Rmsprop Vs Adam Which Is Better . In this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will. Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the majority of situations. Rmsprop with momentum generates its parameter updates using momentum on the. It is very similar to adadelta. Rmsprop, which stands for root mean square propagation, is an adaptive learning rate optimization algorithm designed specifically for training neural networks. Optimization algorithms are very important while training any deep learning models by adjusting the model’s parameters to. The only difference is in the way they manage the past gradients. Considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. I've learned from dl classes that adam should be the default choice for neural network training. There are a few important differences between rmsprop with momentum and adam: Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. It adds to the advantages of adadelta and rmsprop, the.
from zhuanlan.zhihu.com
Rmsprop with momentum generates its parameter updates using momentum on the. Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. I've learned from dl classes that adam should be the default choice for neural network training. There are a few important differences between rmsprop with momentum and adam: Rmsprop, which stands for root mean square propagation, is an adaptive learning rate optimization algorithm designed specifically for training neural networks. In this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will. Considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. It is very similar to adadelta. Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the majority of situations. Optimization algorithms are very important while training any deep learning models by adjusting the model’s parameters to.
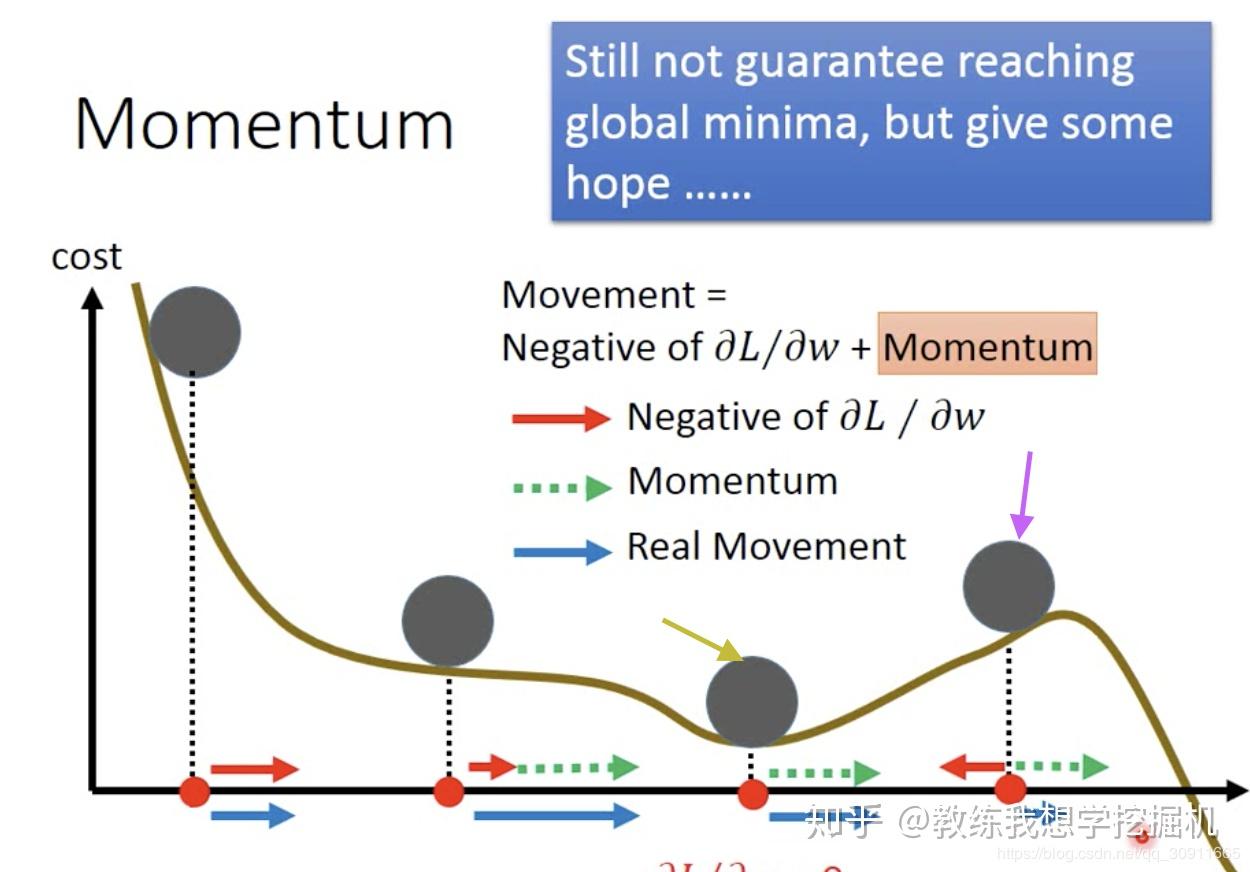
梯度下降的各种变形momentum,adagrad,rmsprop,adam分别解决了什么问题 知乎
Rmsprop Vs Adam Which Is Better The only difference is in the way they manage the past gradients. Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. It adds to the advantages of adadelta and rmsprop, the. Optimization algorithms are very important while training any deep learning models by adjusting the model’s parameters to. In this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will. Rmsprop with momentum generates its parameter updates using momentum on the. I've learned from dl classes that adam should be the default choice for neural network training. Rmsprop, which stands for root mean square propagation, is an adaptive learning rate optimization algorithm designed specifically for training neural networks. Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the majority of situations. There are a few important differences between rmsprop with momentum and adam: The only difference is in the way they manage the past gradients. Considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. It is very similar to adadelta.
From www.ngui.cc
RMSProp/Momentum/Adam/AdamW,多种优化器详解及伪代码实现 Rmsprop Vs Adam Which Is Better Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. It adds to the advantages of adadelta and rmsprop, the. Considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. I've learned from dl classes that. Rmsprop Vs Adam Which Is Better.
From blog.paperspace.com
Intro to optimization in deep learning Momentum, RMSProp and Adam Rmsprop Vs Adam Which Is Better There are a few important differences between rmsprop with momentum and adam: It adds to the advantages of adadelta and rmsprop, the. Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the majority of situations. It is very similar to adadelta. I've learned from dl classes that adam should be the default choice. Rmsprop Vs Adam Which Is Better.
From www.researchgate.net
Comparison of PAL against SLS, SGD, ADAM, RMSProp, ALIG, SGDHD and Rmsprop Vs Adam Which Is Better In this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will. Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. Rmsprop with momentum generates its parameter updates using momentum on the. Rmsprop, which stands for root. Rmsprop Vs Adam Which Is Better.
From blog.csdn.net
随机优化算法Adam RMSProp + MomentumCSDN博客 Rmsprop Vs Adam Which Is Better It adds to the advantages of adadelta and rmsprop, the. Considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. Rmsprop with momentum generates its parameter updates using momentum on the. Optimization algorithms are very important while training any deep learning models by adjusting the model’s. Rmsprop Vs Adam Which Is Better.
From www.youtube.com
[인공지능 30강] 옵티마이저 (최적화기법, RMSprop, Adam) YouTube Rmsprop Vs Adam Which Is Better Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the majority of situations. Rmsprop, which stands for root mean square propagation, is an adaptive learning rate optimization algorithm designed specifically for training neural networks. There are a few important differences between rmsprop with momentum and adam: Last but not least, adam (short for. Rmsprop Vs Adam Which Is Better.
From www.researchgate.net
Illustrate the train loss comparison of (a) SGD vs Adam, (b) Adagard vs Rmsprop Vs Adam Which Is Better I've learned from dl classes that adam should be the default choice for neural network training. The only difference is in the way they manage the past gradients. There are a few important differences between rmsprop with momentum and adam: Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the majority of situations.. Rmsprop Vs Adam Which Is Better.
From www.researchgate.net
Comparison of PAL to SGD, SLS, ADAM, RMSProp on training loss Rmsprop Vs Adam Which Is Better In this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will. Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the majority of situations. There are a few important differences between rmsprop with momentum and adam: Last but not least,. Rmsprop Vs Adam Which Is Better.
From quizgecko.com
5. Issues and Techniques in Deep Learning 2 28012024 RMSProp vs Rmsprop Vs Adam Which Is Better Optimization algorithms are very important while training any deep learning models by adjusting the model’s parameters to. There are a few important differences between rmsprop with momentum and adam: Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. Considered as a combination of momentum and rmsprop, adam is the. Rmsprop Vs Adam Which Is Better.
From bhuvanakundumani.hashnode.dev
Optimizers RMSprop and Adam algorithms (Part 3) Rmsprop Vs Adam Which Is Better It is very similar to adadelta. Rmsprop with momentum generates its parameter updates using momentum on the. There are a few important differences between rmsprop with momentum and adam: Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the majority of situations. Rmsprop, which stands for root mean square propagation, is an adaptive. Rmsprop Vs Adam Which Is Better.
From www.youtube.com
Deep Learning gradient descent optimization RMSprop and Adam Rmsprop Vs Adam Which Is Better The only difference is in the way they manage the past gradients. Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the majority of situations. I've learned from dl classes that adam should be the default choice for neural network training. There are a few important differences between rmsprop with momentum and adam:. Rmsprop Vs Adam Which Is Better.
From www.reddit.com
Visualized optimizers RMSProp vs Gradient Descent vs ADAM vs FTRL Rmsprop Vs Adam Which Is Better It adds to the advantages of adadelta and rmsprop, the. Rmsprop, which stands for root mean square propagation, is an adaptive learning rate optimization algorithm designed specifically for training neural networks. Rmsprop with momentum generates its parameter updates using momentum on the. Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum. Rmsprop Vs Adam Which Is Better.
From www.youtube.com
Momentum vs RMSprop vs ADAM ¿Cuál es mejor? YouTube Rmsprop Vs Adam Which Is Better Rmsprop, which stands for root mean square propagation, is an adaptive learning rate optimization algorithm designed specifically for training neural networks. The only difference is in the way they manage the past gradients. I've learned from dl classes that adam should be the default choice for neural network training. In this article, we will go through the adam and rmsprop. Rmsprop Vs Adam Which Is Better.
From velog.io
[DL] 최적화 알고리즘 RMSProp, Adam Rmsprop Vs Adam Which Is Better It is very similar to adadelta. Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. Optimization algorithms are very important while training any deep learning models by adjusting the model’s parameters to. Considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly. Rmsprop Vs Adam Which Is Better.
From www.scribd.com
8 Adagrad, RMSprop, Adam 04 Sep 2020material I 04 Sep 2020 Module4 Rmsprop Vs Adam Which Is Better Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the majority of situations. The only difference is in the way they manage the past gradients. I've learned from dl classes that adam should. Rmsprop Vs Adam Which Is Better.
From zhuanlan.zhihu.com
深度学习随笔——优化算法( SGD、BGD、MBGD、Momentum、NAG、Adagrad、RMSProp、AdaDelta、Adam Rmsprop Vs Adam Which Is Better I've learned from dl classes that adam should be the default choice for neural network training. Optimization algorithms are very important while training any deep learning models by adjusting the model’s parameters to. Considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. The only difference. Rmsprop Vs Adam Which Is Better.
From www.researchgate.net
Performance of different solvers in TensorFlow (a)Adam, (b) RMSprop Rmsprop Vs Adam Which Is Better Rmsprop with momentum generates its parameter updates using momentum on the. Rmsprop, which stands for root mean square propagation, is an adaptive learning rate optimization algorithm designed specifically for training neural networks. Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. In this article, we will go through the. Rmsprop Vs Adam Which Is Better.
From www.youtube.com
TIPS & TRICKS Deep Learning How to choose the best optimizer? Adam Rmsprop Vs Adam Which Is Better It is very similar to adadelta. Rmsprop with momentum generates its parameter updates using momentum on the. Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. The only difference is in the way they manage the past gradients. Optimization algorithms are very important while training any deep learning models. Rmsprop Vs Adam Which Is Better.
From www.researchgate.net
Different optimizers of our proposed algorithm (RMSprop, Adam and SGD Rmsprop Vs Adam Which Is Better Rmsprop with momentum generates its parameter updates using momentum on the. Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. There are a few important differences between rmsprop with momentum and adam: Optimization algorithms are very important while training any deep learning models by adjusting the model’s parameters to.. Rmsprop Vs Adam Which Is Better.
From www.youtube.com
Optimization for Deep Learning (Momentum, RMSprop, AdaGrad, Adam) YouTube Rmsprop Vs Adam Which Is Better The only difference is in the way they manage the past gradients. Rmsprop with momentum generates its parameter updates using momentum on the. I've learned from dl classes that adam should be the default choice for neural network training. Rmsprop, which stands for root mean square propagation, is an adaptive learning rate optimization algorithm designed specifically for training neural networks.. Rmsprop Vs Adam Which Is Better.
From www.researchgate.net
Comparison of Adam and RMSProp optimizers for the DQN and A2C networks Rmsprop Vs Adam Which Is Better I've learned from dl classes that adam should be the default choice for neural network training. Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. It adds to the advantages of adadelta and rmsprop, the. There are a few important differences between rmsprop with momentum and adam: Moreover, it. Rmsprop Vs Adam Which Is Better.
From www.researchgate.net
Accuracy, loss and the execution time for SGD, Adam and RMSprop Rmsprop Vs Adam Which Is Better Rmsprop with momentum generates its parameter updates using momentum on the. Rmsprop, which stands for root mean square propagation, is an adaptive learning rate optimization algorithm designed specifically for training neural networks. There are a few important differences between rmsprop with momentum and adam: In this article, we will go through the adam and rmsprop starting from its algorithm to. Rmsprop Vs Adam Which Is Better.
From zhuanlan.zhihu.com
梯度下降的各种变形momentum,adagrad,rmsprop,adam分别解决了什么问题 知乎 Rmsprop Vs Adam Which Is Better I've learned from dl classes that adam should be the default choice for neural network training. Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. There are a few important differences between rmsprop with momentum and adam: It adds to the advantages of adadelta and rmsprop, the. It is. Rmsprop Vs Adam Which Is Better.
From www.researchgate.net
Comparison plot of SGDM, RMSProp, and Adam. Download Scientific Diagram Rmsprop Vs Adam Which Is Better Considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. In this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will. It is very similar to adadelta. Last but not least, adam (short. Rmsprop Vs Adam Which Is Better.
From medium.com
A Complete Guide to Adam and RMSprop Optimizer by Sanghvirajit Rmsprop Vs Adam Which Is Better Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the majority of situations. It is very similar to adadelta. Rmsprop, which stands for root mean square propagation, is an adaptive learning rate optimization algorithm designed specifically for training neural networks. The only difference is in the way they manage the past gradients. Considered. Rmsprop Vs Adam Which Is Better.
From www.youtube.com
Advanced Gradient Descent Variations SGD, Adam, RMSprop, and Adagrad Rmsprop Vs Adam Which Is Better It adds to the advantages of adadelta and rmsprop, the. It is very similar to adadelta. I've learned from dl classes that adam should be the default choice for neural network training. Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. Rmsprop, which stands for root mean square propagation,. Rmsprop Vs Adam Which Is Better.
From blog.csdn.net
sgdm是什么CSDN博客 Rmsprop Vs Adam Which Is Better The only difference is in the way they manage the past gradients. Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the majority of situations. Optimization algorithms are very important while training any deep learning models by adjusting the model’s parameters to. It adds to the advantages of adadelta and rmsprop, the. In. Rmsprop Vs Adam Which Is Better.
From morioh.com
Adam. Rmsprop. Momentum. Optimization Algorithm. Principles in Deep Rmsprop Vs Adam Which Is Better In this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will. I've learned from dl classes that adam should be the default choice for neural network training. It is very similar to adadelta. Rmsprop, which stands for root mean square propagation, is an adaptive learning rate optimization. Rmsprop Vs Adam Which Is Better.
From technology.gov.capital
When should one use a different learning rate schedule with Adam or Rmsprop Vs Adam Which Is Better Optimization algorithms are very important while training any deep learning models by adjusting the model’s parameters to. Rmsprop, which stands for root mean square propagation, is an adaptive learning rate optimization algorithm designed specifically for training neural networks. Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the majority of situations. There are. Rmsprop Vs Adam Which Is Better.
From meme2515.github.io
수학적으로 이해하는 최적화 기법 모멘텀, RMSProp, ADAM Rmsprop Vs Adam Which Is Better In this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will. There are a few important differences between rmsprop with momentum and adam: Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the majority of situations. Optimization algorithms are very. Rmsprop Vs Adam Which Is Better.
From www.youtube.com
Understanding RMSProp Optimization Algorithm Visually YouTube Rmsprop Vs Adam Which Is Better In this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will. Considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. It is very similar to adadelta. Rmsprop with momentum generates its parameter. Rmsprop Vs Adam Which Is Better.
From zhuanlan.zhihu.com
机器学习2 优化器(SGD、SGDM、Adagrad、RMSProp、Adam) 知乎 Rmsprop Vs Adam Which Is Better Rmsprop, which stands for root mean square propagation, is an adaptive learning rate optimization algorithm designed specifically for training neural networks. The only difference is in the way they manage the past gradients. Optimization algorithms are very important while training any deep learning models by adjusting the model’s parameters to. I've learned from dl classes that adam should be the. Rmsprop Vs Adam Which Is Better.
From bhuvanakundumani.hashnode.dev
Optimizers RMSprop and Adam algorithms (Part 3) Rmsprop Vs Adam Which Is Better Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. Rmsprop with momentum generates its parameter updates using momentum on the. The only difference is in the way they manage the past gradients. Moreover, it has a straightforward implementation and little memory requirements making it a preferable choice in the. Rmsprop Vs Adam Which Is Better.
From github.com
GitHub EliaFantini/RMSPropandAMSGradforMNISTimageclassification Rmsprop Vs Adam Which Is Better The only difference is in the way they manage the past gradients. It is very similar to adadelta. It adds to the advantages of adadelta and rmsprop, the. Considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. Optimization algorithms are very important while training any. Rmsprop Vs Adam Which Is Better.
From towardsdatascience.com
A Visual Explanation of Gradient Descent Methods (Momentum, AdaGrad Rmsprop Vs Adam Which Is Better It is very similar to adadelta. Rmsprop, which stands for root mean square propagation, is an adaptive learning rate optimization algorithm designed specifically for training neural networks. There are a few important differences between rmsprop with momentum and adam: Optimization algorithms are very important while training any deep learning models by adjusting the model’s parameters to. Moreover, it has a. Rmsprop Vs Adam Which Is Better.
From zhuanlan.zhihu.com
Adagrad、RMSprop、Momentum、Adam 知乎 Rmsprop Vs Adam Which Is Better The only difference is in the way they manage the past gradients. Last but not least, adam (short for adaptive moment estimation) takes the best of both worlds of momentum and rmsprop. In this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will. Considered as a combination. Rmsprop Vs Adam Which Is Better.