https://openreview.net/forum?id=RlVTYWhsky7
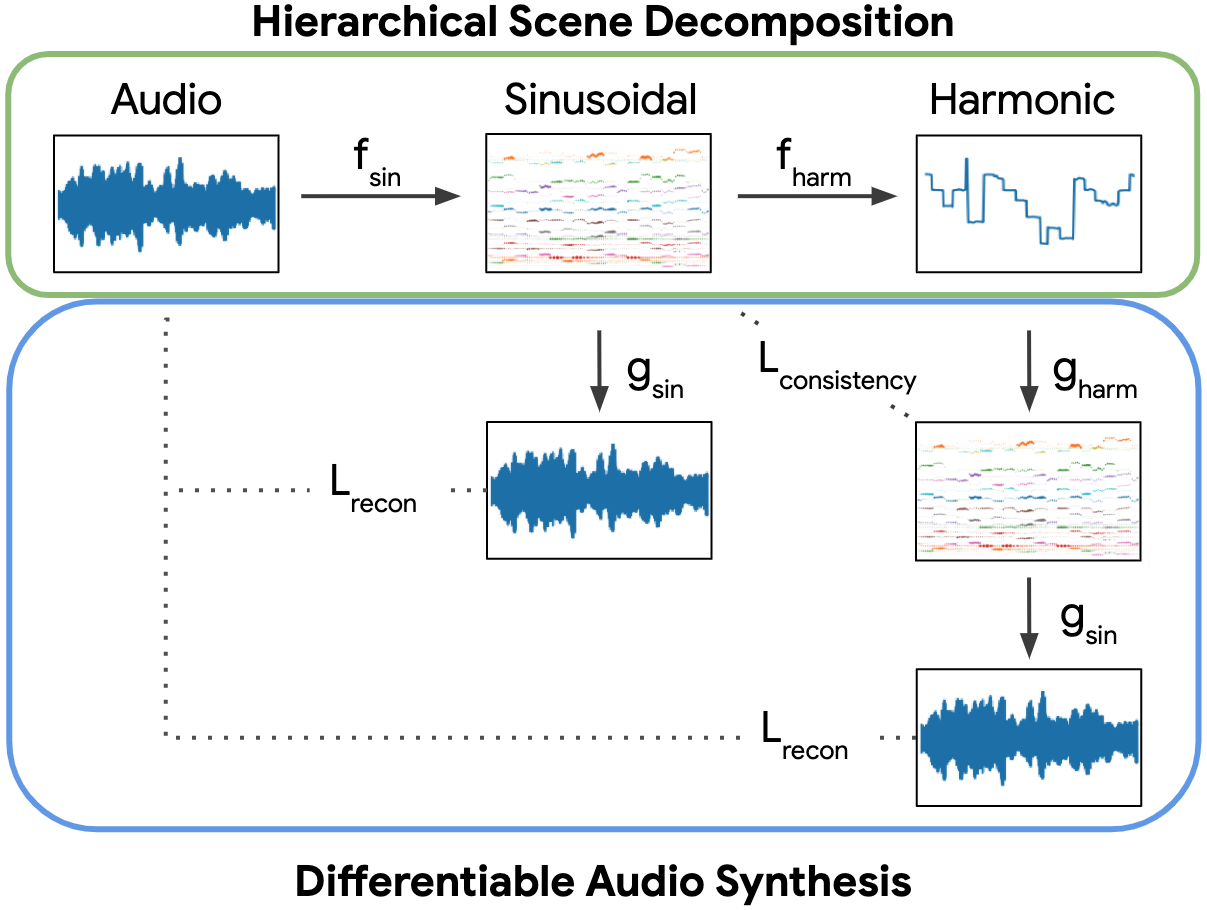
In this work, we demonstrate that DDSP modules can enable a new approach to self-supervision, generating synthetic audio with differentiable synthesizers and training feature extractor networks to infer the synthesis parameters. By building a hierarchy from sinusoidal to harmonic representations, we show that it possible to use such an inverse modeling approach to disentangle pitch from timbre, an important task in audio scene understanding. Differentiable Digital Signal Procressing (DDSP) enables direct integration of classic signal processing elements with end-to-end learning, utilizing strong inductive biases without sacrificing the expressive power of neural networks. This approach enables high-fidelity audio synthesis without the need for large autoregressive models or adversarial losses, and permits interpretable manipulation of each separate model component. In all figures below, linear-frequency log-magnitude spectrograms are used to visualize the audio, which is synthesized with a sample rate of 16kHz.
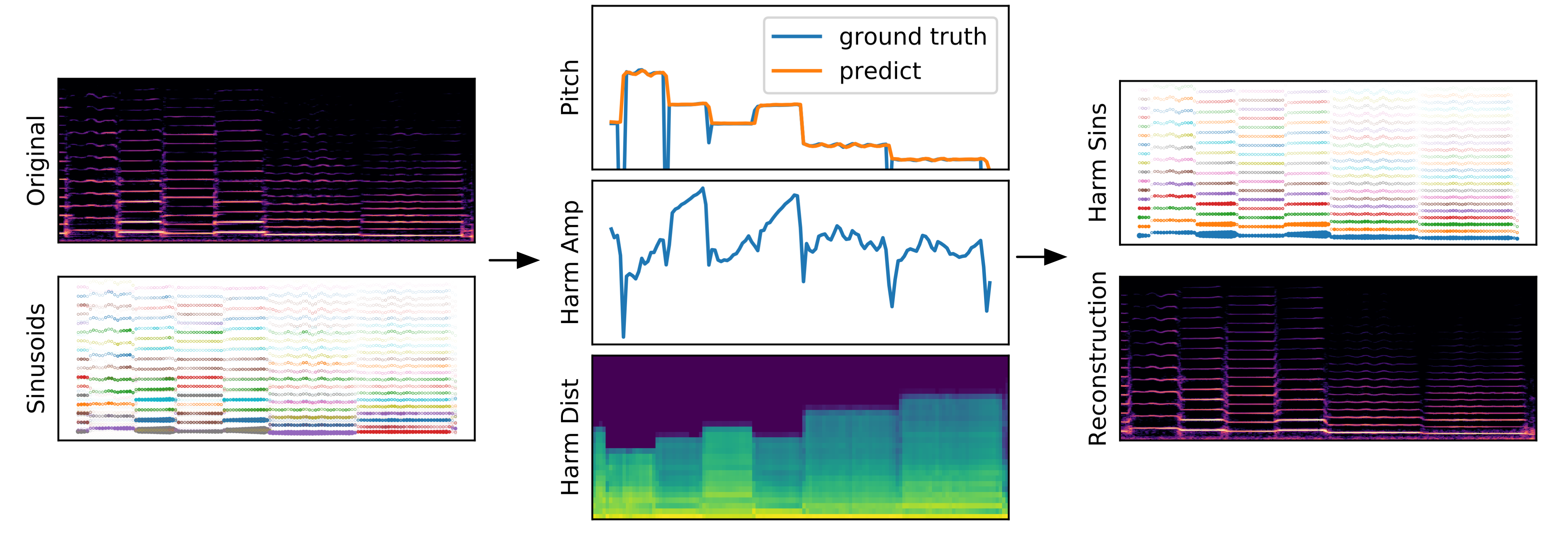
Hierarchical decomposition of a sample from the URMP dataset. Left: spectrogram of audio and encoded sinusoidal traces. Center: harmonic components including fundamental frequency, amplitude, and distribution of the harmonics. Right: sinusoids decoded from harmonic components and spectrogram of reconstructed audio. While the harmonic reconstruction lacks some of the spectral richness of the orginal, it still estimates the correct fundamental frequency.
 |
||
| Original Audio | Sinusoidal Reconstruction | Harmonic Reconstruction |
The DDSP Autoencoder model uses a CREPE model to extract fundamental frequency. Example spectrograms of synthetic data. Notes are first given random lengths and fundamental frequency, with a possibility of being silent. Notes are then given a random amplitude, harmonic distribution, noise distribution at their start and end, and interpolated between. Additional vibrato and parameter noise is then added. Parameters were tuned until the authors subjectively felt that it produced a cool diversity of sounds, even if not particularly realistic.
Warning, LOUD AUDIO!
 |
 |
 |
 |