Partition Key Aws Glue . First, we cover how to set up a crawler to automatically scan your. To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. When you create a partition index, you specify a list of partition keys that already exist on a given table. I am able to write to parquet format and partitioned by a column like so: You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers, or using aws glue etl jobs. In aws glue, table definitions include the partitioning key of a table. In this post, we show you how to efficiently process partitioned datasets using aws glue. List of partition key values that define the partition to update. When aws glue evaluates the data in amazon s3 folders to. Jobname = args['job_name'] #header is a spark.
from docs.aws.amazon.com
You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers, or using aws glue etl jobs. When aws glue evaluates the data in amazon s3 folders to. Jobname = args['job_name'] #header is a spark. To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. I am able to write to parquet format and partitioned by a column like so: In this post, we show you how to efficiently process partitioned datasets using aws glue. When you create a partition index, you specify a list of partition keys that already exist on a given table. In aws glue, table definitions include the partitioning key of a table. First, we cover how to set up a crawler to automatically scan your. List of partition key values that define the partition to update.
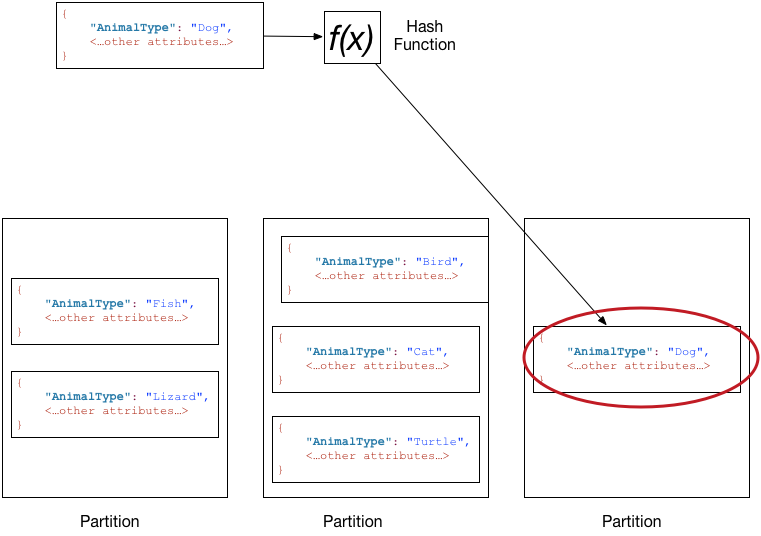
Partitions and data distribution Amazon DynamoDB
Partition Key Aws Glue To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. When you create a partition index, you specify a list of partition keys that already exist on a given table. First, we cover how to set up a crawler to automatically scan your. When aws glue evaluates the data in amazon s3 folders to. You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers, or using aws glue etl jobs. In aws glue, table definitions include the partitioning key of a table. Jobname = args['job_name'] #header is a spark. List of partition key values that define the partition to update. In this post, we show you how to efficiently process partitioned datasets using aws glue. I am able to write to parquet format and partitioned by a column like so:
From fig.io
aws glue createpartition Fig Partition Key Aws Glue In this post, we show you how to efficiently process partitioned datasets using aws glue. I am able to write to parquet format and partitioned by a column like so: List of partition key values that define the partition to update. When you create a partition index, you specify a list of partition keys that already exist on a given. Partition Key Aws Glue.
From noise.getoto.net
Improve Amazon Athena query performance using AWS Glue Data Catalog Partition Key Aws Glue You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers, or using aws glue etl jobs. In aws glue, table definitions include the partitioning key of a table. To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage. Partition Key Aws Glue.
From www.jetbrains.com
AWS Glue IntelliJ IDEA Documentation Partition Key Aws Glue In this post, we show you how to efficiently process partitioned datasets using aws glue. I am able to write to parquet format and partitioned by a column like so: List of partition key values that define the partition to update. When you create a partition index, you specify a list of partition keys that already exist on a given. Partition Key Aws Glue.
From alsmola.medium.com
Use AWS Glue to make CloudTrail Parquet partitions by Alex Smolen Partition Key Aws Glue When you create a partition index, you specify a list of partition keys that already exist on a given table. In this post, we show you how to efficiently process partitioned datasets using aws glue. Jobname = args['job_name'] #header is a spark. First, we cover how to set up a crawler to automatically scan your. To speed up query processing. Partition Key Aws Glue.
From aws.amazon.com
Get started managing partitions for Amazon S3 tables backed by the AWS Partition Key Aws Glue Jobname = args['job_name'] #header is a spark. When aws glue evaluates the data in amazon s3 folders to. First, we cover how to set up a crawler to automatically scan your. In aws glue, table definitions include the partitioning key of a table. When you create a partition index, you specify a list of partition keys that already exist on. Partition Key Aws Glue.
From github.com
awsgluedeveloperguide/awsglueapicatalogpartitions.md at master Partition Key Aws Glue When aws glue evaluates the data in amazon s3 folders to. I am able to write to parquet format and partitioned by a column like so: You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers, or using aws glue etl jobs. When you create a partition. Partition Key Aws Glue.
From medium.com
Get AWS Glue Table Partition Metadata by boto3 3 ways by Lifeis Partition Key Aws Glue To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. First, we cover how to set up a crawler to automatically scan your. You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers,. Partition Key Aws Glue.
From 9to5answer.com
[Solved] How to create AWS Glue table where partitions 9to5Answer Partition Key Aws Glue List of partition key values that define the partition to update. When you create a partition index, you specify a list of partition keys that already exist on a given table. In this post, we show you how to efficiently process partitioned datasets using aws glue. In aws glue, table definitions include the partitioning key of a table. To speed. Partition Key Aws Glue.
From hassaanbinaslam.github.io
Random Thoughts Working with partition indexes in AWS Glue Partition Key Aws Glue In this post, we show you how to efficiently process partitioned datasets using aws glue. List of partition key values that define the partition to update. When aws glue evaluates the data in amazon s3 folders to. You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers,. Partition Key Aws Glue.
From aws.amazon.com
Use AWS Glue ETL to perform merge, partition evolution, and schema Partition Key Aws Glue When aws glue evaluates the data in amazon s3 folders to. In this post, we show you how to efficiently process partitioned datasets using aws glue. You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers, or using aws glue etl jobs. When you create a partition. Partition Key Aws Glue.
From hassaanbinaslam.github.io
Random Thoughts Working with partition indexes in AWS Glue Partition Key Aws Glue Jobname = args['job_name'] #header is a spark. In aws glue, table definitions include the partitioning key of a table. When aws glue evaluates the data in amazon s3 folders to. First, we cover how to set up a crawler to automatically scan your. To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can. Partition Key Aws Glue.
From awstip.com
Automatically add partitions to AWS Glue using Node/Lambda only by Partition Key Aws Glue To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. Jobname = args['job_name'] #header is a spark. When aws glue evaluates the data in amazon s3 folders to. When you create a partition index, you specify a list of partition keys that already exist on a. Partition Key Aws Glue.
From hassaanbinaslam.github.io
Random Thoughts Working with partition indexes in AWS Glue Partition Key Aws Glue In aws glue, table definitions include the partitioning key of a table. To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. In this post, we show you how to efficiently process partitioned datasets using aws glue. Jobname = args['job_name'] #header is a spark. First, we. Partition Key Aws Glue.
From www.jetbrains.com
AWS Glue PyCharm Documentation Partition Key Aws Glue In this post, we show you how to efficiently process partitioned datasets using aws glue. First, we cover how to set up a crawler to automatically scan your. Jobname = args['job_name'] #header is a spark. To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. You. Partition Key Aws Glue.
From hassaanbinaslam.github.io
Random Thoughts Working with partition indexes in AWS Glue Partition Key Aws Glue First, we cover how to set up a crawler to automatically scan your. In this post, we show you how to efficiently process partitioned datasets using aws glue. When you create a partition index, you specify a list of partition keys that already exist on a given table. To speed up query processing of highly partitioned tables cataloged in aws. Partition Key Aws Glue.
From aws.amazon.com
Get started managing partitions for Amazon S3 tables backed by the AWS Partition Key Aws Glue When you create a partition index, you specify a list of partition keys that already exist on a given table. I am able to write to parquet format and partitioned by a column like so: You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers, or using. Partition Key Aws Glue.
From www.youtube.com
AWS Glue Write Parquet With Partitions to AWS S3 YouTube Partition Key Aws Glue In aws glue, table definitions include the partitioning key of a table. List of partition key values that define the partition to update. First, we cover how to set up a crawler to automatically scan your. When aws glue evaluates the data in amazon s3 folders to. I am able to write to parquet format and partitioned by a column. Partition Key Aws Glue.
From devcodef1.com
AWS Glue Force crawler to not create partitions based on S3 subfolders Partition Key Aws Glue To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. List of partition key values that define the partition to update. First, we cover how to set up a crawler to automatically scan your. In aws glue, table definitions include the partitioning key of a table.. Partition Key Aws Glue.
From thecodinginterface.com
Managing S3 Data Store Partitions with AWS Glue Crawlers and Glue Partition Key Aws Glue To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. First, we cover how to set up a crawler to automatically scan your. List of partition key values that define the partition to update. When aws glue evaluates the data in amazon s3 folders to. In. Partition Key Aws Glue.
From stackoverflow.com
amazon web services aws Dynamodb get multiple items by partition key Partition Key Aws Glue Jobname = args['job_name'] #header is a spark. To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. First, we cover how to set up a crawler to automatically scan your. I am able to write to parquet format and partitioned by a column like so: List. Partition Key Aws Glue.
From joizfnjer.blob.core.windows.net
Partition Key Guid at Grace Jones blog Partition Key Aws Glue When you create a partition index, you specify a list of partition keys that already exist on a given table. I am able to write to parquet format and partitioned by a column like so: To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. Jobname. Partition Key Aws Glue.
From aws.amazon.com
Use AWS Glue ETL to perform merge, partition evolution, and schema Partition Key Aws Glue You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers, or using aws glue etl jobs. In aws glue, table definitions include the partitioning key of a table. To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage. Partition Key Aws Glue.
From thecodinginterface.com
Managing S3 Data Store Partitions with AWS Glue Crawlers and Glue Partition Key Aws Glue In aws glue, table definitions include the partitioning key of a table. In this post, we show you how to efficiently process partitioned datasets using aws glue. You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers, or using aws glue etl jobs. When you create a. Partition Key Aws Glue.
From thecodinginterface.com
Managing S3 Data Store Partitions with AWS Glue Crawlers and Glue Partition Key Aws Glue I am able to write to parquet format and partitioned by a column like so: In aws glue, table definitions include the partitioning key of a table. When you create a partition index, you specify a list of partition keys that already exist on a given table. List of partition key values that define the partition to update. When aws. Partition Key Aws Glue.
From noise.getoto.net
Get started managing partitions for Amazon S3 tables backed by the AWS Partition Key Aws Glue First, we cover how to set up a crawler to automatically scan your. When aws glue evaluates the data in amazon s3 folders to. I am able to write to parquet format and partitioned by a column like so: List of partition key values that define the partition to update. Jobname = args['job_name'] #header is a spark. In this post,. Partition Key Aws Glue.
From aws.amazon.com
Use AWS Glue ETL to perform merge, partition evolution, and schema Partition Key Aws Glue Jobname = args['job_name'] #header is a spark. You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers, or using aws glue etl jobs. When aws glue evaluates the data in amazon s3 folders to. In this post, we show you how to efficiently process partitioned datasets using. Partition Key Aws Glue.
From aws.amazon.com
Get started managing partitions for Amazon S3 tables backed by the AWS Partition Key Aws Glue I am able to write to parquet format and partitioned by a column like so: Jobname = args['job_name'] #header is a spark. First, we cover how to set up a crawler to automatically scan your. To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. In. Partition Key Aws Glue.
From aws.amazon.com
Get started managing partitions for Amazon S3 tables backed by the AWS Partition Key Aws Glue When you create a partition index, you specify a list of partition keys that already exist on a given table. To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. Jobname = args['job_name'] #header is a spark. You can create tables and partitions directly using the. Partition Key Aws Glue.
From medium.com
Add new partitions in AWS Glue Data Catalog from AWS Glue Job by Partition Key Aws Glue In this post, we show you how to efficiently process partitioned datasets using aws glue. You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers, or using aws glue etl jobs. When aws glue evaluates the data in amazon s3 folders to. Jobname = args['job_name'] #header is. Partition Key Aws Glue.
From docs.aws.amazon.com
AWS Glue Concepts AWS Glue Partition Key Aws Glue List of partition key values that define the partition to update. In this post, we show you how to efficiently process partitioned datasets using aws glue. In aws glue, table definitions include the partitioning key of a table. When you create a partition index, you specify a list of partition keys that already exist on a given table. When aws. Partition Key Aws Glue.
From docs.aws.amazon.com
Partitions and data distribution Amazon DynamoDB Partition Key Aws Glue List of partition key values that define the partition to update. Jobname = args['job_name'] #header is a spark. To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. I am able to write to parquet format and partitioned by a column like so: First, we cover. Partition Key Aws Glue.
From docs.aws.amazon.com
Partitions and data distribution Amazon DynamoDB Partition Key Aws Glue First, we cover how to set up a crawler to automatically scan your. I am able to write to parquet format and partitioned by a column like so: In aws glue, table definitions include the partitioning key of a table. When aws glue evaluates the data in amazon s3 folders to. When you create a partition index, you specify a. Partition Key Aws Glue.
From creatortechs.com
Effectively crawl your knowledge lake and enhance knowledge entry with Partition Key Aws Glue In aws glue, table definitions include the partitioning key of a table. You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers, or using aws glue etl jobs. When you create a partition index, you specify a list of partition keys that already exist on a given. Partition Key Aws Glue.
From aws.amazon.com
Use AWS Glue ETL to perform merge, partition evolution, and schema Partition Key Aws Glue In aws glue, table definitions include the partitioning key of a table. I am able to write to parquet format and partitioned by a column like so: First, we cover how to set up a crawler to automatically scan your. Jobname = args['job_name'] #header is a spark. To speed up query processing of highly partitioned tables cataloged in aws glue. Partition Key Aws Glue.
From hassaanbinaslam.github.io
Random Thoughts Working with partition indexes in AWS Glue Partition Key Aws Glue You can create tables and partitions directly using the aws glue api, sdks, aws cli, ddl queries on athena, using aws glue crawlers, or using aws glue etl jobs. To speed up query processing of highly partitioned tables cataloged in aws glue data catalog, you can take advantage of aws glue partition indexes. In aws glue, table definitions include the. Partition Key Aws Glue.