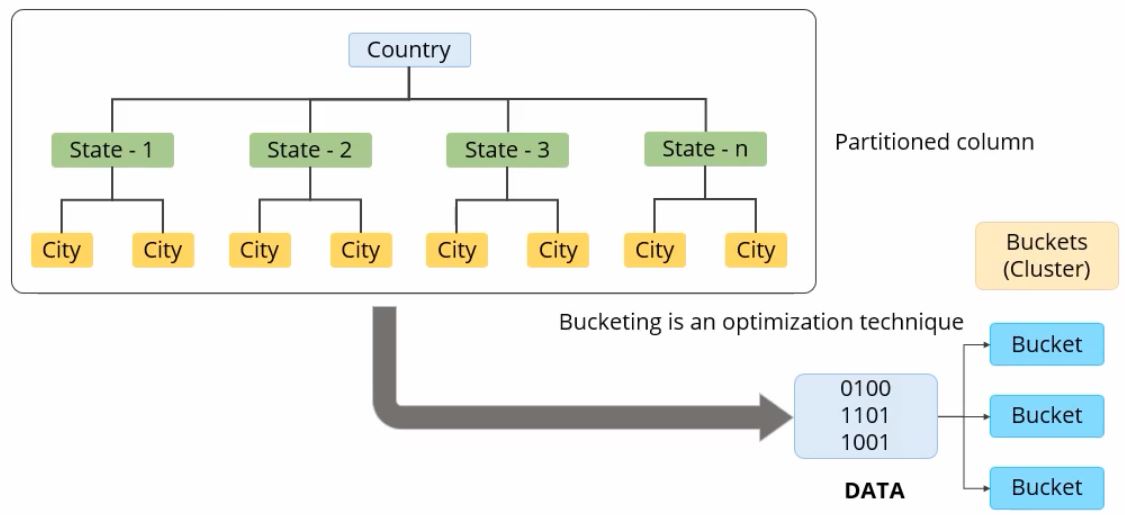
Bucket Join Hive . To enable a bucket map join, we need to enable the following. Tables being joined are bucketized on the join columns, the number of buckets in one table is a. Hive on spark supports automatic bucket mapjoin, which is not supported in mapreduce. A bucket map join is a special type of map join applied on the bucket tables. In this recipe, you will learn how to use a bucket map join in hive. Prerequisites for bucket map join: A bucket map join is used when the tables are large and all the tables used in. A bucket sort merge map join is an advanced version of a bucket. This is done in extra logic via. If both tables have the same amount of buckets and the data is sorted by the bucket keys, hive can perform the faster sort. If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b. In this recipe, you will learn how to use a bucket sort merge map join in hive.
from www.simplilearn.com
If both tables have the same amount of buckets and the data is sorted by the bucket keys, hive can perform the faster sort. To enable a bucket map join, we need to enable the following. If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b. A bucket map join is a special type of map join applied on the bucket tables. In this recipe, you will learn how to use a bucket sort merge map join in hive. Tables being joined are bucketized on the join columns, the number of buckets in one table is a. Hive on spark supports automatic bucket mapjoin, which is not supported in mapreduce. Prerequisites for bucket map join: A bucket sort merge map join is an advanced version of a bucket. In this recipe, you will learn how to use a bucket map join in hive.
Advanced Hive Concepts and Data File Partitioning Tutorial Simplilearn
Bucket Join Hive A bucket map join is a special type of map join applied on the bucket tables. In this recipe, you will learn how to use a bucket map join in hive. Tables being joined are bucketized on the join columns, the number of buckets in one table is a. A bucket map join is used when the tables are large and all the tables used in. Prerequisites for bucket map join: A bucket sort merge map join is an advanced version of a bucket. A bucket map join is a special type of map join applied on the bucket tables. If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b. If both tables have the same amount of buckets and the data is sorted by the bucket keys, hive can perform the faster sort. In this recipe, you will learn how to use a bucket sort merge map join in hive. This is done in extra logic via. To enable a bucket map join, we need to enable the following. Hive on spark supports automatic bucket mapjoin, which is not supported in mapreduce.
From data-flair.training
Sort Merge Bucket Join in Hive SMB Join DataFlair Bucket Join Hive Prerequisites for bucket map join: A bucket map join is used when the tables are large and all the tables used in. A bucket map join is a special type of map join applied on the bucket tables. This is done in extra logic via. To enable a bucket map join, we need to enable the following. Hive on spark. Bucket Join Hive.
From www.cnblogs.com
Hive 的 Join guoyu1 博客园 Bucket Join Hive Hive on spark supports automatic bucket mapjoin, which is not supported in mapreduce. Tables being joined are bucketized on the join columns, the number of buckets in one table is a. A bucket sort merge map join is an advanced version of a bucket. If table a has 4 buckets and table b has 4 buckets, the following join select. Bucket Join Hive.
From blog.csdn.net
通俗易懂的Hive join几种形式原理详解_hive join原理CSDN博客 Bucket Join Hive This is done in extra logic via. If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b. Tables being joined are bucketized on the join columns, the number of buckets in one table is a. In this recipe, you will learn how to use a. Bucket Join Hive.
From zhuanlan.zhihu.com
深度剖析Hive GroupBy,Distinct 与 Join 原理 知乎 Bucket Join Hive Hive on spark supports automatic bucket mapjoin, which is not supported in mapreduce. In this recipe, you will learn how to use a bucket map join in hive. A bucket sort merge map join is an advanced version of a bucket. Prerequisites for bucket map join: A bucket map join is a special type of map join applied on the. Bucket Join Hive.
From bigdataschool.ru
Поддержка оптимизации JOIN операций в Apache Hive SQL Bucket Join Hive If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b. If both tables have the same amount of buckets and the data is sorted by the bucket keys, hive can perform the faster sort. Tables being joined are bucketized on the join columns, the number. Bucket Join Hive.
From data-flair.training
Hive Join HiveQL Select Joins Query Types of Join in Hive DataFlair Bucket Join Hive In this recipe, you will learn how to use a bucket map join in hive. A bucket map join is used when the tables are large and all the tables used in. Tables being joined are bucketized on the join columns, the number of buckets in one table is a. Prerequisites for bucket map join: A bucket map join is. Bucket Join Hive.
From data-flair.training
Map Join in Hive Map Side Join DataFlair Bucket Join Hive In this recipe, you will learn how to use a bucket sort merge map join in hive. A bucket map join is a special type of map join applied on the bucket tables. Tables being joined are bucketized on the join columns, the number of buckets in one table is a. A bucket map join is used when the tables. Bucket Join Hive.
From www.educba.com
Bucketing in Hive Complete Guide to Bucketing in Hive Bucket Join Hive This is done in extra logic via. In this recipe, you will learn how to use a bucket sort merge map join in hive. To enable a bucket map join, we need to enable the following. In this recipe, you will learn how to use a bucket map join in hive. Prerequisites for bucket map join: A bucket sort merge. Bucket Join Hive.
From blog.csdn.net
【大数据】Hive Join 的原理与机制_hive join的执行原理CSDN博客 Bucket Join Hive In this recipe, you will learn how to use a bucket map join in hive. A bucket sort merge map join is an advanced version of a bucket. If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b. In this recipe, you will learn how. Bucket Join Hive.
From www.simplilearn.com
Advanced Hive Concepts and Data File Partitioning Tutorial Simplilearn Bucket Join Hive Hive on spark supports automatic bucket mapjoin, which is not supported in mapreduce. A bucket sort merge map join is an advanced version of a bucket. Tables being joined are bucketized on the join columns, the number of buckets in one table is a. A bucket map join is used when the tables are large and all the tables used. Bucket Join Hive.
From mavink.com
Hive Join Diagrams Bucket Join Hive If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b. To enable a bucket map join, we need to enable the following. A bucket map join is a special type of map join applied on the bucket tables. This is done in extra logic via.. Bucket Join Hive.
From sungwookkang.com
Hive MapSideJoin, BucketMapJoin, SortMergeJoin Bucket Join Hive If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b. Hive on spark supports automatic bucket mapjoin, which is not supported in mapreduce. A bucket map join is used when the tables are large and all the tables used in. Prerequisites for bucket map join:. Bucket Join Hive.
From medium.com
Partitioning & Bucketing in Hive. Partition & Bucket in Hive by Bucket Join Hive In this recipe, you will learn how to use a bucket sort merge map join in hive. A bucket map join is a special type of map join applied on the bucket tables. To enable a bucket map join, we need to enable the following. Tables being joined are bucketized on the join columns, the number of buckets in one. Bucket Join Hive.
From www.educba.com
Map Join in Hive Query Examples with the Advantages and Limitations Bucket Join Hive In this recipe, you will learn how to use a bucket map join in hive. A bucket sort merge map join is an advanced version of a bucket. If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b. A bucket map join is a special. Bucket Join Hive.
From www.scribd.com
Optimizing Hive Join Performance Understanding MapSide Joins, Reduce Bucket Join Hive To enable a bucket map join, we need to enable the following. If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b. In this recipe, you will learn how to use a bucket map join in hive. Tables being joined are bucketized on the join. Bucket Join Hive.
From www.youtube.com
Hive Inner Join, Right Outer Join, Map side Join YouTube Bucket Join Hive A bucket sort merge map join is an advanced version of a bucket. If both tables have the same amount of buckets and the data is sorted by the bucket keys, hive can perform the faster sort. To enable a bucket map join, we need to enable the following. In this recipe, you will learn how to use a bucket. Bucket Join Hive.
From data-flair.training
Bucket Map Join in Hive Tips & Working DataFlair Bucket Join Hive A bucket map join is used when the tables are large and all the tables used in. In this recipe, you will learn how to use a bucket sort merge map join in hive. If both tables have the same amount of buckets and the data is sorted by the bucket keys, hive can perform the faster sort. Hive on. Bucket Join Hive.
From data-flair.training
Sort Merge Bucket Join in Hive SMB Join DataFlair Bucket Join Hive A bucket map join is used when the tables are large and all the tables used in. In this recipe, you will learn how to use a bucket map join in hive. In this recipe, you will learn how to use a bucket sort merge map join in hive. To enable a bucket map join, we need to enable the. Bucket Join Hive.
From data-flair.training
Skew Join in Hive Working, Tips & Examples DataFlair Bucket Join Hive In this recipe, you will learn how to use a bucket sort merge map join in hive. A bucket map join is a special type of map join applied on the bucket tables. This is done in extra logic via. In this recipe, you will learn how to use a bucket map join in hive. A bucket sort merge map. Bucket Join Hive.
From www.hadoopdoc.com
Hive bucket map join Hive 教程 Bucket Join Hive A bucket sort merge map join is an advanced version of a bucket. Hive on spark supports automatic bucket mapjoin, which is not supported in mapreduce. If both tables have the same amount of buckets and the data is sorted by the bucket keys, hive can perform the faster sort. If table a has 4 buckets and table b has. Bucket Join Hive.
From data-flair.training
Hive Join HiveQL Select Joins Query Types of Join in Hive DataFlair Bucket Join Hive If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b. A bucket sort merge map join is an advanced version of a bucket. Tables being joined are bucketized on the join columns, the number of buckets in one table is a. A bucket map join. Bucket Join Hive.
From data-flair.training
Bucket Map Join in Hive Tips & Working DataFlair Bucket Join Hive A bucket sort merge map join is an advanced version of a bucket. Prerequisites for bucket map join: Hive on spark supports automatic bucket mapjoin, which is not supported in mapreduce. Tables being joined are bucketized on the join columns, the number of buckets in one table is a. This is done in extra logic via. A bucket map join. Bucket Join Hive.
From www.javatpoint.com
Bucketing in Hive javatpoint Bucket Join Hive A bucket sort merge map join is an advanced version of a bucket. If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b. In this recipe, you will learn how to use a bucket map join in hive. A bucket map join is a special. Bucket Join Hive.
From data-flair.training
Skew Join in Hive Working, Tips & Examples DataFlair Bucket Join Hive Prerequisites for bucket map join: If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b. A bucket map join is a special type of map join applied on the bucket tables. A bucket sort merge map join is an advanced version of a bucket. If. Bucket Join Hive.
From www.hadoop.ca
Hive Hadoop Canada Bucket Join Hive To enable a bucket map join, we need to enable the following. A bucket map join is used when the tables are large and all the tables used in. Tables being joined are bucketized on the join columns, the number of buckets in one table is a. In this recipe, you will learn how to use a bucket map join. Bucket Join Hive.
From bigdataschool.ru
Поддержка оптимизации JOIN операций в Apache Hive SQL Bucket Join Hive Prerequisites for bucket map join: In this recipe, you will learn how to use a bucket sort merge map join in hive. Hive on spark supports automatic bucket mapjoin, which is not supported in mapreduce. This is done in extra logic via. If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b). Bucket Join Hive.
From www.youtube.com
map join, skew join, sort merge bucket join in hive YouTube Bucket Join Hive If both tables have the same amount of buckets and the data is sorted by the bucket keys, hive can perform the faster sort. A bucket map join is a special type of map join applied on the bucket tables. In this recipe, you will learn how to use a bucket sort merge map join in hive. A bucket map. Bucket Join Hive.
From mapsforyoufree.blogspot.com
Map Side Join In Hive Maping Resources Bucket Join Hive A bucket map join is used when the tables are large and all the tables used in. Hive on spark supports automatic bucket mapjoin, which is not supported in mapreduce. Tables being joined are bucketized on the join columns, the number of buckets in one table is a. If both tables have the same amount of buckets and the data. Bucket Join Hive.
From blog.csdn.net
Hive分区表和分桶表_hdfs bucketCSDN博客 Bucket Join Hive A bucket map join is used when the tables are large and all the tables used in. A bucket sort merge map join is an advanced version of a bucket. Prerequisites for bucket map join: If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b.. Bucket Join Hive.
From zhuanlan.zhihu.com
Hive学习笔记十一:Hive表设计优化 知乎 Bucket Join Hive Prerequisites for bucket map join: In this recipe, you will learn how to use a bucket map join in hive. Hive on spark supports automatic bucket mapjoin, which is not supported in mapreduce. Tables being joined are bucketized on the join columns, the number of buckets in one table is a. In this recipe, you will learn how to use. Bucket Join Hive.
From henning.kropponline.de
Hive Join Strategies Bucket Join Hive If table a has 4 buckets and table b has 4 buckets, the following join select /*+ mapjoin(b) */ a.key, a.value from a join b. Hive on spark supports automatic bucket mapjoin, which is not supported in mapreduce. In this recipe, you will learn how to use a bucket sort merge map join in hive. Prerequisites for bucket map join:. Bucket Join Hive.
From data-flair.training
Map Join in Hive Map Side Join DataFlair Bucket Join Hive Prerequisites for bucket map join: A bucket sort merge map join is an advanced version of a bucket. In this recipe, you will learn how to use a bucket map join in hive. To enable a bucket map join, we need to enable the following. If both tables have the same amount of buckets and the data is sorted by. Bucket Join Hive.
From sungwookkang.com
Hive MapSideJoin, BucketMapJoin, SortMergeJoin Bucket Join Hive Prerequisites for bucket map join: A bucket sort merge map join is an advanced version of a bucket. In this recipe, you will learn how to use a bucket map join in hive. To enable a bucket map join, we need to enable the following. This is done in extra logic via. A bucket map join is a special type. Bucket Join Hive.
From sqlrelease.com
Understanding Map join in Hive SQLRelease Bucket Join Hive A bucket sort merge map join is an advanced version of a bucket. If both tables have the same amount of buckets and the data is sorted by the bucket keys, hive can perform the faster sort. To enable a bucket map join, we need to enable the following. If table a has 4 buckets and table b has 4. Bucket Join Hive.
From sparkbyexamples.com
Hive Bucketing Explained with Examples Spark By {Examples} Bucket Join Hive A bucket sort merge map join is an advanced version of a bucket. Hive on spark supports automatic bucket mapjoin, which is not supported in mapreduce. In this recipe, you will learn how to use a bucket sort merge map join in hive. Prerequisites for bucket map join: If table a has 4 buckets and table b has 4 buckets,. Bucket Join Hive.