Partition Dataframe Pyspark . One approach can be first convert df into rdd,repartition it and then convert rdd back to df. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. This function is defined as the. The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. The resulting dataframe is hash partitioned. There are two functions you can use in spark to repartition data and coalesce is one of them. Columnorname) → dataframe¶ returns a new dataframe. Returns a new dataframe partitioned by the given partitioning expressions. Union [int, columnorname], * cols: But this takes a lot of time.
from www.learntospark.com
But this takes a lot of time. Union [int, columnorname], * cols: The resulting dataframe is hash partitioned. One approach can be first convert df into rdd,repartition it and then convert rdd back to df. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. This function is defined as the. Columnorname) → dataframe¶ returns a new dataframe. The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. Returns a new dataframe partitioned by the given partitioning expressions. There are two functions you can use in spark to repartition data and coalesce is one of them.
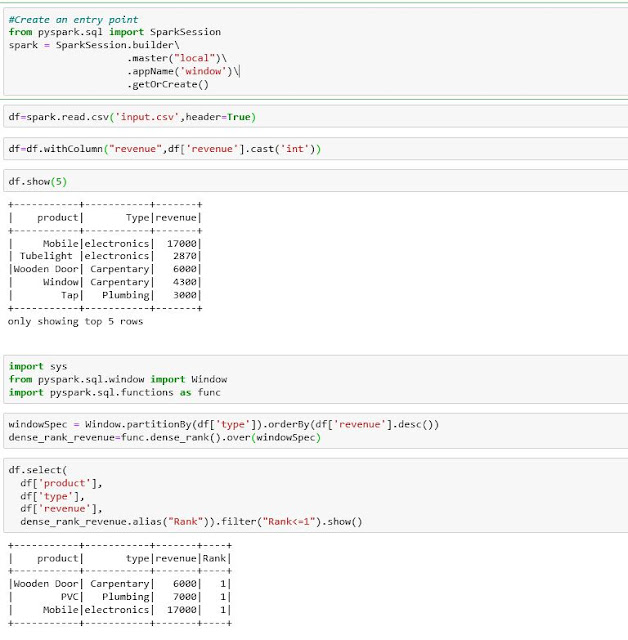
How to Select First Row of Each Group in Spark Window Function using
Partition Dataframe Pyspark Returns a new dataframe partitioned by the given partitioning expressions. Returns a new dataframe partitioned by the given partitioning expressions. There are two functions you can use in spark to repartition data and coalesce is one of them. The resulting dataframe is hash partitioned. But this takes a lot of time. One approach can be first convert df into rdd,repartition it and then convert rdd back to df. This function is defined as the. The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. Union [int, columnorname], * cols: Columnorname) → dataframe¶ returns a new dataframe.
From www.geeksforgeeks.org
PySpark partitionBy() method Partition Dataframe Pyspark The resulting dataframe is hash partitioned. The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. But this takes a lot of time. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. Partition Dataframe Pyspark.
From urlit.me
PySpark — Dynamic Partition Overwrite Partition Dataframe Pyspark This function is defined as the. There are two functions you can use in spark to repartition data and coalesce is one of them. The resulting dataframe is hash partitioned. The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. One approach can be first convert df into rdd,repartition it and then convert rdd back to. Partition Dataframe Pyspark.
From stackoverflow.com
python Repartitioning a pyspark dataframe fails and how to avoid the Partition Dataframe Pyspark The resulting dataframe is hash partitioned. The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. Columnorname) → dataframe¶ returns a new dataframe. Returns a new dataframe partitioned by the given partitioning expressions. The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or. Partition Dataframe Pyspark.
From deepsense.ai
Optimize Spark with DISTRIBUTE BY & CLUSTER BY deepsense.ai Partition Dataframe Pyspark The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. Returns a new dataframe partitioned by the given partitioning expressions. The resulting dataframe is hash partitioned. Pyspark.sql.dataframe.repartition () method is used. Partition Dataframe Pyspark.
From joiuxvimk.blob.core.windows.net
Partitioning Data In Oracle Table at David Evans blog Partition Dataframe Pyspark But this takes a lot of time. The resulting dataframe is hash partitioned. The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. Pyspark.sql.dataframe.repartition () method is used to increase or. Partition Dataframe Pyspark.
From webframes.org
Convert Sql Table To Pandas Dataframe Databricks Partition Dataframe Pyspark There are two functions you can use in spark to repartition data and coalesce is one of them. Union [int, columnorname], * cols: The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. But this takes a lot of time. Returns a new dataframe partitioned. Partition Dataframe Pyspark.
From stackoverflow.com
python Repartitioning a pyspark dataframe fails and how to avoid the Partition Dataframe Pyspark The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. Returns a new dataframe partitioned by the given partitioning expressions. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. The resulting dataframe is hash partitioned. Union [int, columnorname], * cols:. Partition Dataframe Pyspark.
From www.educba.com
PySpark list to dataframe Learn the Wroking of PySpark list to dataframe Partition Dataframe Pyspark There are two functions you can use in spark to repartition data and coalesce is one of them. Columnorname) → dataframe¶ returns a new dataframe. One approach can be first convert df into rdd,repartition it and then convert rdd back to df. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by. Partition Dataframe Pyspark.
From azurelib.com
How to combine DataFrames in PySpark Azure Databricks? Partition Dataframe Pyspark Columnorname) → dataframe¶ returns a new dataframe. The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. Union [int, columnorname], * cols: But this takes a lot of time. Returns a new dataframe partitioned by the given partitioning expressions. There are two functions you can use in spark to repartition data and coalesce is one of. Partition Dataframe Pyspark.
From www.datacamp.com
PySpark Cheat Sheet Spark DataFrames in Python DataCamp Partition Dataframe Pyspark This function is defined as the. The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. One approach can be first convert df into rdd,repartition it and then convert rdd back to df. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions. Partition Dataframe Pyspark.
From developer.hpe.com
Datasets, DataFrames, and Spark SQL for Processing of Tabular Data Partition Dataframe Pyspark The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. The resulting dataframe is hash partitioned. This function is defined as the. The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. Pyspark.sql.dataframe.repartition () method is used to increase or decrease. Partition Dataframe Pyspark.
From stackoverflow.com
python How to find std dev partitioned or grouped data using pyspark Partition Dataframe Pyspark There are two functions you can use in spark to repartition data and coalesce is one of them. Returns a new dataframe partitioned by the given partitioning expressions. But this takes a lot of time. This function is defined as the. One approach can be first convert df into rdd,repartition it and then convert rdd back to df. The partitionby(). Partition Dataframe Pyspark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Partition Dataframe Pyspark Returns a new dataframe partitioned by the given partitioning expressions. But this takes a lot of time. There are two functions you can use in spark to repartition data and coalesce is one of them. Union [int, columnorname], * cols: The resulting dataframe is hash partitioned. One approach can be first convert df into rdd,repartition it and then convert rdd. Partition Dataframe Pyspark.
From klaojgfcx.blob.core.windows.net
How To Determine Number Of Partitions In Spark at Troy Powell blog Partition Dataframe Pyspark There are two functions you can use in spark to repartition data and coalesce is one of them. Columnorname) → dataframe¶ returns a new dataframe. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. The dataframe repartition() method allows redistributing data into new partitions. Partition Dataframe Pyspark.
From datascienceparichay.com
Filter PySpark DataFrame with where() Data Science Parichay Partition Dataframe Pyspark One approach can be first convert df into rdd,repartition it and then convert rdd back to df. There are two functions you can use in spark to repartition data and coalesce is one of them. Returns a new dataframe partitioned by the given partitioning expressions. But this takes a lot of time. This function is defined as the. The dataframe. Partition Dataframe Pyspark.
From stackoverflow.com
azure pyspark partitioning create an extra empty file for every Partition Dataframe Pyspark The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. Returns a new dataframe partitioned by the given partitioning expressions. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names.. Partition Dataframe Pyspark.
From templates.udlvirtual.edu.pe
Pyspark Map Partition Example Printable Templates Partition Dataframe Pyspark Returns a new dataframe partitioned by the given partitioning expressions. This function is defined as the. Columnorname) → dataframe¶ returns a new dataframe. The resulting dataframe is hash partitioned. There are two functions you can use in spark to repartition data and coalesce is one of them. One approach can be first convert df into rdd,repartition it and then convert. Partition Dataframe Pyspark.
From urlit.me
PySpark — Dynamic Partition Overwrite Partition Dataframe Pyspark There are two functions you can use in spark to repartition data and coalesce is one of them. This function is defined as the. The resulting dataframe is hash partitioned. The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. One approach can be first. Partition Dataframe Pyspark.
From stackoverflow.com
pyspark Why does Spark Query Plan shows more partitions whenever Partition Dataframe Pyspark The resulting dataframe is hash partitioned. Returns a new dataframe partitioned by the given partitioning expressions. The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. But this takes a lot of time. Columnorname) → dataframe¶ returns a new dataframe. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions. Partition Dataframe Pyspark.
From sparkbyexamples.com
PySpark partitionBy() Write to Disk Example Spark By {Examples} Partition Dataframe Pyspark But this takes a lot of time. Union [int, columnorname], * cols: The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. Returns a new dataframe partitioned by the given partitioning expressions. The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more. Partition Dataframe Pyspark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Partition Dataframe Pyspark Returns a new dataframe partitioned by the given partitioning expressions. This function is defined as the. One approach can be first convert df into rdd,repartition it and then convert rdd back to df. There are two functions you can use in spark to repartition data and coalesce is one of them. Union [int, columnorname], * cols: Pyspark.sql.dataframe.repartition () method is. Partition Dataframe Pyspark.
From www.quora.com
What is a DataFrame in Spark SQL? Quora Partition Dataframe Pyspark The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. But this takes a lot of time. The resulting dataframe is hash partitioned. Columnorname) → dataframe¶ returns a new dataframe. There are two functions you can use in spark to repartition data and coalesce is. Partition Dataframe Pyspark.
From tupuy.com
How To Join Two Dataframes With Different Columns In Pyspark Partition Dataframe Pyspark Returns a new dataframe partitioned by the given partitioning expressions. There are two functions you can use in spark to repartition data and coalesce is one of them. Columnorname) → dataframe¶ returns a new dataframe. The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe. Partition Dataframe Pyspark.
From www.youtube.com
PySpark How to Load BigQuery table into Spark Dataframe YouTube Partition Dataframe Pyspark This function is defined as the. The resulting dataframe is hash partitioned. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. One approach can be first convert df into rdd,repartition it and then convert rdd back to df. But this takes a lot of. Partition Dataframe Pyspark.
From www.learntospark.com
How to Select First Row of Each Group in Spark Window Function using Partition Dataframe Pyspark The resulting dataframe is hash partitioned. But this takes a lot of time. The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. One approach can be first convert df into rdd,repartition it and then convert rdd back to df. There are two functions you. Partition Dataframe Pyspark.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient Partition Dataframe Pyspark There are two functions you can use in spark to repartition data and coalesce is one of them. One approach can be first convert df into rdd,repartition it and then convert rdd back to df. This function is defined as the. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single. Partition Dataframe Pyspark.
From www.youtube.com
Pyspark Scenarios 7 how to get no of rows at each partition in Partition Dataframe Pyspark Columnorname) → dataframe¶ returns a new dataframe. There are two functions you can use in spark to repartition data and coalesce is one of them. But this takes a lot of time. This function is defined as the. One approach can be first convert df into rdd,repartition it and then convert rdd back to df. The resulting dataframe is hash. Partition Dataframe Pyspark.
From datascienceparichay.com
Get Pyspark Dataframe Summary Statistics Data Science Parichay Partition Dataframe Pyspark Returns a new dataframe partitioned by the given partitioning expressions. There are two functions you can use in spark to repartition data and coalesce is one of them. But this takes a lot of time. This function is defined as the. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single. Partition Dataframe Pyspark.
From www.projectpro.io
Pyspark concatenate two dataframes horizontally Projectpro Partition Dataframe Pyspark Union [int, columnorname], * cols: The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. Columnorname) → dataframe¶ returns a new dataframe. The resulting dataframe is hash partitioned. This function is. Partition Dataframe Pyspark.
From medium.com
PySpark Methods & Optimization Technique by Faraza753 Aug, 2024 Partition Dataframe Pyspark But this takes a lot of time. Union [int, columnorname], * cols: One approach can be first convert df into rdd,repartition it and then convert rdd back to df. The resulting dataframe is hash partitioned. There are two functions you can use in spark to repartition data and coalesce is one of them. The dataframe repartition() method allows redistributing data. Partition Dataframe Pyspark.
From livebook.manning.com
liveBook · Manning Partition Dataframe Pyspark There are two functions you can use in spark to repartition data and coalesce is one of them. The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. One approach can be first convert df into rdd,repartition it and then convert rdd back to df.. Partition Dataframe Pyspark.
From stackoverflow.com
pyspark How to join efficiently 2 Spark dataframes partitioned by Partition Dataframe Pyspark One approach can be first convert df into rdd,repartition it and then convert rdd back to df. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. This function is defined as the. But this takes a lot of time. The partitionby() method in pyspark. Partition Dataframe Pyspark.
From gbu-taganskij.ru
A Complete Guide To PySpark Dataframes Built In, 50 OFF Partition Dataframe Pyspark The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. Returns a new dataframe partitioned by the given partitioning expressions. The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. Columnorname) → dataframe¶ returns a new dataframe. There are two functions. Partition Dataframe Pyspark.
From tech.dely.jp
Sharding vs. Partitioning Demystified Scaling Your Database dely Partition Dataframe Pyspark Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. The resulting dataframe is hash partitioned. One approach can be first convert df into rdd,repartition it and then convert rdd back to df. The dataframe repartition() method allows redistributing data into new partitions to improve. Partition Dataframe Pyspark.
From www.youtube.com
How to partition and write DataFrame in Spark without deleting Partition Dataframe Pyspark There are two functions you can use in spark to repartition data and coalesce is one of them. The partitionby() method in pyspark is used to split a dataframe into smaller, more manageable partitions based on the values in one or more columns. The dataframe repartition() method allows redistributing data into new partitions to improve processing performance. Returns a new. Partition Dataframe Pyspark.