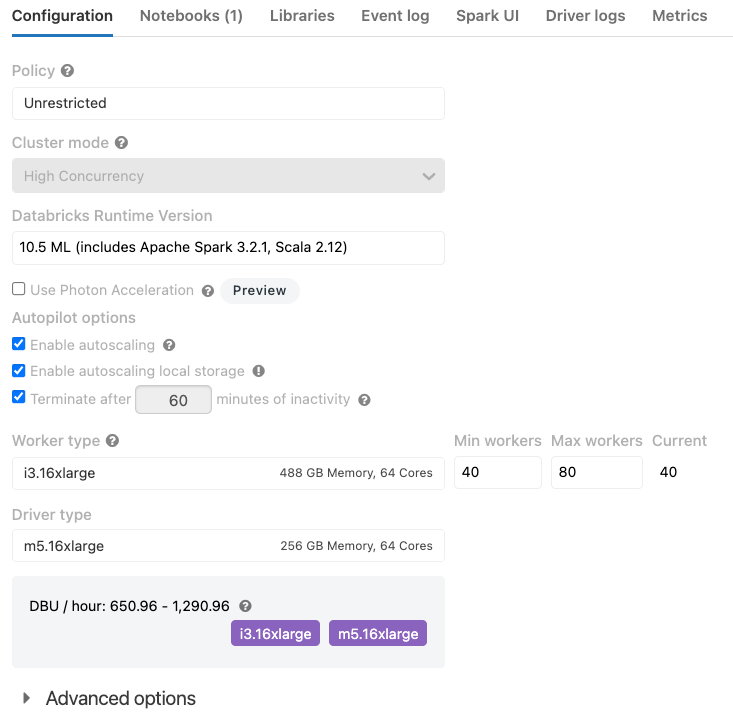
Spark.sql.shuffle.partitions In Pyspark . explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. once you’ve calculated it, set the number of partitions like this:
from medium.com
when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. once you’ve calculated it, set the number of partitions like this: spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks.
PySpark on Databricks Tips and Tricks by Tung Thanh Le Medium
Spark.sql.shuffle.partitions In Pyspark once you’ve calculated it, set the number of partitions like this: spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. once you’ve calculated it, set the number of partitions like this: explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split.
From sparkbyexamples.com
Spark SQL Explained with Examples Spark By {Examples} Spark.sql.shuffle.partitions In Pyspark spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. once you’ve calculated it, set the number of partitions like this: when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. Spark.sql.shuffle.partitions In Pyspark.
From pyongwonlee.com
[Spark By Example] SparkSession Scriptorium Spark.sql.shuffle.partitions In Pyspark spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. once you’ve calculated it, set the number of partitions like this: explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Spark.sql.shuffle.partitions In Pyspark.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Spark.sql.shuffle.partitions In Pyspark once you’ve calculated it, set the number of partitions like this: spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. Spark.sql.shuffle.partitions In Pyspark.
From www.youtube.com
24. How To Use SQL In Databricks Spark SQL PySpark YouTube Spark.sql.shuffle.partitions In Pyspark once you’ve calculated it, set the number of partitions like this: when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. Spark.sql.shuffle.partitions In Pyspark.
From codeantenna.com
spark SQL 任务参数调优1 CodeAntenna Spark.sql.shuffle.partitions In Pyspark when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. once you’ve calculated it, set the number of partitions like this: spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. Spark.sql.shuffle.partitions In Pyspark.
From www.newsletter.swirlai.com
A Guide to Optimising your Spark Application Performance (Part 1). Spark.sql.shuffle.partitions In Pyspark once you’ve calculated it, set the number of partitions like this: explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. Spark.sql.shuffle.partitions In Pyspark.
From www.upscpdf.in
spark.sql.shuffle.partitions UPSCPDF Spark.sql.shuffle.partitions In Pyspark once you’ve calculated it, set the number of partitions like this: when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. Spark.sql.shuffle.partitions In Pyspark.
From www.vrogue.co
What Is Cache And Persist In Pyspark And Spark Sql Us vrogue.co Spark.sql.shuffle.partitions In Pyspark once you’ve calculated it, set the number of partitions like this: when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. Spark.sql.shuffle.partitions In Pyspark.
From www.waitingforcode.com
What's new in Apache Spark 3.0 shuffle partitions coalesce on Spark.sql.shuffle.partitions In Pyspark spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. once you’ve calculated it, set the number of partitions like this: Spark.sql.shuffle.partitions In Pyspark.
From www.projectpro.io
Explain the Repartition and Coalesce functions in PySpark in Databricks Spark.sql.shuffle.partitions In Pyspark spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. once you’ve calculated it, set the number of partitions like this: explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. Spark.sql.shuffle.partitions In Pyspark.
From sparkbyexamples.com
Difference between spark.sql.shuffle.partitions vs spark.default Spark.sql.shuffle.partitions In Pyspark explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. once you’ve calculated it, set the number of partitions like this: Spark.sql.shuffle.partitions In Pyspark.
From exocpydfk.blob.core.windows.net
What Is Shuffle Partitions In Spark at Joe Warren blog Spark.sql.shuffle.partitions In Pyspark spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. once you’ve calculated it, set the number of partitions like this: when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Spark.sql.shuffle.partitions In Pyspark.
From sparkbyexamples.com
PySpark SQL expr() (Expression) Function Spark By {Examples} Spark.sql.shuffle.partitions In Pyspark when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. once you’ve calculated it, set the number of partitions like this: Spark.sql.shuffle.partitions In Pyspark.
From etheleon.github.io
Not so big queries, hitchhiker’s guide to datawarehousing with Spark.sql.shuffle.partitions In Pyspark spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. once you’ve calculated it, set the number of partitions like this: Spark.sql.shuffle.partitions In Pyspark.
From stackoverflow.com
pyspark How to join 2 dataframes in spark which are already Spark.sql.shuffle.partitions In Pyspark when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. once you’ve calculated it, set the number of partitions like this: spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. Spark.sql.shuffle.partitions In Pyspark.
From www.projectpro.io
How Data Partitioning in Spark helps achieve more parallelism? Spark.sql.shuffle.partitions In Pyspark explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. once you’ve calculated it, set the number of partitions like this: Spark.sql.shuffle.partitions In Pyspark.
From www.youtube.com
Why should we partition the data in spark? YouTube Spark.sql.shuffle.partitions In Pyspark when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. once you’ve calculated it, set the number of partitions like this: explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Spark.sql.shuffle.partitions In Pyspark.
From blog.csdn.net
PySpark基础入门(6):Spark Shuffle_pyspark shuffle writeCSDN博客 Spark.sql.shuffle.partitions In Pyspark explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. once you’ve calculated it, set the number of partitions like this: spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. Spark.sql.shuffle.partitions In Pyspark.
From medium.com
PySpark on Databricks Tips and Tricks by Tung Thanh Le Medium Spark.sql.shuffle.partitions In Pyspark once you’ve calculated it, set the number of partitions like this: explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. Spark.sql.shuffle.partitions In Pyspark.
From exocpydfk.blob.core.windows.net
What Is Shuffle Partitions In Spark at Joe Warren blog Spark.sql.shuffle.partitions In Pyspark explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. once you’ve calculated it, set the number of partitions like this: Spark.sql.shuffle.partitions In Pyspark.
From dev.to
Running PySpark in JupyterLab on a Raspberry Pi DEV Community Spark.sql.shuffle.partitions In Pyspark explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. once you’ve calculated it, set the number of partitions like this: spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. Spark.sql.shuffle.partitions In Pyspark.
From stackoverflow.com
apache spark How do I skip running the single task probing job in Spark.sql.shuffle.partitions In Pyspark when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. once you’ve calculated it, set the number of partitions like this: spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. Spark.sql.shuffle.partitions In Pyspark.
From sparkbyexamples.com
PySpark SQL Functions Spark By {Examples} Spark.sql.shuffle.partitions In Pyspark explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. once you’ve calculated it, set the number of partitions like this: Spark.sql.shuffle.partitions In Pyspark.
From www.linkedin.com
Sai Kiran Reddy Kalluri on LinkedIn pyspark spark bigdata aws Spark.sql.shuffle.partitions In Pyspark explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. once you’ve calculated it, set the number of partitions like this: Spark.sql.shuffle.partitions In Pyspark.
From 0x0fff.com
Spark Architecture Shuffle Distributed Systems Architecture Spark.sql.shuffle.partitions In Pyspark spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. once you’ve calculated it, set the number of partitions like this: Spark.sql.shuffle.partitions In Pyspark.
From blog.csdn.net
PySpark基础入门(8):Spark SQL(内容补充)_pyspark 执行sqlCSDN博客 Spark.sql.shuffle.partitions In Pyspark explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. once you’ve calculated it, set the number of partitions like this: Spark.sql.shuffle.partitions In Pyspark.
From dataengineer1.blogspot.com
What's new in Spark 3.0? Spark.sql.shuffle.partitions In Pyspark when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. once you’ve calculated it, set the number of partitions like this: spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. Spark.sql.shuffle.partitions In Pyspark.
From blog.csdn.net
spark adaptive shuffle_spark.sql.adaptive.shuffle Spark.sql.shuffle.partitions In Pyspark when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. once you’ve calculated it, set the number of partitions like this: spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Spark.sql.shuffle.partitions In Pyspark.
From exocpydfk.blob.core.windows.net
What Is Shuffle Partitions In Spark at Joe Warren blog Spark.sql.shuffle.partitions In Pyspark once you’ve calculated it, set the number of partitions like this: when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Spark.sql.shuffle.partitions In Pyspark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Spark.sql.shuffle.partitions In Pyspark once you’ve calculated it, set the number of partitions like this: explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. Spark.sql.shuffle.partitions In Pyspark.
From blog.csdn.net
spark基本知识点之Shuffle_separate file for each media typeCSDN博客 Spark.sql.shuffle.partitions In Pyspark once you’ve calculated it, set the number of partitions like this: spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. Spark.sql.shuffle.partitions In Pyspark.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Spark.sql.shuffle.partitions In Pyspark spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. once you’ve calculated it, set the number of partitions like this: explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Spark.sql.shuffle.partitions In Pyspark.
From exocpydfk.blob.core.windows.net
What Is Shuffle Partitions In Spark at Joe Warren blog Spark.sql.shuffle.partitions In Pyspark when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. once you’ve calculated it, set the number of partitions like this: explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. Spark.sql.shuffle.partitions In Pyspark.
From www.newsletter.swirlai.com
A Guide to Optimising your Spark Application Performance (Part 1). Spark.sql.shuffle.partitions In Pyspark spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. once you’ve calculated it, set the number of partitions like this: Spark.sql.shuffle.partitions In Pyspark.
From templates.udlvirtual.edu.pe
Pyspark Map Partition Example Printable Templates Spark.sql.shuffle.partitions In Pyspark explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. once you’ve calculated it, set the number of partitions like this: when true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. spark.conf.set(spark.sql.shuffle.partitions,auto) above code will set the shuffle partitions. Spark.sql.shuffle.partitions In Pyspark.