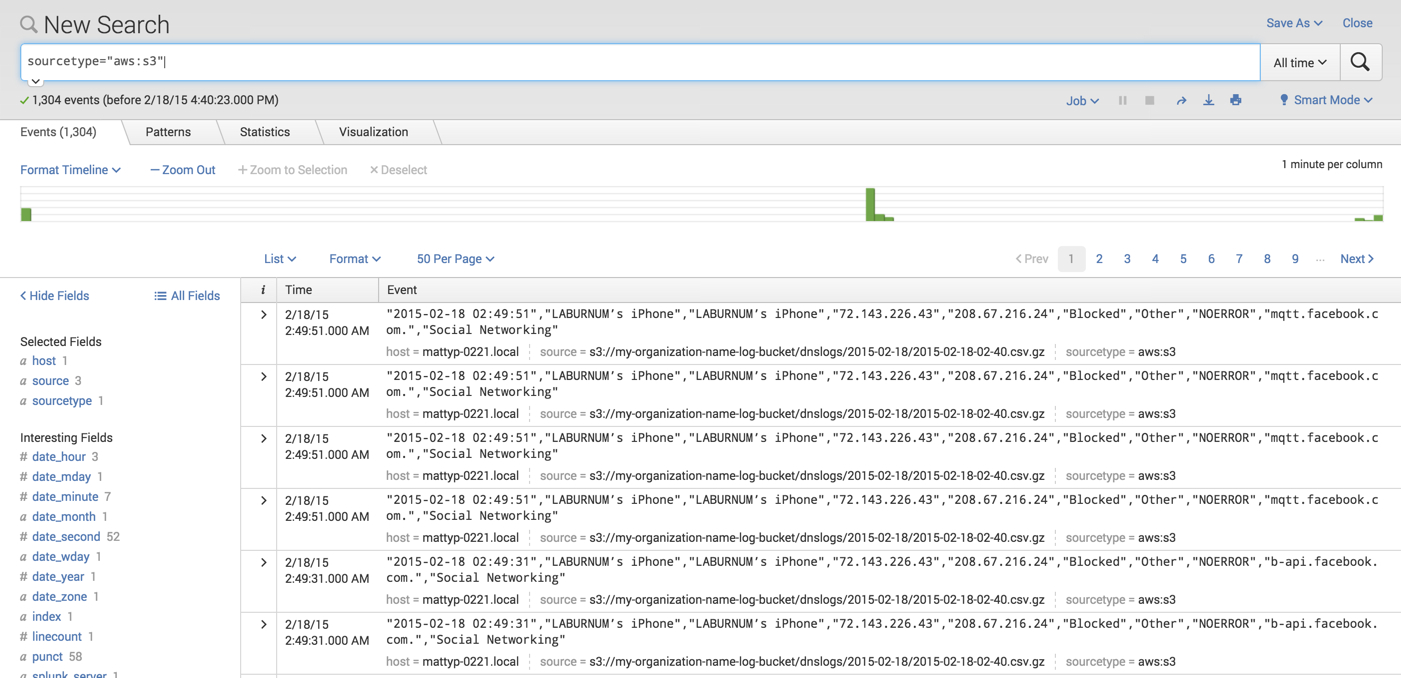
Splunk Bucket Id Conflict . Hi, this error message started popping up, on splunk cloud. To manually merge buckets from multiple legacy indexers onto one new indexer, i used these commands which work on rhel7/8: But i'm a bit confused by the line: So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally when splunkd adds. If the bucket id is same then it will create conflicts. If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and enable them. You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in. As you already know in splunk cloud you do not have access by ssh to the. I've been following this guide: The db file will be copied in the thawed bucket and then it will go in bin directory.
from support.umbrella.com
You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in. But i'm a bit confused by the line: To manually merge buckets from multiple legacy indexers onto one new indexer, i used these commands which work on rhel7/8: If the bucket id is same then it will create conflicts. As you already know in splunk cloud you do not have access by ssh to the. If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and enable them. I've been following this guide: The db file will be copied in the thawed bucket and then it will go in bin directory. So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally when splunkd adds. Hi, this error message started popping up, on splunk cloud.
Configuring Splunk with a Selfmanaged S3 Bucket Cisco Umbrella
Splunk Bucket Id Conflict If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and enable them. I've been following this guide: The db file will be copied in the thawed bucket and then it will go in bin directory. To manually merge buckets from multiple legacy indexers onto one new indexer, i used these commands which work on rhel7/8: So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally when splunkd adds. Hi, this error message started popping up, on splunk cloud. If the bucket id is same then it will create conflicts. You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in. If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and enable them. As you already know in splunk cloud you do not have access by ssh to the. But i'm a bit confused by the line:
From www.youtube.com
SIEM SPLUNK GuardDuty AWS GuardDuty Integration with Splunk via AWS Splunk Bucket Id Conflict The db file will be copied in the thawed bucket and then it will go in bin directory. To manually merge buckets from multiple legacy indexers onto one new indexer, i used these commands which work on rhel7/8: But i'm a bit confused by the line: So, the root cause of bucket id conflicts is that two buckets have the. Splunk Bucket Id Conflict.
From exojmkyuh.blob.core.windows.net
Splunk Bucket Encryption at Terry Leach blog Splunk Bucket Id Conflict Hi, this error message started popping up, on splunk cloud. So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally when splunkd adds. I've been following this guide: If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and. Splunk Bucket Id Conflict.
From velog.io
Splunk Bucket에 관하여 Splunk Bucket Id Conflict As you already know in splunk cloud you do not have access by ssh to the. Hi, this error message started popping up, on splunk cloud. If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and enable them. But i'm a bit confused by the line: So,. Splunk Bucket Id Conflict.
From community.splunk.com
What is Splunk buckets default retention period? Splunk Community Splunk Bucket Id Conflict As you already know in splunk cloud you do not have access by ssh to the. If the bucket id is same then it will create conflicts. So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally when splunkd adds. But i'm a bit confused by the line: I've been following. Splunk Bucket Id Conflict.
From community.splunk.com
Solved Diagrams of how indexing works in the Splunk platf... Splunk Splunk Bucket Id Conflict To manually merge buckets from multiple legacy indexers onto one new indexer, i used these commands which work on rhel7/8: But i'm a bit confused by the line: So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally when splunkd adds. If the internal indexes are fine and splunk starts (if. Splunk Bucket Id Conflict.
From subscription.packtpub.com
Splunk buckets Advanced Splunk Splunk Bucket Id Conflict I've been following this guide: But i'm a bit confused by the line: If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and enable them. You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in.. Splunk Bucket Id Conflict.
From exojmkyuh.blob.core.windows.net
Splunk Bucket Encryption at Terry Leach blog Splunk Bucket Id Conflict As you already know in splunk cloud you do not have access by ssh to the. You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in. I've been following this guide: If the bucket id is same then it will create conflicts. To manually merge buckets from multiple. Splunk Bucket Id Conflict.
From community.splunk.com
What is this splunk buckets error? Splunk Community Splunk Bucket Id Conflict As you already know in splunk cloud you do not have access by ssh to the. If the bucket id is same then it will create conflicts. To manually merge buckets from multiple legacy indexers onto one new indexer, i used these commands which work on rhel7/8: I've been following this guide: If the internal indexes are fine and splunk. Splunk Bucket Id Conflict.
From www.thomashenson.com
5 Types of Buckets in Splunk Thomas Henson Splunk Bucket Id Conflict To manually merge buckets from multiple legacy indexers onto one new indexer, i used these commands which work on rhel7/8: You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in. The db file will be copied in the thawed bucket and then it will go in bin directory.. Splunk Bucket Id Conflict.
From klarxuarr.blob.core.windows.net
Splunk Roll All Buckets at Linda Dicken blog Splunk Bucket Id Conflict Hi, this error message started popping up, on splunk cloud. As you already know in splunk cloud you do not have access by ssh to the. I've been following this guide: If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and enable them. The db file will. Splunk Bucket Id Conflict.
From community.splunk.com
What is Splunk buckets default retention period? Splunk Community Splunk Bucket Id Conflict As you already know in splunk cloud you do not have access by ssh to the. So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally when splunkd adds. But i'm a bit confused by the line: If the bucket id is same then it will create conflicts. Hi, this error. Splunk Bucket Id Conflict.
From hurricanelabs.com
Splunking Responsibly Part 2 How to Size Your Storage the Right Way Splunk Bucket Id Conflict The db file will be copied in the thawed bucket and then it will go in bin directory. As you already know in splunk cloud you do not have access by ssh to the. If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and enable them. You. Splunk Bucket Id Conflict.
From support.umbrella.com
Configuring Splunk with a Selfmanaged S3 Bucket Cisco Umbrella Splunk Bucket Id Conflict The db file will be copied in the thawed bucket and then it will go in bin directory. As you already know in splunk cloud you do not have access by ssh to the. If the bucket id is same then it will create conflicts. I've been following this guide: Hi, this error message started popping up, on splunk cloud.. Splunk Bucket Id Conflict.
From www.youtube.com
Splunk .conf 2016 buckets full of happy tiers YouTube Splunk Bucket Id Conflict But i'm a bit confused by the line: If the bucket id is same then it will create conflicts. You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in. So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally. Splunk Bucket Id Conflict.
From exobxaozf.blob.core.windows.net
Splunk Wiki Buckets at Esther Marler blog Splunk Bucket Id Conflict Hi, this error message started popping up, on splunk cloud. You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in. But i'm a bit confused by the line: As you already know in splunk cloud you do not have access by ssh to the. If the internal indexes. Splunk Bucket Id Conflict.
From joigrceso.blob.core.windows.net
Splunk Force Bucket Roll To Cold at Virginia blog Splunk Bucket Id Conflict As you already know in splunk cloud you do not have access by ssh to the. If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and enable them. Hi, this error message started popping up, on splunk cloud. I've been following this guide: If the bucket id. Splunk Bucket Id Conflict.
From community.splunk.com
Hot/Warm/Cold bucket sizing How do I set up my in... Splunk Community Splunk Bucket Id Conflict If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and enable them. But i'm a bit confused by the line: I've been following this guide: You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in.. Splunk Bucket Id Conflict.
From docs.splunk.com
Use adaptive response relay to send notable events from Splunk ES to Splunk Bucket Id Conflict I've been following this guide: Hi, this error message started popping up, on splunk cloud. To manually merge buckets from multiple legacy indexers onto one new indexer, i used these commands which work on rhel7/8: The db file will be copied in the thawed bucket and then it will go in bin directory. If the internal indexes are fine and. Splunk Bucket Id Conflict.
From exojmkyuh.blob.core.windows.net
Splunk Bucket Encryption at Terry Leach blog Splunk Bucket Id Conflict But i'm a bit confused by the line: I've been following this guide: The db file will be copied in the thawed bucket and then it will go in bin directory. To manually merge buckets from multiple legacy indexers onto one new indexer, i used these commands which work on rhel7/8: If the bucket id is same then it will. Splunk Bucket Id Conflict.
From velog.io
Splunk Bucket에 관하여 Splunk Bucket Id Conflict But i'm a bit confused by the line: So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally when splunkd adds. If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and enable them. If the bucket id is. Splunk Bucket Id Conflict.
From docs.splunk.com
Buckets and indexer clusters Splunk Documentation Splunk Bucket Id Conflict To manually merge buckets from multiple legacy indexers onto one new indexer, i used these commands which work on rhel7/8: But i'm a bit confused by the line: The db file will be copied in the thawed bucket and then it will go in bin directory. If the bucket id is same then it will create conflicts. If the internal. Splunk Bucket Id Conflict.
From www.thomashenson.com
6 Simple Splunk Transforming Commands Every Splunk User Should Know Splunk Bucket Id Conflict If the bucket id is same then it will create conflicts. But i'm a bit confused by the line: Hi, this error message started popping up, on splunk cloud. I've been following this guide: So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally when splunkd adds. As you already know. Splunk Bucket Id Conflict.
From exojmkyuh.blob.core.windows.net
Splunk Bucket Encryption at Terry Leach blog Splunk Bucket Id Conflict Hi, this error message started popping up, on splunk cloud. The db file will be copied in the thawed bucket and then it will go in bin directory. I've been following this guide: So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally when splunkd adds. As you already know in. Splunk Bucket Id Conflict.
From joigrceso.blob.core.windows.net
Splunk Force Bucket Roll To Cold at Virginia blog Splunk Bucket Id Conflict If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and enable them. I've been following this guide: You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in. To manually merge buckets from multiple legacy indexers. Splunk Bucket Id Conflict.
From www.youtube.com
Detect AWS S3 Public Buckets using Splunk YouTube Splunk Bucket Id Conflict I've been following this guide: Hi, this error message started popping up, on splunk cloud. So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally when splunkd adds. You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in. The. Splunk Bucket Id Conflict.
From joikjyzvz.blob.core.windows.net
Splunk Bucket Examples at Julie Myhre blog Splunk Bucket Id Conflict As you already know in splunk cloud you do not have access by ssh to the. So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally when splunkd adds. You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in.. Splunk Bucket Id Conflict.
From exojmkyuh.blob.core.windows.net
Splunk Bucket Encryption at Terry Leach blog Splunk Bucket Id Conflict I've been following this guide: But i'm a bit confused by the line: If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and enable them. The db file will be copied in the thawed bucket and then it will go in bin directory. As you already know. Splunk Bucket Id Conflict.
From community.splunk.com
New in Observability Cloud Explicit Bucket Histo... Splunk Community Splunk Bucket Id Conflict You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in. As you already know in splunk cloud you do not have access by ssh to the. If the bucket id is same then it will create conflicts. To manually merge buckets from multiple legacy indexers onto one new. Splunk Bucket Id Conflict.
From community.splunk.com
Duplicate Log Entries from S3 Bucket Splunk Community Splunk Bucket Id Conflict You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in. As you already know in splunk cloud you do not have access by ssh to the. I've been following this guide: If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list. Splunk Bucket Id Conflict.
From joikjyzvz.blob.core.windows.net
Splunk Bucket Examples at Julie Myhre blog Splunk Bucket Id Conflict The db file will be copied in the thawed bucket and then it will go in bin directory. As you already know in splunk cloud you do not have access by ssh to the. Hi, this error message started popping up, on splunk cloud. If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index. Splunk Bucket Id Conflict.
From www.youtube.com
Splunk Index buckets. YouTube Splunk Bucket Id Conflict So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally when splunkd adds. But i'm a bit confused by the line: If the bucket id is same then it will create conflicts. To manually merge buckets from multiple legacy indexers onto one new indexer, i used these commands which work on. Splunk Bucket Id Conflict.
From community.splunk.com
What is Splunk buckets default retention period? Splunk Community Splunk Bucket Id Conflict But i'm a bit confused by the line: You restore archived data by first moving an archived bucket into the thawed directory which you previously configured for its index in. If the bucket id is same then it will create conflicts. To manually merge buckets from multiple legacy indexers onto one new indexer, i used these commands which work on. Splunk Bucket Id Conflict.
From www.splunk.com
Threat hunting Splunk Splunk Bucket Id Conflict To manually merge buckets from multiple legacy indexers onto one new indexer, i used these commands which work on rhel7/8: If the bucket id is same then it will create conflicts. As you already know in splunk cloud you do not have access by ssh to the. I've been following this guide: Hi, this error message started popping up, on. Splunk Bucket Id Conflict.
From www.youtube.com
How to find Splunk Buckets status using dbinspect Tech Tonic with Splunk Bucket Id Conflict I've been following this guide: If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and enable them. If the bucket id is same then it will create conflicts. So, the root cause of bucket id conflicts is that two buckets have the same local sequence number accidentally. Splunk Bucket Id Conflict.
From www.youtube.com
Splunk Tips and Tricks Hot, Cold, and Warm Buckets Explained YouTube Splunk Bucket Id Conflict As you already know in splunk cloud you do not have access by ssh to the. If the bucket id is same then it will create conflicts. Hi, this error message started popping up, on splunk cloud. If the internal indexes are fine and splunk starts (if not, check splunkd.log), check the index list for any other disabled indexes and. Splunk Bucket Id Conflict.