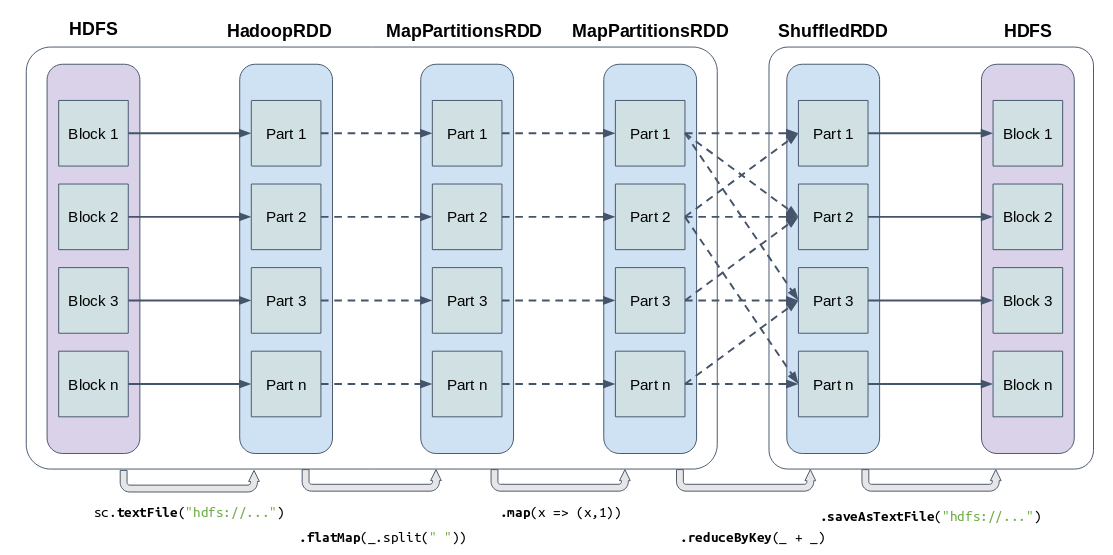
Get Partitions In Spark . Data partitioning is critical to data processing performance especially for large volume of data processing in spark. In this article, we are going to learn how to get the current number of partitions of a data frame using pyspark in python. Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. There are three main types of spark partitioning: Based on hashpartitioner spark will decide how many number of partitions to distribute. When you create a dataframe, the data. Here’s how you can get the current number of partitions of a dataframe in spark using different languages: Each type offers unique benefits and considerations for data. In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). Hash partitioning, range partitioning, and round robin partitioning.
from www.xpand-it.com
Each type offers unique benefits and considerations for data. Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. In this article, we are going to learn how to get the current number of partitions of a data frame using pyspark in python. Hash partitioning, range partitioning, and round robin partitioning. When you create a dataframe, the data. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Here’s how you can get the current number of partitions of a dataframe in spark using different languages: There are three main types of spark partitioning: In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). Based on hashpartitioner spark will decide how many number of partitions to distribute.
meetupsparkmappartitions Xpand IT
Get Partitions In Spark Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). Based on hashpartitioner spark will decide how many number of partitions to distribute. There are three main types of spark partitioning: Hash partitioning, range partitioning, and round robin partitioning. When you create a dataframe, the data. Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. In this article, we are going to learn how to get the current number of partitions of a data frame using pyspark in python. Each type offers unique benefits and considerations for data. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Here’s how you can get the current number of partitions of a dataframe in spark using different languages:
From www.xpand-it.com
meetupsparkmappartitions Xpand IT Get Partitions In Spark Data partitioning is critical to data processing performance especially for large volume of data processing in spark. In this article, we are going to learn how to get the current number of partitions of a data frame using pyspark in python. Hash partitioning, range partitioning, and round robin partitioning. Each type offers unique benefits and considerations for data. Repartition (). Get Partitions In Spark.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Get Partitions In Spark When you create a dataframe, the data. Based on hashpartitioner spark will decide how many number of partitions to distribute. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Hash partitioning, range partitioning, and round robin partitioning. Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease. Get Partitions In Spark.
From exokeufcv.blob.core.windows.net
Max Number Of Partitions In Spark at Manda Salazar blog Get Partitions In Spark Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. Each type offers unique benefits and considerations for data. There are three main types of spark partitioning: When you create a dataframe, the data. In this article, we are going to learn how to get the current number. Get Partitions In Spark.
From stackoverflow.com
google cloud platform How to overwrite specific partitions in spark Get Partitions In Spark Based on hashpartitioner spark will decide how many number of partitions to distribute. When you create a dataframe, the data. Here’s how you can get the current number of partitions of a dataframe in spark using different languages: Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe.. Get Partitions In Spark.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient Get Partitions In Spark In this article, we are going to learn how to get the current number of partitions of a data frame using pyspark in python. Here’s how you can get the current number of partitions of a dataframe in spark using different languages: Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of. Get Partitions In Spark.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Get Partitions In Spark Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Each type offers unique benefits and considerations for data. When you create a dataframe, the data. In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). Here’s how you can get the. Get Partitions In Spark.
From medium.com
Managing Spark Partitions. How data is partitioned and when do you Get Partitions In Spark Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Based on hashpartitioner spark will decide how many number of partitions to distribute. Hash partitioning, range partitioning, and round robin partitioning. Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe.. Get Partitions In Spark.
From www.youtube.com
Why should we partition the data in spark? YouTube Get Partitions In Spark Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. There are three main types of spark partitioning: In apache spark, you can use the rdd.getnumpartitions() method to get the number. Get Partitions In Spark.
From spaziocodice.com
Spark SQL Partitions and Sizes SpazioCodice Get Partitions In Spark There are three main types of spark partitioning: Hash partitioning, range partitioning, and round robin partitioning. Each type offers unique benefits and considerations for data. Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. In this article, we are going to learn how to get the current. Get Partitions In Spark.
From data-flair.training
Spark InMemory Computing A Beginners Guide DataFlair Get Partitions In Spark Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. Based on hashpartitioner spark will decide how many number of partitions to distribute. In this article, we are going to learn how to get the current number of partitions of a data frame using pyspark in python. When. Get Partitions In Spark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Get Partitions In Spark Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. In this article, we are going to learn how to get the current number of partitions of a data frame using pyspark in python. When you create a dataframe, the data. Data partitioning is critical to data processing. Get Partitions In Spark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Get Partitions In Spark There are three main types of spark partitioning: Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. Each type offers unique benefits and considerations for data. Hash partitioning, range partitioning, and round robin partitioning. In this article, we are going to learn how to get the current. Get Partitions In Spark.
From www.ishandeshpande.com
Understanding Partitions in Apache Spark Get Partitions In Spark There are three main types of spark partitioning: Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Hash partitioning, range partitioning, and round robin partitioning. In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). Based on hashpartitioner spark will decide. Get Partitions In Spark.
From itnext.io
Apache Spark Internals Tips and Optimizations by Javier Ramos ITNEXT Get Partitions In Spark Hash partitioning, range partitioning, and round robin partitioning. In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). Based on hashpartitioner spark will decide how many number of partitions to distribute. Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of. Get Partitions In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Get Partitions In Spark In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. Based on hashpartitioner spark will decide how many number of partitions to distribute. Hash partitioning, range partitioning,. Get Partitions In Spark.
From www.turing.com
Resilient Distribution Dataset Immutability in Apache Spark Get Partitions In Spark Here’s how you can get the current number of partitions of a dataframe in spark using different languages: Hash partitioning, range partitioning, and round robin partitioning. When you create a dataframe, the data. There are three main types of spark partitioning: Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions. Get Partitions In Spark.
From hxehbxgbm.blob.core.windows.net
What Is Partitions In Spark at Lawrence Flesher blog Get Partitions In Spark There are three main types of spark partitioning: In this article, we are going to learn how to get the current number of partitions of a data frame using pyspark in python. Each type offers unique benefits and considerations for data. Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions. Get Partitions In Spark.
From www.simplilearn.com
Spark Parallelize The Essential Element of Spark Get Partitions In Spark In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). In this article, we are going to learn how to get the current number of partitions of a data frame using pyspark in python. When you create a dataframe, the data. Based on hashpartitioner spark will decide how many. Get Partitions In Spark.
From stackoverflow.com
pyspark Why does Spark Query Plan shows more partitions whenever Get Partitions In Spark Based on hashpartitioner spark will decide how many number of partitions to distribute. Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Each type offers unique benefits and considerations for. Get Partitions In Spark.
From www.projectpro.io
How Data Partitioning in Spark helps achieve more parallelism? Get Partitions In Spark Here’s how you can get the current number of partitions of a dataframe in spark using different languages: Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. When you create a dataframe, the data. In this article, we are going to learn how to get the current. Get Partitions In Spark.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders Get Partitions In Spark In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). Here’s how you can get the current number of partitions of a dataframe in spark using different languages: There are three main types of spark partitioning: Data partitioning is critical to data processing performance especially for large volume of. Get Partitions In Spark.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Get Partitions In Spark Hash partitioning, range partitioning, and round robin partitioning. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. In apache spark, you can use the rdd.getnumpartitions() method to get the number. Get Partitions In Spark.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Get Partitions In Spark In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). Based on hashpartitioner spark will decide how many number of partitions to distribute. Each type offers unique benefits and considerations for data. In this article, we are going to learn how to get the current number of partitions of. Get Partitions In Spark.
From www.projectpro.io
DataFrames number of partitions in spark scala in Databricks Get Partitions In Spark Each type offers unique benefits and considerations for data. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. When you create a dataframe, the data. Based on hashpartitioner spark will decide how many number of partitions to distribute. Hash partitioning, range partitioning, and round robin partitioning. Repartition () is a method of. Get Partitions In Spark.
From dzone.com
Dynamic Partition Pruning in Spark 3.0 DZone Get Partitions In Spark In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). When you create a dataframe, the data. Each type offers unique benefits and considerations for data. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Repartition () is a method of. Get Partitions In Spark.
From exocpydfk.blob.core.windows.net
What Is Shuffle Partitions In Spark at Joe Warren blog Get Partitions In Spark Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). Here’s how you can get the current number of partitions of a dataframe in spark using different. Get Partitions In Spark.
From www.jowanza.com
Partitions in Apache Spark — Jowanza Joseph Get Partitions In Spark Hash partitioning, range partitioning, and round robin partitioning. Here’s how you can get the current number of partitions of a dataframe in spark using different languages: In this article, we are going to learn how to get the current number of partitions of a data frame using pyspark in python. When you create a dataframe, the data. There are three. Get Partitions In Spark.
From sparkbyexamples.com
Spark Get Current Number of Partitions of DataFrame Spark By {Examples} Get Partitions In Spark Each type offers unique benefits and considerations for data. Hash partitioning, range partitioning, and round robin partitioning. In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). Here’s how you can get the current number of partitions of a dataframe in spark using different languages: Data partitioning is critical. Get Partitions In Spark.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Get Partitions In Spark Here’s how you can get the current number of partitions of a dataframe in spark using different languages: In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). There are three main types of spark partitioning: Data partitioning is critical to data processing performance especially for large volume of. Get Partitions In Spark.
From garryshots.weebly.com
Install apache spark standalone garryshots Get Partitions In Spark In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). When you create a dataframe, the data. Hash partitioning, range partitioning, and round robin partitioning. Each type offers unique benefits and considerations for data. There are three main types of spark partitioning: Based on hashpartitioner spark will decide how. Get Partitions In Spark.
From toien.github.io
Spark 分区数量 Kwritin Get Partitions In Spark Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. Based on hashpartitioner spark will decide how many number of partitions to distribute. When you create a dataframe, the data. There. Get Partitions In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Get Partitions In Spark Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Each type offers unique benefits and considerations for data. Based on hashpartitioner spark will decide how many number of partitions to distribute. Here’s how you can get the current number of partitions of a dataframe in spark using different languages: When you create. Get Partitions In Spark.
From cloud-fundis.co.za
Dynamically Calculating Spark Partitions at Runtime Cloud Fundis Get Partitions In Spark Based on hashpartitioner spark will decide how many number of partitions to distribute. Here’s how you can get the current number of partitions of a dataframe in spark using different languages: Each type offers unique benefits and considerations for data. In this article, we are going to learn how to get the current number of partitions of a data frame. Get Partitions In Spark.
From thoughtfulworks.dev
Partitions and Bucketing in Spark thoughtful works Get Partitions In Spark In apache spark, you can use the rdd.getnumpartitions() method to get the number of partitions in an rdd (resilient distributed dataset). Each type offers unique benefits and considerations for data. Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. Here’s how you can get the current number. Get Partitions In Spark.
From www.mdpi.com
Applied Sciences Free FullText Comparative Analysis of SkewJoin Get Partitions In Spark There are three main types of spark partitioning: Repartition () is a method of pyspark.sql.dataframe class that is used to increase or decrease the number of partitions of the dataframe. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Hash partitioning, range partitioning, and round robin partitioning. Here’s how you can get. Get Partitions In Spark.