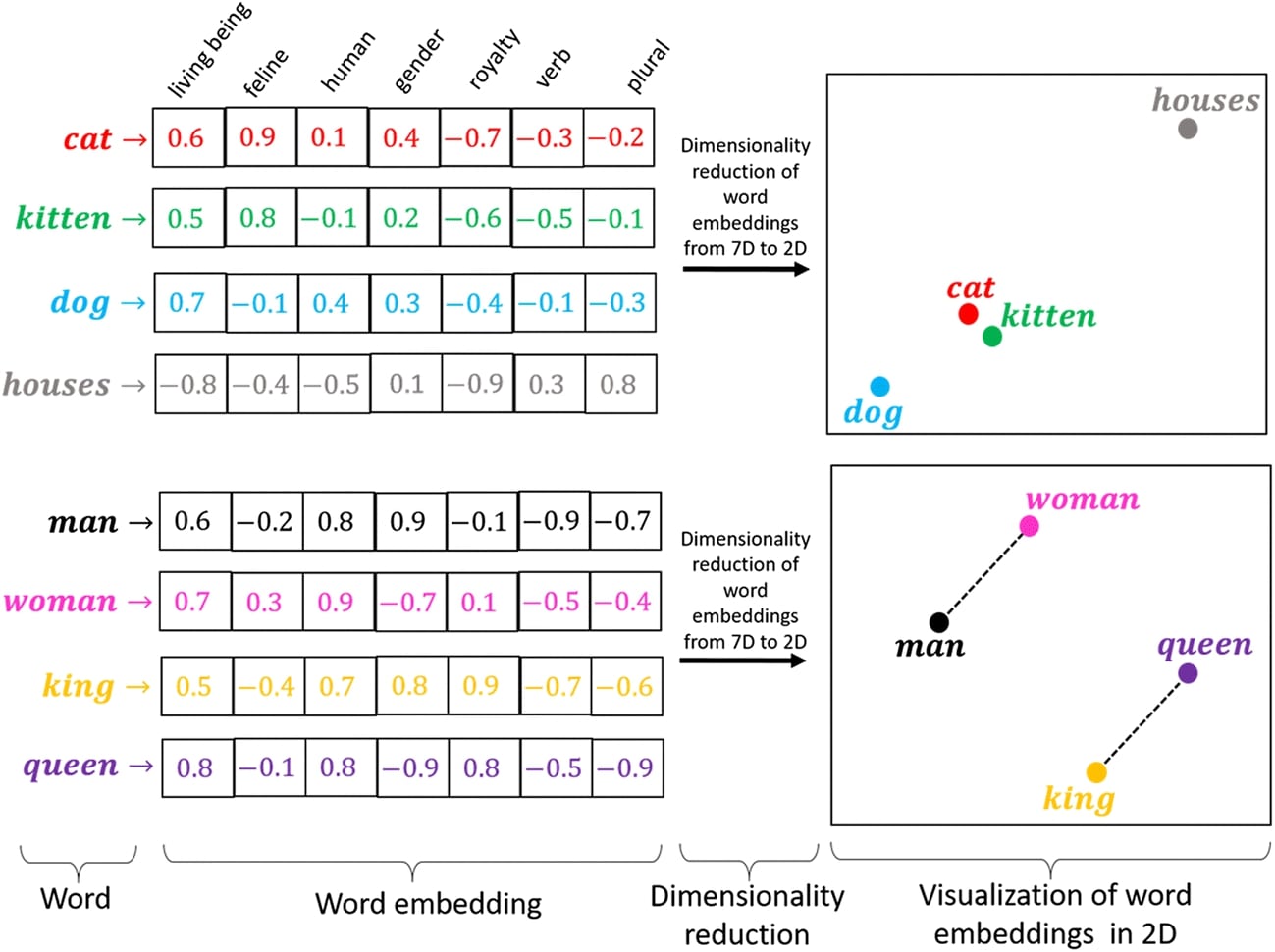
Torch One Hot Embedding . the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. A word index, you could use an. The idea of this post is. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. This mapping is done through an embedding matrix, which is a.
from coderzcolumn.com
A word index, you could use an. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. The idea of this post is. This mapping is done through an embedding matrix, which is a. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention.
How to Use GloVe Word Embeddings With PyTorch Networks?
Torch One Hot Embedding the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. This mapping is done through an embedding matrix, which is a. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. The idea of this post is. A word index, you could use an.
From www.dodomachine.com
Brazing Torch A Comprehensive Guide to Choosing the Right One Torch One Hot Embedding the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. This mapping is done through an embedding matrix, which is a. A word index, you could use an. The idea of this post is. Torch One Hot Embedding.
From coderzcolumn.com
How to Use GloVe Word Embeddings With PyTorch Networks? Torch One Hot Embedding The idea of this post is. This mapping is done through an embedding matrix, which is a. A word index, you could use an. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. Torch One Hot Embedding.
From wonderfulengineering.com
10 Best Cutting Torch Kits Torch One Hot Embedding This mapping is done through an embedding matrix, which is a. A word index, you could use an. The idea of this post is. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. Torch One Hot Embedding.
From aitechtogether.com
【Pytorch基础教程26】wide&deep推荐算法(tf2.0和torch版) AI技术聚合 Torch One Hot Embedding nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. This mapping is done through an embedding matrix, which is a. A word index, you could use an. The idea of this post is. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. Torch One Hot Embedding.
From discuss.pytorch.org
How does nn.Embedding work? PyTorch Forums Torch One Hot Embedding the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. The idea of this post is. This mapping is done through an embedding matrix, which is a. A word index, you could use an. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. Torch One Hot Embedding.
From zhuanlan.zhihu.com
【函数小trick】torch中scatter()、scatter_()详解(多标签onehot向量生成) 知乎 Torch One Hot Embedding the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. The idea of this post is. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. This mapping is done through an embedding matrix, which is a. A word index, you could use an. Torch One Hot Embedding.
From www.homedepot.ca
Bernzomatic TS4000KC High Heat Torch The Home Depot Canada Torch One Hot Embedding The idea of this post is. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. A word index, you could use an. This mapping is done through an embedding matrix, which is a. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. Torch One Hot Embedding.
From www.educba.com
PyTorch One Hot Encoding How to Create PyTorch One Hot Encoding? Torch One Hot Embedding nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. This mapping is done through an embedding matrix, which is a. The idea of this post is. A word index, you could use an. Torch One Hot Embedding.
From www.youtube.com
Garden Torch Hot Max Torches YouTube Torch One Hot Embedding nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. A word index, you could use an. This mapping is done through an embedding matrix, which is a. The idea of this post is. Torch One Hot Embedding.
From blog.csdn.net
torch.nn.Embedding()的固定化_embedding 固定初始化CSDN博客 Torch One Hot Embedding The idea of this post is. A word index, you could use an. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. This mapping is done through an embedding matrix, which is a. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. Torch One Hot Embedding.
From www.desertcart.ae
Buy BLUEFIRE Oxypropane Welding Torch Kit with Flint Lighter and Torch One Hot Embedding the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. This mapping is done through an embedding matrix, which is a. The idea of this post is. A word index, you could use an. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. Torch One Hot Embedding.
From exoultfcm.blob.core.windows.net
How Does An Air Acetylene Torch Work at Anthony Harris blog Torch One Hot Embedding The idea of this post is. This mapping is done through an embedding matrix, which is a. A word index, you could use an. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. Torch One Hot Embedding.
From www.conrad.com
Rothenberger Industrial HOT FIRE Blow torch Torch One Hot Embedding The idea of this post is. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. A word index, you could use an. This mapping is done through an embedding matrix, which is a. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. Torch One Hot Embedding.
From discuss.pytorch.org
torch.nn.Embedding() for text2image generation vision PyTorch Forums Torch One Hot Embedding A word index, you could use an. This mapping is done through an embedding matrix, which is a. The idea of this post is. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. Torch One Hot Embedding.
From www.youtube.com
U.S. PLY How to Torch Application Techniques YouTube Torch One Hot Embedding The idea of this post is. This mapping is done through an embedding matrix, which is a. A word index, you could use an. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. Torch One Hot Embedding.
From www.scaler.com
PyTorch Linear and PyTorch Embedding Layers Scaler Topics Torch One Hot Embedding nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. The idea of this post is. This mapping is done through an embedding matrix, which is a. A word index, you could use an. Torch One Hot Embedding.
From www.lowes.com
Gardner Bender Heat Shrink Butane Mini Torch in the Handheld Torches Torch One Hot Embedding This mapping is done through an embedding matrix, which is a. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. The idea of this post is. A word index, you could use an. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. Torch One Hot Embedding.
From www.smokecartel.com
Top 10 Best Butane Torches for Dabbing of 2023 Torch One Hot Embedding A word index, you could use an. The idea of this post is. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. This mapping is done through an embedding matrix, which is a. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. Torch One Hot Embedding.
From thewowdecor.com
How to Use a Butane Torch? · The Wow Decor Torch One Hot Embedding This mapping is done through an embedding matrix, which is a. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. A word index, you could use an. The idea of this post is. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. Torch One Hot Embedding.
From blog.csdn.net
【新闻文本分类】(task4)使用gensim训练word2vec_genism cbow 文本分类CSDN博客 Torch One Hot Embedding the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. This mapping is done through an embedding matrix, which is a. The idea of this post is. A word index, you could use an. Torch One Hot Embedding.
From www.desertcart.nz
Buy TAUSOM Propane Torch, Trigger Start p Torch Torch Kit with 3.6Ft Torch One Hot Embedding the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. This mapping is done through an embedding matrix, which is a. A word index, you could use an. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. The idea of this post is. Torch One Hot Embedding.
From blog.csdn.net
pytorch embedding层详解(从原理到实战)CSDN博客 Torch One Hot Embedding nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. A word index, you could use an. The idea of this post is. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. This mapping is done through an embedding matrix, which is a. Torch One Hot Embedding.
From bugtoolz.com
Rotary Position Embedding (RoPE, 旋转式位置编码) 原理讲解+torch代码实现 编程之家 Torch One Hot Embedding The idea of this post is. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. A word index, you could use an. This mapping is done through an embedding matrix, which is a. Torch One Hot Embedding.
From www.ganoksin.com
Jeweler's Torches Explained What Kind Do You Need? Ganoksin Jewelry Torch One Hot Embedding the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. The idea of this post is. A word index, you could use an. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. This mapping is done through an embedding matrix, which is a. Torch One Hot Embedding.
From blog.csdn.net
Pytorch基础(一)数据类型和创建数据_创建指定数据的torchCSDN博客 Torch One Hot Embedding The idea of this post is. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. A word index, you could use an. This mapping is done through an embedding matrix, which is a. Torch One Hot Embedding.
From www.aliexpress.com
Hot 920 Metal Flame Gun Welding Gas Torch Lighter Heating Ignition Torch One Hot Embedding nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. This mapping is done through an embedding matrix, which is a. A word index, you could use an. The idea of this post is. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. Torch One Hot Embedding.
From blog.csdn.net
pytorch 笔记: torch.nn.Embedding_pytorch embeding的权重CSDN博客 Torch One Hot Embedding A word index, you could use an. The idea of this post is. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. This mapping is done through an embedding matrix, which is a. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. Torch One Hot Embedding.
From www.internationaldiagnostic.com
BioFire Torch Filmarray RealTime PCR Module System International Torch One Hot Embedding the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. This mapping is done through an embedding matrix, which is a. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. The idea of this post is. A word index, you could use an. Torch One Hot Embedding.
From www.hotrod.com
A Better TIG Experience Hot Rod Network Torch One Hot Embedding The idea of this post is. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. A word index, you could use an. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. This mapping is done through an embedding matrix, which is a. Torch One Hot Embedding.
From blog.51cto.com
【Pytorch基础教程28】浅谈torch.nn.embedding_51CTO博客_Pytorch 教程 Torch One Hot Embedding This mapping is done through an embedding matrix, which is a. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. The idea of this post is. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. A word index, you could use an. Torch One Hot Embedding.
From t.zoukankan.com
pytorch中,嵌入层torch.nn.embedding的计算方式 走看看 Torch One Hot Embedding nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. A word index, you could use an. This mapping is done through an embedding matrix, which is a. The idea of this post is. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. Torch One Hot Embedding.
From www.bernzomatic.com
Bernzomatic Precision Torch Kit ST2250KC Torch One Hot Embedding A word index, you could use an. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. The idea of this post is. This mapping is done through an embedding matrix, which is a. Torch One Hot Embedding.
From machinelearningmastery.com
A Gentle Introduction to Positional Encoding in Transformer Models Torch One Hot Embedding the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. The idea of this post is. This mapping is done through an embedding matrix, which is a. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. A word index, you could use an. Torch One Hot Embedding.
From blog.csdn.net
注意力机制——transformer模型代码解析(机器翻译)_transformer注意力机制代码详解CSDN博客 Torch One Hot Embedding A word index, you could use an. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. The idea of this post is. This mapping is done through an embedding matrix, which is a. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. Torch One Hot Embedding.
From zhuanlan.zhihu.com
Torch.nn.Embedding的用法 知乎 Torch One Hot Embedding A word index, you could use an. This mapping is done through an embedding matrix, which is a. nn.embedding is a pytorch layer that maps indices from a fixed vocabulary to dense vectors of fixed size, known as embeddings. the torch.nn.attention.bias module contains attention_biases that are designed to be used with scaled_dot_product_attention. The idea of this post is. Torch One Hot Embedding.