Torch.quantization.quantstub . Implement quantization manually in pytorch. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. understand pytorch’s quantization api. Can i force torch.quantization.quantstub() to. now i want to convert it using the static quantization pytorch package. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. A common workaround is to use. dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the.
from discuss.pytorch.org
to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. Implement quantization manually in pytorch. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. A common workaround is to use. Can i force torch.quantization.quantstub() to. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. understand pytorch’s quantization api. now i want to convert it using the static quantization pytorch package.
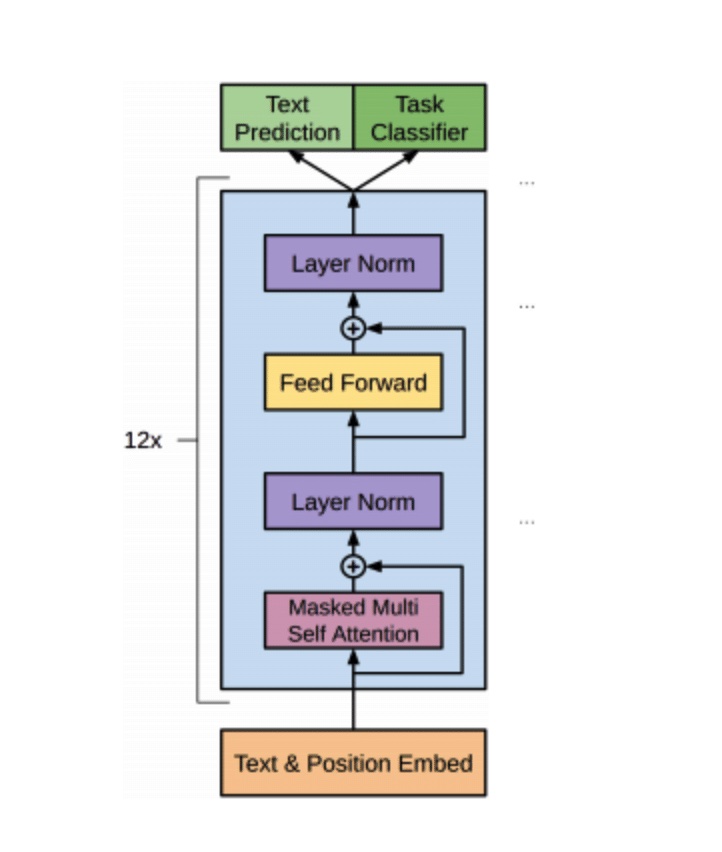
Quantizationaware training for GPT2 quantization PyTorch Forums
Torch.quantization.quantstub class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. Implement quantization manually in pytorch. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. Can i force torch.quantization.quantstub() to. now i want to convert it using the static quantization pytorch package. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. understand pytorch’s quantization api. A common workaround is to use.
From github.com
torch.quantization.quantize_dynamic document refers `module` as a parameter · Issue 43503 Torch.quantization.quantstub Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. A common workaround is to use. now i want to convert it using the static quantization pytorch package. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. Can. Torch.quantization.quantstub.
From github.com
GitHub rluthfan/pytorchquantization Final Project of COMS 6998 Practical Deep Learning Torch.quantization.quantstub understand pytorch’s quantization api. A common workaround is to use. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. Implement quantization manually in pytorch. dequantstub is a place holder for dequantize op, but it. Torch.quantization.quantstub.
From blog.csdn.net
小白学Pytorch系列Torch.nn API Quantized Functions(19)_torch parametrizationsCSDN博客 Torch.quantization.quantstub A common workaround is to use. dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. understand pytorch’s quantization api. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a.. Torch.quantization.quantstub.
From github.com
[Quantization] Quantized Torchscript justintime compilation is taking 60,000ms every time for Torch.quantization.quantstub now i want to convert it using the static quantization pytorch package. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. Can i force torch.quantization.quantstub() to. Implement quantization manually in pytorch. dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. apply torch.quantization.quantstub() and torch.quantization.quantstub() to. Torch.quantization.quantstub.
From huggingface.co
SivaResearch/SivaResearchDeepfake_torch_quantized at main Torch.quantization.quantstub dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. Implement quantization manually in pytorch. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. now i want to convert it using the static quantization pytorch package. Can i force torch.quantization.quantstub() to. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. understand. Torch.quantization.quantstub.
From blog.csdn.net
pytorch每日一学24(torch.quantize_per_tensor()、torch.quantize_per_channel())使用映射过程将tensor进行量化_torch Torch.quantization.quantstub apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. now i want to convert it using the static quantization pytorch package. Implement quantization manually in pytorch. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. understand. Torch.quantization.quantstub.
From github.com
`split()` method with `torch.ao.quantization.prepare()` or `torch.ao.quantization.prepare_qat Torch.quantization.quantstub class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. A common workaround is to use. now i want to convert it using the static quantization pytorch package. Implement quantization manually in pytorch. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. Quantstub (qconfig = none) [source] ¶. Torch.quantization.quantstub.
From www.educba.com
PyTorch Quantization What is PyTorch Quantization? How to works? Torch.quantization.quantstub apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. understand pytorch’s quantization api. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. dequantstub is a place holder for dequantize op, but it does not need to be unique since. Torch.quantization.quantstub.
From blog.csdn.net
PyTorch模型量化工具学习_quantization.observer.histogramobserverCSDN博客 Torch.quantization.quantstub A common workaround is to use. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. Can i force torch.quantization.quantstub() to. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. now i want to convert it using. Torch.quantization.quantstub.
From blog.csdn.net
pytorchquantization vs torch.ao.quantization vs torch.quantization区别_torch.quantization和torch Torch.quantization.quantstub dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. A common workaround is to use. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. . Torch.quantization.quantstub.
From github.com
How to apply torch.quantization.quantize_dynamic for conv2d layer? · Issue 899 · pytorch Torch.quantization.quantstub Implement quantization manually in pytorch. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. A common workaround is to use.. Torch.quantization.quantstub.
From github.com
[question] Difference of pytorch_quantization modules and torch.ao.quantization · Issue 3095 Torch.quantization.quantstub Can i force torch.quantization.quantstub() to. Implement quantization manually in pytorch. now i want to convert it using the static quantization pytorch package. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. Quantstub (qconfig = none) [source] ¶ quantize stub. Torch.quantization.quantstub.
From www.vedereai.com
Practical Quantization in PyTorch Vedere AI Torch.quantization.quantstub A common workaround is to use. understand pytorch’s quantization api. Can i force torch.quantization.quantstub() to. Implement quantization manually in pytorch. dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. to enable a model for quantization aware traing, define in the __init__ method of the model definition a. Torch.quantization.quantstub.
From www.mdpi.com
Sensors Free FullText Quantization and Deployment of Deep Neural Networks on Microcontrollers Torch.quantization.quantstub now i want to convert it using the static quantization pytorch package. A common workaround is to use. dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and. Torch.quantization.quantstub.
From github.com
GitHub clarencechen/torchquantization Torch.quantization.quantstub dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. A common workaround is to use. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. now i want to convert it using the static quantization pytorch package. Implement quantization manually in pytorch. Can i force torch.quantization.quantstub() to. understand pytorch’s. Torch.quantization.quantstub.
From discuss.pytorch.org
RuntimeError Could not run 'atenempty.memory_format' with arguments from the 'QuantizedCPU Torch.quantization.quantstub dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. now i want to convert it. Torch.quantization.quantstub.
From github.com
torch.quantization.fuse_modules is not backward compatible in PyTorch 1.11 · Issue 74028 Torch.quantization.quantstub Implement quantization manually in pytorch. dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. A common workaround is to use. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. now i want to convert it. Torch.quantization.quantstub.
From buxianchen.github.io
(P0) Pytorch Quantization Humanpia Torch.quantization.quantstub Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. understand pytorch’s quantization api. now i want to convert it using the static quantization pytorch package. Can i force torch.quantization.quantstub(). Torch.quantization.quantstub.
From raki-1203.github.io
Day_82 02. 찢은 모델 꾸겨 넣기 Quantization 실습(with torch, tensorrt) 딥린이의 작업노트 Torch.quantization.quantstub class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. Implement quantization manually in pytorch. now i want to convert it using the static quantization pytorch package. A common workaround is to use. Quantstub (qconfig = none) [source] ¶. Torch.quantization.quantstub.
From github.com
Some of the problems with torch.quantization.quantize_dynamic( ) · Issue 90986 · pytorch Torch.quantization.quantstub A common workaround is to use. dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. Can i force torch.quantization.quantstub() to. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. now i want to convert it using the static quantization pytorch package. understand pytorch’s quantization api. Quantstub (qconfig =. Torch.quantization.quantstub.
From github.com
Fully quantized model (`torch.quantization.convert`) produces incorrect output compared to Torch.quantization.quantstub dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. Implement quantization manually in pytorch. now i want to convert it using the static quantization pytorch package. understand pytorch’s quantization api. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. apply torch.quantization.quantstub() and torch.quantization.quantstub() to. Torch.quantization.quantstub.
From blog.csdn.net
【量化】PostTraining Quantization for Vision TransformerCSDN博客 Torch.quantization.quantstub dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. Implement quantization manually in pytorch. to enable a model for quantization aware traing,. Torch.quantization.quantstub.
From buxianchen.github.io
(P0) Pytorch Quantization Humanpia Torch.quantization.quantstub apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. Can i force torch.quantization.quantstub() to. A common workaround is to use. understand pytorch’s quantization api. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. Implement quantization manually in. Torch.quantization.quantstub.
From blog.csdn.net
pytorchquantization vs torch.ao.quantization vs torch.quantization区别_torch.quantization和torch Torch.quantization.quantstub Implement quantization manually in pytorch. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. Can i force torch.quantization.quantstub() to. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. dequantstub. Torch.quantization.quantstub.
From pytorch.org
Practical Quantization in PyTorch PyTorch Torch.quantization.quantstub now i want to convert it using the static quantization pytorch package. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. A common workaround is to use. Can i force torch.quantization.quantstub(). Torch.quantization.quantstub.
From pytorch.org
Practical Quantization in PyTorch PyTorch Torch.quantization.quantstub to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. understand pytorch’s quantization api. Implement quantization manually in pytorch. now i want to convert it using the static quantization pytorch package. A common workaround is to use. dequantstub is a place holder for dequantize op,. Torch.quantization.quantstub.
From blog.csdn.net
pytorch动态量化函数torch.quantization.quantize_dynamic详解CSDN博客 Torch.quantization.quantstub Implement quantization manually in pytorch. now i want to convert it using the static quantization pytorch package. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. A common workaround is to use. dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. understand pytorch’s quantization api.. Torch.quantization.quantstub.
From blog.csdn.net
PyTorch QAT(量化感知训练)实践——基础篇CSDN博客 Torch.quantization.quantstub now i want to convert it using the static quantization pytorch package. Can i force torch.quantization.quantstub() to. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. dequantstub is a place holder for dequantize op,. Torch.quantization.quantstub.
From github.com
GitHub bwosh/torchquantization This repository shows how to use quantization in PyTorch 1.3+ Torch.quantization.quantstub understand pytorch’s quantization api. A common workaround is to use. Can i force torch.quantization.quantstub() to. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. Implement quantization manually in pytorch. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. now i want to convert. Torch.quantization.quantstub.
From www.maxssl.com
torch与torchvision版本对应关系 & ImportError cannot import name ‘QuantStub‘ from ‘torch.ao Torch.quantization.quantstub Implement quantization manually in pytorch. Can i force torch.quantization.quantstub() to. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. A common workaround is to use. dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. understand pytorch’s quantization api. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. to enable a. Torch.quantization.quantstub.
From github.com
torch_quantization_design_proposal · pytorch/pytorch Wiki · GitHub Torch.quantization.quantstub understand pytorch’s quantization api. Can i force torch.quantization.quantstub() to. dequantstub is a place holder for dequantize op, but it does not need to be unique since it’s stateless. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. Implement quantization manually in pytorch. A common workaround. Torch.quantization.quantstub.
From blog.csdn.net
pytorch的量化Quantization_pytorchquantizationCSDN博客 Torch.quantization.quantstub to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. Implement quantization manually in pytorch. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. A common workaround is to use. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. Can. Torch.quantization.quantstub.
From www.ccoderun.ca
TensorRT pytorch_quantization.nn.modules.quant_pooling.QuantMaxPool1d Class Reference Torch.quantization.quantstub Can i force torch.quantization.quantstub() to. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. A common workaround is to use. to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. now i want to convert it using the static quantization pytorch package. Implement quantization manually in pytorch. . Torch.quantization.quantstub.
From blog.csdn.net
pytorch每日一学24(torch.quantize_per_tensor()、torch.quantize_per_channel())使用映射过程将tensor进行量化_torch Torch.quantization.quantstub apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. A common workaround is to use. class torch.ao.quantization.quantstub(qconfig=none) [source] quantize stub module, before. understand pytorch’s quantization api. Quantstub (qconfig = none) [source] ¶ quantize stub module, before calibration,. Can i force torch.quantization.quantstub() to. dequantstub is a place holder for dequantize op, but it does not need to be unique since. Torch.quantization.quantstub.
From discuss.pytorch.org
Quantizationaware training for GPT2 quantization PyTorch Forums Torch.quantization.quantstub to enable a model for quantization aware traing, define in the __init__ method of the model definition a quantstub and a. apply torch.quantization.quantstub() and torch.quantization.quantstub() to the. now i want to convert it using the static quantization pytorch package. A common workaround is to use. understand pytorch’s quantization api. Can i force torch.quantization.quantstub() to. Quantstub (qconfig. Torch.quantization.quantstub.