https://openreview.net/forum?id=B1x1ma4tDr
Differentiable Digital Signal Procressing (DDSP) enables direct integration of classic signal processing elements with end-to-end learning, utilizing strong inductive biases without sacrificing the expressive power of neural networks. This approach enables high-fidelity audio synthesis without the need for large autoregressive models or adversarial losses, and permits interpretable manipulation of each separate model component. In all figures below, linear-frequency log-magnitude spectrograms are used to visualize the audio, which is synthesized with a sample rate of 16kHz.
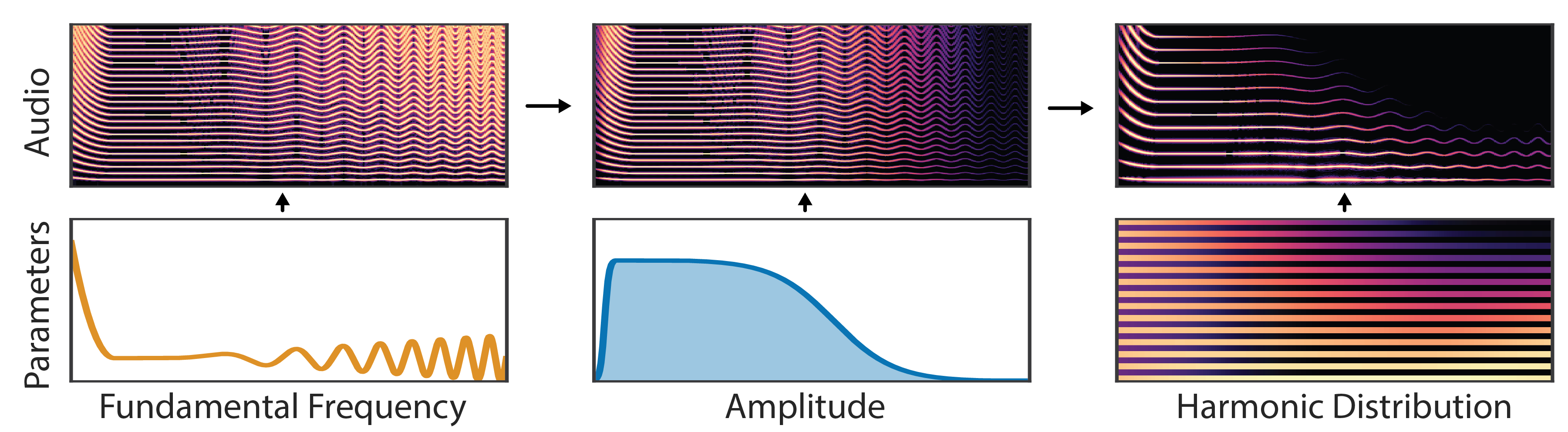
The additive synthesizer generates audio as a sum of sinusoids at harmonic (integer) multiples of the fundamental frequency. A neural network feeds the synthesizer parameters (fundamental frequency, amplitude, harmonic distribution). Harmonics follow the frequency contours of the fundamental, loudness is controlled by the amplitude envelope, and spectral structure is determined by the the harmonic distribution.
 |
||
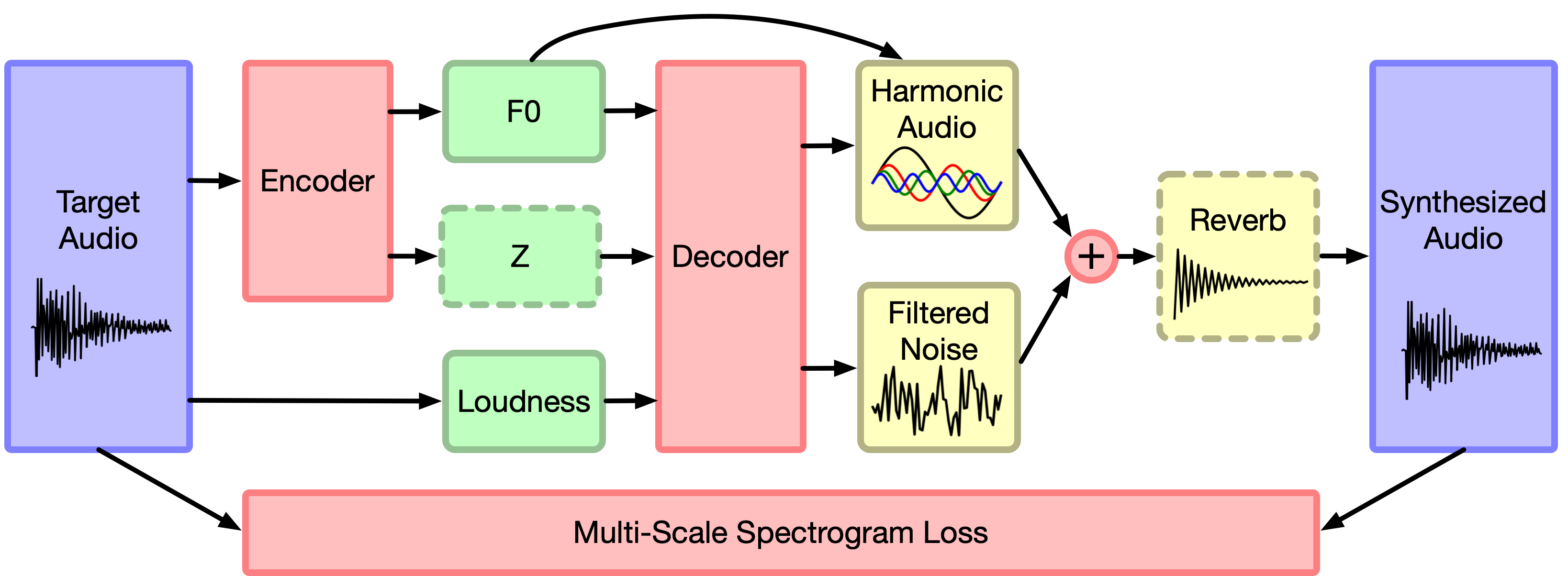
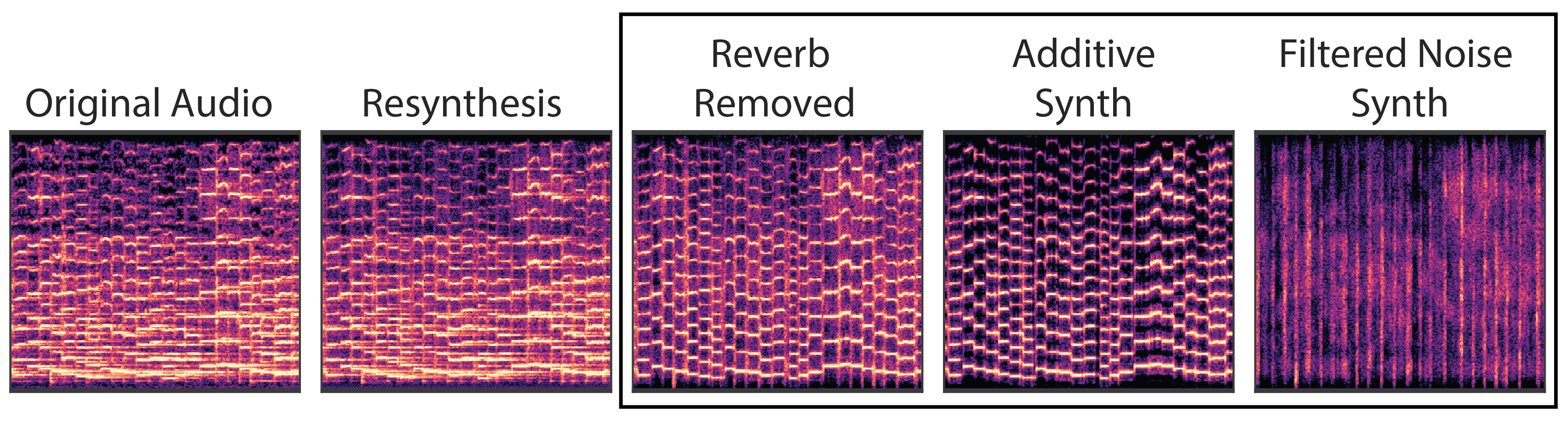
We train a DDSP decoder on a datset of violin performances, resynthesizing audio from loudness and fundamental frequency extracted from the original audio. First, we note that resynthesis is realistic and perceptually very similar to the original audio. The decoder feeds into an additve synthesizer and filtered noise synthesizer, whose outputs are summed before running through a reverb module. Since each the model is composed of interpretable modules, we can examine that audio output from each module to find a modular decomposition of the original audio signals.
 |
|||||
| Additive Synthesizer Parameters | |||||
 |
|||||
| Noise Synthesizer and Reverb Parameters | |||||
 |
|||||
Timbre transfer from singing voice to violin. F0 and loudness features are extracted from the voice and resynthesized with a DDSP decoder trained on solo violin. To better match the conditioning features, we first shift the fundamental frequency of the singing up by two octaves to fit a violin’s typical register. The resulting audio captures many subtleties of the singing with the timbre and room acoustics of the violin dataset. Note the interesting “breathing” artifacts in the silence corresponding to unvoiced syllables from the singing

|

|
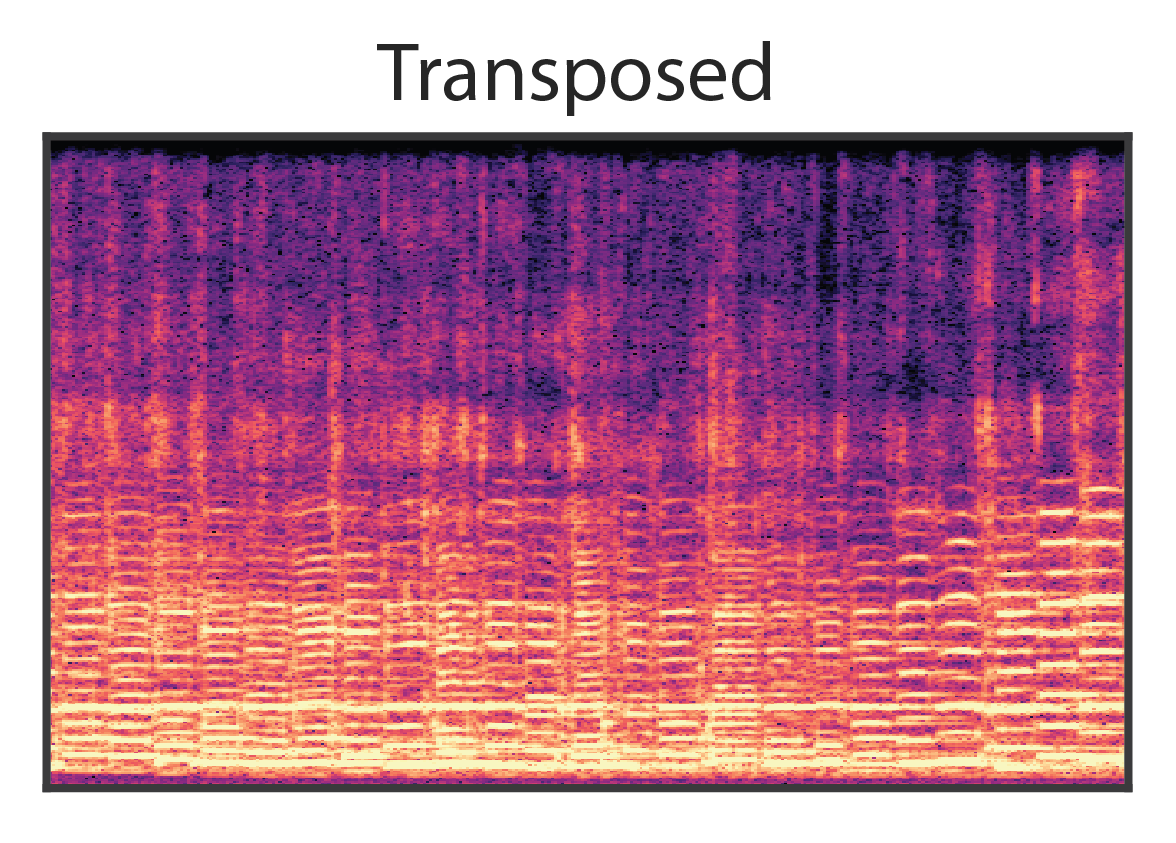
Besides feeding the decoder, the fundamental frequency directly controls the additive synthesizer and has structural meaning outside the context of any given dataset. Beyond interpolating between datapoints, this inductive bias enables the model to extrapolate to new conditions not seen during training. Here, we shift resynthesize audio from the solo violin model after transposing the fundamental frequency down an octave and outside the range of the training data. The audio remains coherent and resembles a related instrument such as a cello.
|
|
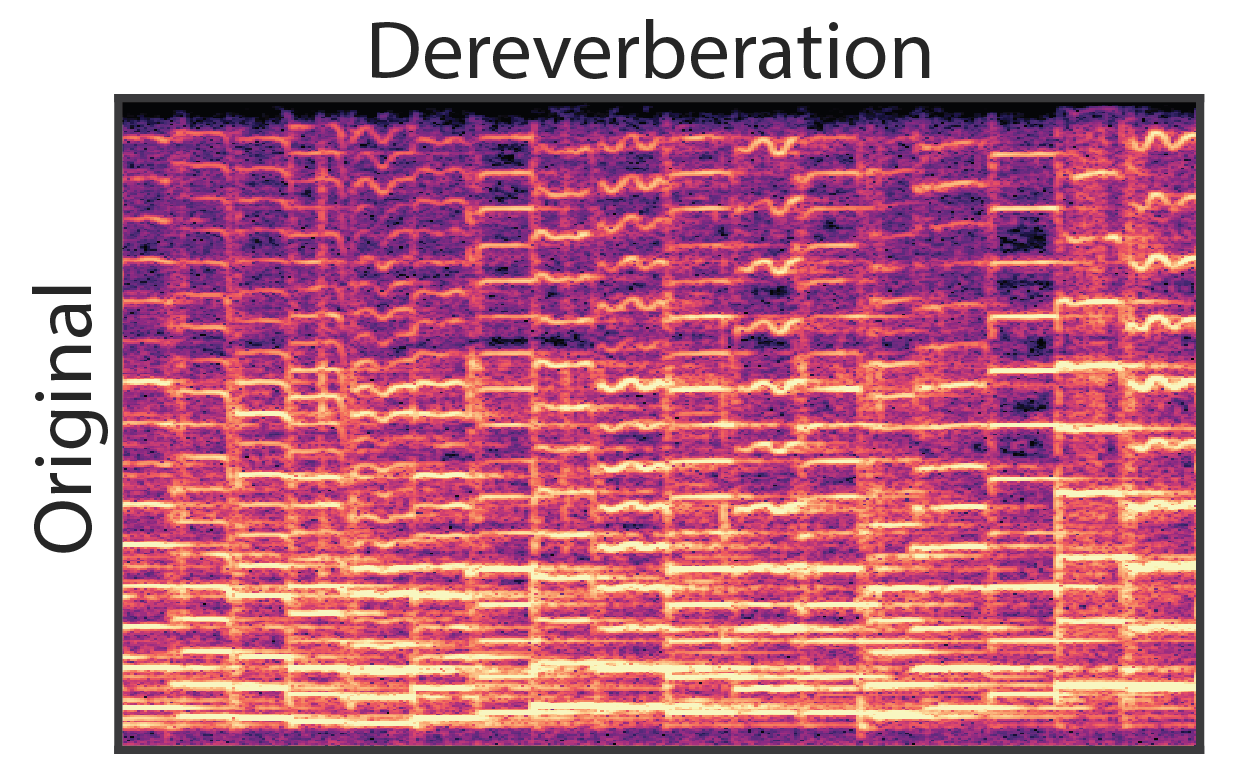
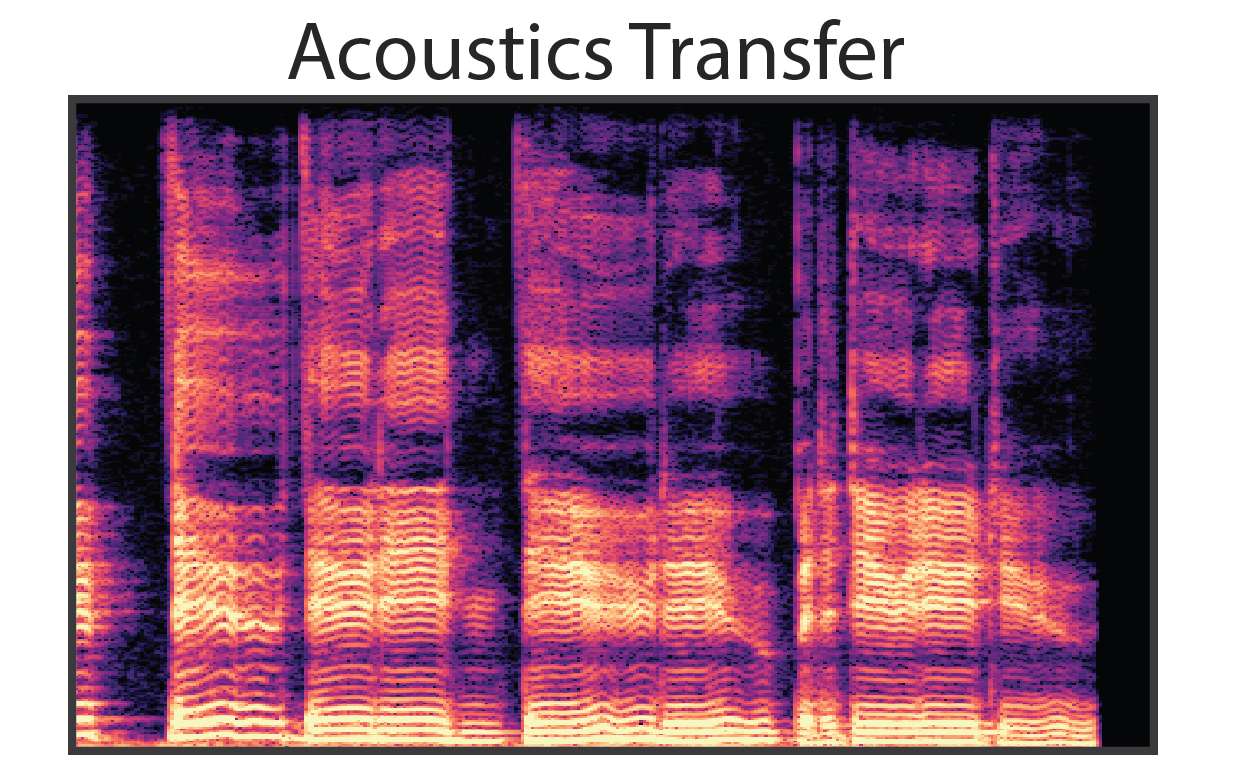
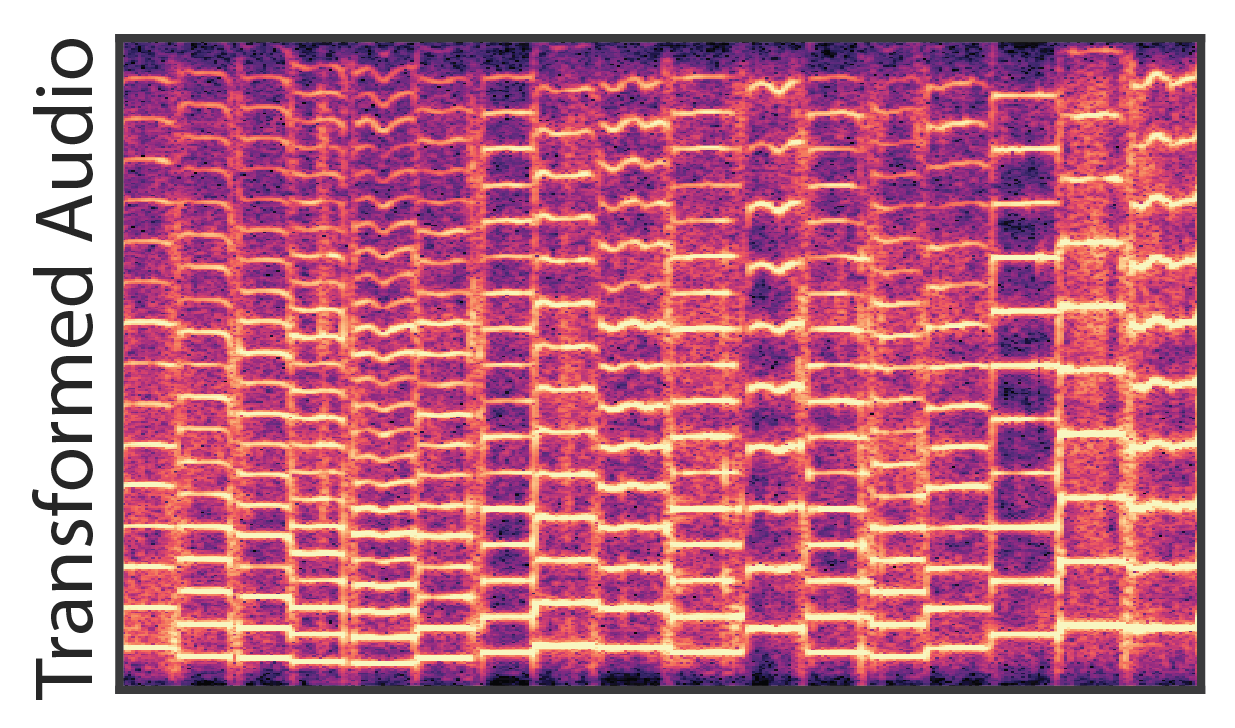
As seen above, a benefit of our modular approach to generative modeling is that it becomes possible to completely separate the source audio from the effect of the room. Bypassing the reverb module during resynthesis results in completely dereverberated audio, similar to recording in an anechoic chamber. We can also apply the learned reverb model to new audio, in this case singing, and effectively transfer the acoustic environment of the solo violin recordings.
|
|
|
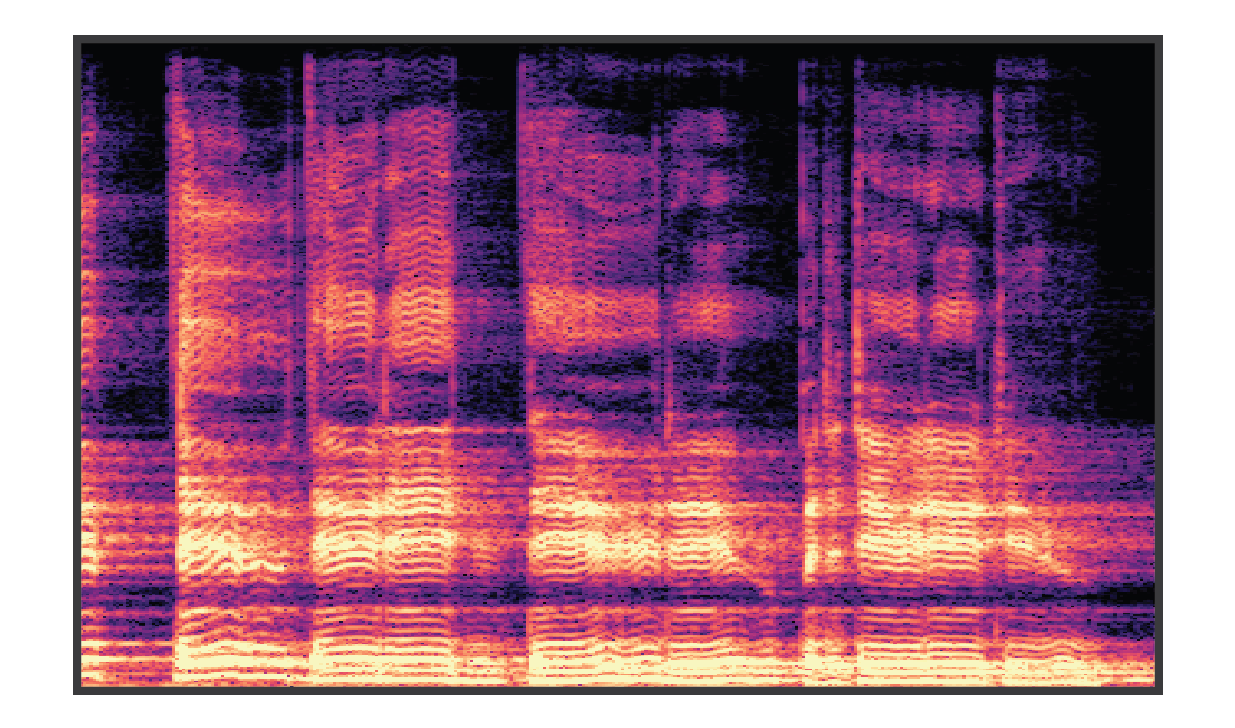
|
|
Note that the dereverberated audio sounds almost unnatural, as most environments always have some amount of acoustic reflections. To make convey the quality of the dereverberation, we apply two new reverberations, effectively transforming the acoustic environment of the original recording. |
|
Separate interpolations over loudness, pitch, and timbre. The conditioning features (solid lines) are extracted from two notes and linearly mixed (dark to light coloring). The features of the resynthsized audio (dashed lines) closely follow the conditioning. On the right, the latent vectors,
 |
|||
| A Original | |||
| A Reconstruction | |||
| 0% | |||
| 25% | |||
| 50% | |||
| 75% | |||
| 100% | |||
| B Reconstruction | |||
| B Original | |||
The maximum likelihood loss of autoregressive waveform models is imperfect because a waveform's shape does not perfectly correspond to perception. For example, the three waveforms below sound identical (a relative phase offset of the harmonics) but would present different losses to an autoregressive model.

|
|

|
|

|
|
While the original models were not optimized for size, initial experiments are promising in scaling down for realtime aplications. The "tiny" model below is a single 256 unit GRU trained on the solo violin dataset and performing timbre transfer.
| Baseline (~6M parameters) | Tiny (~240k parameters) |
The DDSP Autoencoder model uses a CREPE model to extract fundamental frequency. The supervised variant uses pretrained weights that are fixed during training, while the unsupervised variant learns the weights jointly with the rest of the network. The unsupervised model learns to generate the correct frequency, but with less timbral accuracy due to the increased difficulty of the task.
| Original | ||||
| Supervised | ||||
| Unsupervised |