data Default Number Of Partitions In Spark Dataframe The coalesce method reduces the number of partitions in a dataframe. It avoids full shuffle, instead of creating new partitions, it shuffles the data using default hash. Union [int, columnorname], * cols: Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name Columnorname) → dataframe [source] ¶ returns a new. Default Number Of Partitions In Spark Dataframe.
From exokeufcv.blob.core.windows.net
Max Number Of Partitions In Spark at Manda Salazar blog Default Number Of Partitions In Spark Dataframe Columnorname) → dataframe [source] ¶ returns a new dataframe. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Union [int, columnorname], * cols: Let's start with some basic. Default Number Of Partitions In Spark Dataframe.
From hxeiseozo.blob.core.windows.net
Partitions Number Spark at Vernon Hyman blog Default Number Of Partitions In Spark Dataframe Default number of partitions in spark. Default spark shuffle partitions — 200; Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Union [int, columnorname], * cols: It avoids. Default Number Of Partitions In Spark Dataframe.
From spaziocodice.com
Spark SQL Partitions and Sizes SpazioCodice Default Number Of Partitions In Spark Dataframe I understand that sc.parallelize and some other transformations produce the number of partitions according to. Let's start with some basic default and desired spark configuration parameters. The coalesce method reduces the number of partitions in a dataframe. Default spark shuffle partitions — 200; Columnorname) → dataframe [source] ¶ returns a new dataframe. Data partitioning is critical to data processing performance. Default Number Of Partitions In Spark Dataframe.
From www.youtube.com
Apache Spark Data Partitioning Example YouTube Default Number Of Partitions In Spark Dataframe Let's start with some basic default and desired spark configuration parameters. I understand that sc.parallelize and some other transformations produce the number of partitions according to. Default spark shuffle partitions — 200; Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Default number of partitions in spark. Columnorname) → dataframe [source] ¶. Default Number Of Partitions In Spark Dataframe.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Default Number Of Partitions In Spark Dataframe Data partitioning is critical to data processing performance especially for large volume of data processing in spark. I understand that sc.parallelize and some other transformations produce the number of partitions according to. The coalesce method reduces the number of partitions in a dataframe. Let's start with some basic default and desired spark configuration parameters. Union [int, columnorname], * cols: Columnorname). Default Number Of Partitions In Spark Dataframe.
From docs-gcp.qubole.com
Visualizing Spark Dataframes — Qubole Data Service documentation Default Number Of Partitions In Spark Dataframe When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Default spark shuffle partitions — 200; Data partitioning is critical to data processing performance especially for large volume of data processing in spark. I understand that sc.parallelize and some other transformations produce the number of partitions according to. Union. Default Number Of Partitions In Spark Dataframe.
From livebook.manning.com
liveBook · Manning Default Number Of Partitions In Spark Dataframe Data partitioning is critical to data processing performance especially for large volume of data processing in spark. The coalesce method reduces the number of partitions in a dataframe. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name I understand that sc.parallelize and some other transformations produce the number of. Default Number Of Partitions In Spark Dataframe.
From developer.hpe.com
Datasets, DataFrames, and Spark SQL for Processing of Tabular Data HPE Developer Portal Default Number Of Partitions In Spark Dataframe Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name Default number of partitions in spark. Default spark shuffle partitions — 200; It avoids full shuffle, instead of creating new partitions, it shuffles. Default Number Of Partitions In Spark Dataframe.
From www.projectpro.io
DataFrames number of partitions in spark scala in Databricks Default Number Of Partitions In Spark Dataframe Default number of partitions in spark. Columnorname) → dataframe [source] ¶ returns a new dataframe. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Default spark shuffle partitions — 200; Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single. Default Number Of Partitions In Spark Dataframe.
From www.youtube.com
Spark Application Partition By in Spark Chapter 2 LearntoSpark YouTube Default Number Of Partitions In Spark Dataframe Let's start with some basic default and desired spark configuration parameters. Columnorname) → dataframe [source] ¶ returns a new dataframe. The coalesce method reduces the number of partitions in a dataframe. I understand that sc.parallelize and some other transformations produce the number of partitions according to. Default spark shuffle partitions — 200; When you read data from a source (e.g.,. Default Number Of Partitions In Spark Dataframe.
From techvidvan.com
Introduction on Apache Spark SQL DataFrame TechVidvan Default Number Of Partitions In Spark Dataframe Default spark shuffle partitions — 200; I understand that sc.parallelize and some other transformations produce the number of partitions according to. Default number of partitions in spark. Union [int, columnorname], * cols: Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions. Default Number Of Partitions In Spark Dataframe.
From www.projectpro.io
How Data Partitioning in Spark helps achieve more parallelism? Default Number Of Partitions In Spark Dataframe Columnorname) → dataframe [source] ¶ returns a new dataframe. Default number of partitions in spark. Let's start with some basic default and desired spark configuration parameters. I understand that sc.parallelize and some other transformations produce the number of partitions according to. Union [int, columnorname], * cols: The coalesce method reduces the number of partitions in a dataframe. When you read. Default Number Of Partitions In Spark Dataframe.
From medium.com
Managing Spark Partitions. How data is partitioned and when do you… by xuan zou Medium Default Number Of Partitions In Spark Dataframe Union [int, columnorname], * cols: When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name Data partitioning is critical to data processing performance especially for large volume of data. Default Number Of Partitions In Spark Dataframe.
From laptrinhx.com
Managing Partitions Using Spark Dataframe Methods LaptrinhX / News Default Number Of Partitions In Spark Dataframe Union [int, columnorname], * cols: It avoids full shuffle, instead of creating new partitions, it shuffles the data using default hash. I understand that sc.parallelize and some other transformations produce the number of partitions according to. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Data partitioning is. Default Number Of Partitions In Spark Dataframe.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Default Number Of Partitions In Spark Dataframe The coalesce method reduces the number of partitions in a dataframe. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Default number of partitions in spark. I understand that sc.parallelize and. Default Number Of Partitions In Spark Dataframe.
From jsmithmoore.com
Dataframe map spark java Default Number Of Partitions In Spark Dataframe I understand that sc.parallelize and some other transformations produce the number of partitions according to. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. The coalesce method reduces the number of partitions in a dataframe. Union [int, columnorname], * cols: Columnorname) → dataframe [source] ¶ returns a new. Default Number Of Partitions In Spark Dataframe.
From sparkbyexamples.com
Spark Get Current Number of Partitions of DataFrame Spark By {Examples} Default Number Of Partitions In Spark Dataframe Data partitioning is critical to data processing performance especially for large volume of data processing in spark. I understand that sc.parallelize and some other transformations produce the number of partitions according to. Default number of partitions in spark. Let's start with some basic default and desired spark configuration parameters. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions. Default Number Of Partitions In Spark Dataframe.
From hxeiseozo.blob.core.windows.net
Partitions Number Spark at Vernon Hyman blog Default Number Of Partitions In Spark Dataframe Let's start with some basic default and desired spark configuration parameters. Default number of partitions in spark. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name I understand. Default Number Of Partitions In Spark Dataframe.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient Default Number Of Partitions In Spark Dataframe Default spark shuffle partitions — 200; Default number of partitions in spark. The coalesce method reduces the number of partitions in a dataframe. Columnorname) → dataframe [source] ¶ returns a new dataframe. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Let's start with some basic default and. Default Number Of Partitions In Spark Dataframe.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders Default Number Of Partitions In Spark Dataframe Union [int, columnorname], * cols: I understand that sc.parallelize and some other transformations produce the number of partitions according to. Default spark shuffle partitions — 200; When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Data partitioning is critical to data processing performance especially for large volume of. Default Number Of Partitions In Spark Dataframe.
From medium.com
Guide to Selection of Number of Partitions while reading Data Files in Apache Spark The Startup Default Number Of Partitions In Spark Dataframe I understand that sc.parallelize and some other transformations produce the number of partitions according to. Columnorname) → dataframe [source] ¶ returns a new dataframe. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Union [int, columnorname], * cols: It avoids full shuffle, instead of creating new partitions, it. Default Number Of Partitions In Spark Dataframe.
From sparkbyexamples.com
Calculate Size of Spark DataFrame & RDD Spark By {Examples} Default Number Of Partitions In Spark Dataframe Let's start with some basic default and desired spark configuration parameters. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates. Union [int, columnorname], * cols: The coalesce method reduces the number of partitions in a dataframe. It avoids full shuffle, instead of creating new partitions, it shuffles the. Default Number Of Partitions In Spark Dataframe.
From sparkbyexamples.com
PySpark Create DataFrame with Examples Spark By {Examples} Default Number Of Partitions In Spark Dataframe Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Union [int, columnorname], * cols: Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name Default number of partitions in spark. Default spark shuffle partitions — 200; I understand that sc.parallelize and some. Default Number Of Partitions In Spark Dataframe.
From www.youtube.com
Trending Big Data Interview Question Number of Partitions in your Spark Dataframe YouTube Default Number Of Partitions In Spark Dataframe Default number of partitions in spark. I understand that sc.parallelize and some other transformations produce the number of partitions according to. Union [int, columnorname], * cols: The coalesce method reduces the number of partitions in a dataframe. Columnorname) → dataframe [source] ¶ returns a new dataframe. When you read data from a source (e.g., a text file, a csv file,. Default Number Of Partitions In Spark Dataframe.
From www.youtube.com
Why should we partition the data in spark? YouTube Default Number Of Partitions In Spark Dataframe Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name The coalesce method reduces the number of partitions in a dataframe. Let's start with some basic default and desired spark configuration parameters. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. When. Default Number Of Partitions In Spark Dataframe.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Default Number Of Partitions In Spark Dataframe Default number of partitions in spark. I understand that sc.parallelize and some other transformations produce the number of partitions according to. Default spark shuffle partitions — 200; Data partitioning is critical to data processing performance especially for large volume of data processing in spark. When you read data from a source (e.g., a text file, a csv file, or a. Default Number Of Partitions In Spark Dataframe.
From www.youtube.com
How To Set And Get Number Of Partition In Spark Spark Partition Big Data YouTube Default Number Of Partitions In Spark Dataframe Columnorname) → dataframe [source] ¶ returns a new dataframe. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name Default spark shuffle partitions — 200; The coalesce method reduces the number of partitions. Default Number Of Partitions In Spark Dataframe.