Df Rdd Numpartitions . In the case of scala,. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). Represents an immutable, partitioned collection of elements that can be. Returns the number of partitions in rdd. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. In this method, we are going to find the number of partitions in a data frame using. A resilient distributed dataset (rdd), the basic abstraction in spark.
from blog.csdn.net
You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). Returns the number of partitions in rdd. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. In the case of scala,. Represents an immutable, partitioned collection of elements that can be. In this method, we are going to find the number of partitions in a data frame using. A resilient distributed dataset (rdd), the basic abstraction in spark. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names.
在spark shell中完成RDD基本操作_如何使用spark shell执行一个简单的spark操作(如计算两个rdd的和)CSDN博客
Df Rdd Numpartitions Represents an immutable, partitioned collection of elements that can be. A resilient distributed dataset (rdd), the basic abstraction in spark. In this method, we are going to find the number of partitions in a data frame using. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. In the case of scala,. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). Represents an immutable, partitioned collection of elements that can be. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. Returns the number of partitions in rdd.
From www.rowcoding.com
Difference between DataFrame, Dataset, and RDD in Spark Row Coding Df Rdd Numpartitions A resilient distributed dataset (rdd), the basic abstraction in spark. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. In this method, we are going to find the number of partitions in a data frame using. Returns the number of partitions in rdd. You. Df Rdd Numpartitions.
From andr-robot.github.io
RDD、DataFrame和DataSet区别 Alpha Carpe diem Df Rdd Numpartitions Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions().. Df Rdd Numpartitions.
From azurelib.com
How to convert RDD to DataFrame in PySpark Azure Databricks? Df Rdd Numpartitions In the case of scala,. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. Represents an immutable, partitioned collection of elements that can be. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. Df Rdd Numpartitions.
From abs-tudelft.github.io
Resilient Distributed Datasets for Big Data Lab Manual Df Rdd Numpartitions A resilient distributed dataset (rdd), the basic abstraction in spark. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). In this method, we are going to find the number of partitions in a data frame using. In the case of scala,. In summary, you can easily find the number of partitions of a dataframe in spark by. Df Rdd Numpartitions.
From matnoble.github.io
图解Spark RDD的五大特性 MatNoble Df Rdd Numpartitions You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). In the case of scala,. In this method, we are going to find the number of partitions in a data frame using. Represents an immutable, partitioned collection of elements that can be. In summary, you can easily find the number of partitions of a dataframe in spark by. Df Rdd Numpartitions.
From blog.csdn.net
pysparkRddgroupbygroupByKeycogroupgroupWith用法_pyspark rdd groupby Df Rdd Numpartitions Represents an immutable, partitioned collection of elements that can be. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. A resilient distributed dataset (rdd), the basic abstraction in spark. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). In this method, we are. Df Rdd Numpartitions.
From www.chegg.com
def compute_counts (rdd, numPartitions = 10) " Df Rdd Numpartitions Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. In this method, we are going to find the number of partitions in a data frame using. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). A resilient distributed dataset (rdd), the. Df Rdd Numpartitions.
From blog.csdn.net
在spark shell中完成RDD基本操作_如何使用spark shell执行一个简单的spark操作(如计算两个rdd的和)CSDN博客 Df Rdd Numpartitions Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. In this method, we are going to find the number of partitions in a data frame using. A resilient distributed dataset (rdd), the basic abstraction in spark. You need to call getnumpartitions() on the dataframe's. Df Rdd Numpartitions.
From sparkbyexamples.com
PySpark Convert DataFrame to RDD Spark By {Examples} Df Rdd Numpartitions Returns the number of partitions in rdd. In this method, we are going to find the number of partitions in a data frame using. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by. Df Rdd Numpartitions.
From algoscale.com
RDD vs Dataframe in Apache Spark Algoscale Df Rdd Numpartitions Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. A resilient distributed dataset (rdd), the basic abstraction in spark. Returns the number of partitions in rdd. Represents an immutable, partitioned collection of elements that can be. In this method, we are going to find. Df Rdd Numpartitions.
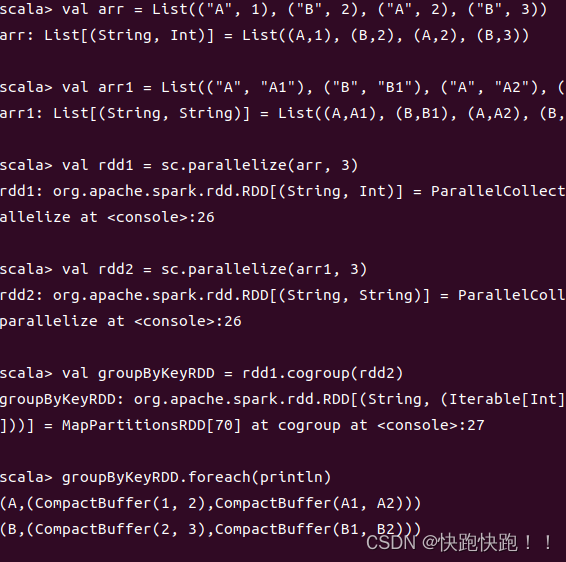
From blog.csdn.net
【Spark】RDD转换算子_case (info(string, string),listiterable[(string,CSDN博客 Df Rdd Numpartitions Returns the number of partitions in rdd. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). In this method, we are going to find the number of partitions in a data frame. Df Rdd Numpartitions.
From slideplayer.com
Architecture of ML Systems 08 Data Access Methods ppt download Df Rdd Numpartitions Returns the number of partitions in rdd. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by. Df Rdd Numpartitions.
From blog.csdn.net
Spark中RDD、DataFrame和DataSet的区别与联系CSDN博客 Df Rdd Numpartitions Represents an immutable, partitioned collection of elements that can be. A resilient distributed dataset (rdd), the basic abstraction in spark. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. Returns the number of partitions in rdd. In the case of scala,. In this method, we are. Df Rdd Numpartitions.
From www.linuxprobe.com
RDD的运行机制 《Linux就该这么学》 Df Rdd Numpartitions Represents an immutable, partitioned collection of elements that can be. Returns the number of partitions in rdd. In the case of scala,. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. In this method, we are going to find the number of partitions in a data. Df Rdd Numpartitions.
From zhuanlan.zhihu.com
RDD(二):RDD算子 知乎 Df Rdd Numpartitions In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. Represents an immutable, partitioned collection of elements that can be. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of. Df Rdd Numpartitions.
From blog.csdn.net
Spark中RDD与DF与DS之间的转换关系_rdd ds df 相互转换CSDN博客 Df Rdd Numpartitions In the case of scala,. In this method, we are going to find the number of partitions in a data frame using. Returns the number of partitions in rdd. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. A resilient distributed dataset (rdd), the basic abstraction. Df Rdd Numpartitions.
From bbs.huaweicloud.com
一零一二、Spark RDDDFDS 相互转换云社区华为云 Df Rdd Numpartitions Returns the number of partitions in rdd. Represents an immutable, partitioned collection of elements that can be. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). In this method, we are going to find the number of partitions in a data frame using. In the case of scala,. Pyspark.sql.dataframe.repartition () method is used to increase or decrease. Df Rdd Numpartitions.
From blog.csdn.net
pyspark udf returnType=ArrayType中是不同数据类型_udf(returntype=arraytype Df Rdd Numpartitions You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. In the case of scala,. Returns the number of partitions in rdd. In this method, we are going to find the number of. Df Rdd Numpartitions.
From www.bigdatainrealworld.com
What is RDD? Big Data In Real World Df Rdd Numpartitions Returns the number of partitions in rdd. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). A resilient distributed dataset (rdd), the basic abstraction in spark. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. Represents an immutable, partitioned collection of. Df Rdd Numpartitions.
From www.youtube.com
How to create partitions in RDD YouTube Df Rdd Numpartitions In the case of scala,. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. A resilient distributed dataset (rdd), the basic abstraction in spark. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. Df Rdd Numpartitions.
From dongkelun.com
Spark 创建RDD、DataFrame各种情况的默认分区数 伦少的博客 Df Rdd Numpartitions You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. A resilient distributed dataset (rdd), the basic abstraction in spark. In the case of scala,. In summary, you can easily find the number. Df Rdd Numpartitions.
From www.youtube.com
What is RDD partitioning YouTube Df Rdd Numpartitions Returns the number of partitions in rdd. Represents an immutable, partitioned collection of elements that can be. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. Pyspark.sql.dataframe.repartition () method is used to increase or. Df Rdd Numpartitions.
From jaegukim.github.io
RDDs vs DataFrames vs Datasets Study Log Df Rdd Numpartitions A resilient distributed dataset (rdd), the basic abstraction in spark. In this method, we are going to find the number of partitions in a data frame using. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. In the case of scala,. Returns the number. Df Rdd Numpartitions.
From www.youtube.com
What is RDD in Spark How to create RDD How to use RDD Apache Df Rdd Numpartitions A resilient distributed dataset (rdd), the basic abstraction in spark. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. Represents an immutable, partitioned collection of elements that can be. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). Pyspark.sql.dataframe.repartition () method is used. Df Rdd Numpartitions.
From giobtyevn.blob.core.windows.net
Df Rdd Getnumpartitions Pyspark at Lee Lemus blog Df Rdd Numpartitions You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). Represents an immutable, partitioned collection of elements that can be. In the case of scala,. A resilient distributed dataset (rdd), the basic abstraction in spark. Returns the number of partitions in rdd. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions. Df Rdd Numpartitions.
From blog.csdn.net
Spark 分区(Partition)的认识、理解和应用法_spark分区的概念CSDN博客 Df Rdd Numpartitions In the case of scala,. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. A resilient distributed dataset (rdd), the basic abstraction in spark. Represents an immutable, partitioned collection of elements that can be.. Df Rdd Numpartitions.
From blog.csdn.net
PySpark中RDD的数据输出详解_pythonrdd打印内容CSDN博客 Df Rdd Numpartitions Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. In the case of scala,. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. Returns the number of partitions in rdd.. Df Rdd Numpartitions.
From blog.csdn.net
Spark 2:Spark Core RDD算子_spark2CSDN博客 Df Rdd Numpartitions In the case of scala,. Represents an immutable, partitioned collection of elements that can be. In this method, we are going to find the number of partitions in a data frame using. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. Pyspark.sql.dataframe.repartition () method is used. Df Rdd Numpartitions.
From zhuanlan.zhihu.com
图解 Spark 21 个算子(建议收藏) 知乎 Df Rdd Numpartitions In the case of scala,. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). A resilient distributed dataset (rdd), the basic abstraction in spark. Represents an immutable, partitioned collection of elements that can be.. Df Rdd Numpartitions.
From blog.csdn.net
PySpark数据分析基础核心数据集RDD常用函数操作一文详解(三)_pyspark numpartitionCSDN博客 Df Rdd Numpartitions Represents an immutable, partitioned collection of elements that can be. A resilient distributed dataset (rdd), the basic abstraction in spark. Pyspark.sql.dataframe.repartition () method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or multiple column names. Returns the number of partitions in rdd. In the case of scala,. In summary, you. Df Rdd Numpartitions.
From blog.csdn.net
11pyspark的RDD的变换与动作算子总结_rdd转述和rdd动作的关系CSDN博客 Df Rdd Numpartitions In this method, we are going to find the number of partitions in a data frame using. Represents an immutable, partitioned collection of elements that can be. You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and. Df Rdd Numpartitions.
From blog.csdn.net
大数据:RDD算子,filter,distinct,union,join,intersection,glom,groupByKey Df Rdd Numpartitions Represents an immutable, partitioned collection of elements that can be. In the case of scala,. A resilient distributed dataset (rdd), the basic abstraction in spark. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. In this method, we are going to find the number of partitions. Df Rdd Numpartitions.
From zhuanlan.zhihu.com
RDD,DataFrames和Datasets的区别 知乎 Df Rdd Numpartitions You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). In this method, we are going to find the number of partitions in a data frame using. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. Represents an immutable, partitioned collection of elements that. Df Rdd Numpartitions.
From zhuanlan.zhihu.com
Spark Shuffle过程详解 知乎 Df Rdd Numpartitions You need to call getnumpartitions() on the dataframe's underlying rdd, e.g., df.rdd.getnumpartitions(). A resilient distributed dataset (rdd), the basic abstraction in spark. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. Represents an immutable, partitioned collection of elements that can be. Returns the number of partitions. Df Rdd Numpartitions.
From blog.csdn.net
【回顾】RDD的转换算子 Transform_reducebykey属于rdd的转换算子吗CSDN博客 Df Rdd Numpartitions Returns the number of partitions in rdd. In this method, we are going to find the number of partitions in a data frame using. In summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd and calling the. In the case of scala,. Represents an immutable, partitioned collection of elements that. Df Rdd Numpartitions.