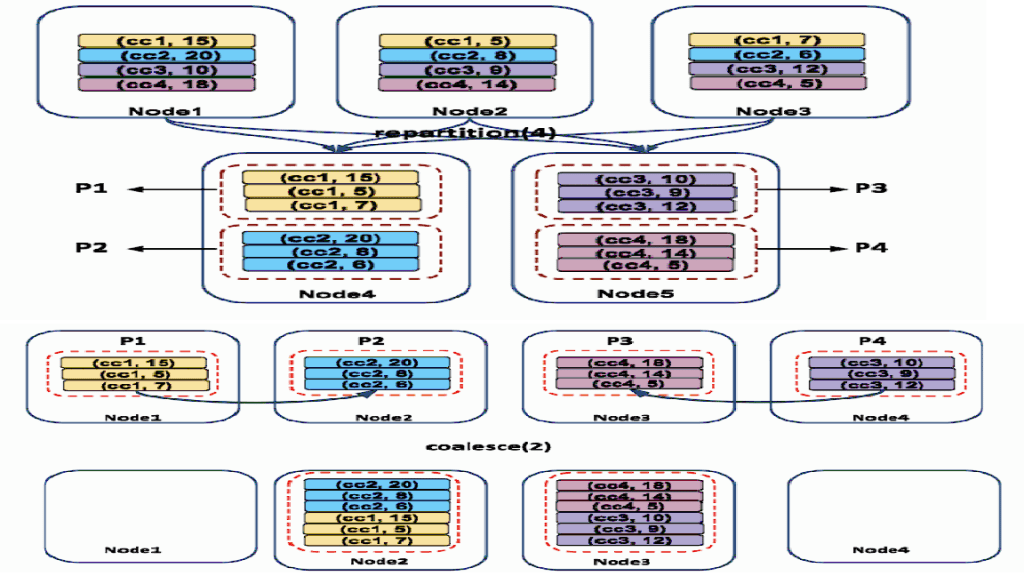
Partition Data In Pyspark . There are two functions you can use in spark to repartition data and coalesce is one of them. Union [int, columnorname], * cols: In this article, we will see different methods to perform data partition. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. This function is defined as the. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Repartitioning redistributes data across partitions by column or partition count. Use repartition() before joins, groupbys to avoid. Choosing the right partitioning method is crucial and depends on factors such as. The repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. Methods of data partitioning in pyspark. Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks.
from statusneo.com
Methods of data partitioning in pyspark. In this article, we will see different methods to perform data partition. Repartitioning redistributes data across partitions by column or partition count. Use repartition() before joins, groupbys to avoid. The repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. This function is defined as the. There are two functions you can use in spark to repartition data and coalesce is one of them. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. Choosing the right partitioning method is crucial and depends on factors such as. Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks.
Everything you need to understand Data Partitioning in Spark StatusNeo
Partition Data In Pyspark Use repartition() before joins, groupbys to avoid. Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Repartitioning redistributes data across partitions by column or partition count. This function is defined as the. There are two functions you can use in spark to repartition data and coalesce is one of them. Union [int, columnorname], * cols: Use repartition() before joins, groupbys to avoid. The repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Methods of data partitioning in pyspark. In this article, we will see different methods to perform data partition. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. Choosing the right partitioning method is crucial and depends on factors such as.
From www.programmingfunda.com
Top 30 PySpark DataFrame Methods with Example Partition Data In Pyspark Methods of data partitioning in pyspark. The repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. There are two functions you can use in spark to repartition data and coalesce is one of them. Repartitioning redistributes data across partitions by column or partition count. Union [int, columnorname], * cols: This operation. Partition Data In Pyspark.
From dzone.com
PySpark Java UDF Integration DZone Partition Data In Pyspark Union [int, columnorname], * cols: The repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. Use repartition() before joins, groupbys to avoid. Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Methods of data partitioning in pyspark. Choosing the right partitioning method is. Partition Data In Pyspark.
From giobtyevn.blob.core.windows.net
Df Rdd Getnumpartitions Pyspark at Lee Lemus blog Partition Data In Pyspark Methods of data partitioning in pyspark. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Union [int, columnorname], * cols: This function is defined as the. Explore partitioning and shuffling in pyspark. Partition Data In Pyspark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Partition Data In Pyspark In this article, we will see different methods to perform data partition. This function is defined as the. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Explore partitioning and shuffling in. Partition Data In Pyspark.
From pedropark99.github.io
Introduction to pyspark 7 Working with SQL in pyspark Partition Data In Pyspark Union [int, columnorname], * cols: This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. There are two functions you can use in spark to repartition data and coalesce is one of them. Use repartition() before joins, groupbys to avoid. This function is defined as the. Partitioning in. Partition Data In Pyspark.
From subhamkharwal.medium.com
PySpark — Dynamic Partition Overwrite by Subham Khandelwal Medium Partition Data In Pyspark Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Choosing the right partitioning method is crucial and depends on factors such as. Methods of data partitioning in pyspark. Use repartition() before joins, groupbys to avoid. Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. This function. Partition Data In Pyspark.
From klaojgfcx.blob.core.windows.net
How To Determine Number Of Partitions In Spark at Troy Powell blog Partition Data In Pyspark In this article, we will see different methods to perform data partition. Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. This function is defined as the. Partitioning in spark. Partition Data In Pyspark.
From www.youtube.com
How to use Map Transformation in PySpark using Databricks? Databricks Partition Data In Pyspark Methods of data partitioning in pyspark. Repartitioning redistributes data across partitions by column or partition count. Union [int, columnorname], * cols: Use repartition() before joins, groupbys to avoid. The repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. Explore partitioning and shuffling in pyspark and learn how these concepts impact your. Partition Data In Pyspark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Partition Data In Pyspark Union [int, columnorname], * cols: The repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Choosing the right partitioning method is crucial and depends on factors such as. Explore partitioning and shuffling in pyspark and learn. Partition Data In Pyspark.
From sparkbyexamples.com
PySpark RDD Tutorial Learn with Examples Spark By {Examples} Partition Data In Pyspark Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Choosing the right partitioning method is crucial and depends on factors such as. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. This function is defined as the. Partitioning in. Partition Data In Pyspark.
From webframes.org
How To Create Empty Dataframe In Pyspark With Column Names Partition Data In Pyspark Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. There are two functions you can use in spark to repartition data and coalesce is one of them. Repartitioning redistributes data across partitions by column or partition count. Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks.. Partition Data In Pyspark.
From datascienceparichay.com
Print Pyspark DataFrame Schema Data Science Parichay Partition Data In Pyspark Use repartition() before joins, groupbys to avoid. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. This function is defined as the. Methods of data partitioning in pyspark. Choosing the right partitioning method is crucial and depends on factors such as. Repartitioning redistributes data across partitions by. Partition Data In Pyspark.
From sparkbyexamples.com
PySpark partitionBy() Write to Disk Example Spark By {Examples} Partition Data In Pyspark Union [int, columnorname], * cols: The repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. In this article, we will see different methods to perform data partition. Methods of data partitioning in pyspark. This operation triggers. Partition Data In Pyspark.
From www.educba.com
PySpark mappartitions Learn the Internal Working and the Advantages Partition Data In Pyspark Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Union [int, columnorname], * cols: Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. There are two functions you can use in spark to repartition data and coalesce is one of them. This function is defined as. Partition Data In Pyspark.
From giobtyevn.blob.core.windows.net
Df Rdd Getnumpartitions Pyspark at Lee Lemus blog Partition Data In Pyspark Union [int, columnorname], * cols: This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. Choosing the right partitioning method is crucial and depends on factors such as. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Explore partitioning and shuffling in. Partition Data In Pyspark.
From sparkbyexamples.com
PySpark Create DataFrame with Examples Spark By {Examples} Partition Data In Pyspark Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. This function is defined as the. The repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting. Partition Data In Pyspark.
From www.ppmy.cn
PySpark基础入门(6):Spark Shuffle Partition Data In Pyspark There are two functions you can use in spark to repartition data and coalesce is one of them. Repartitioning redistributes data across partitions by column or partition count. Methods of data partitioning in pyspark. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Choosing the right partitioning method is crucial and depends on factors. Partition Data In Pyspark.
From www.oreilly.com
1. Introduction to Spark and PySpark Data Algorithms with Spark [Book] Partition Data In Pyspark Methods of data partitioning in pyspark. There are two functions you can use in spark to repartition data and coalesce is one of them. Repartitioning redistributes data across partitions by column or partition count. Use repartition() before joins, groupbys to avoid. Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Union [int,. Partition Data In Pyspark.
From azurelib.com
How to partition records in PySpark Azure Databricks? Partition Data In Pyspark In this article, we will see different methods to perform data partition. Methods of data partitioning in pyspark. This function is defined as the. Choosing the right partitioning method is crucial and depends on factors such as. The repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. Union [int, columnorname], *. Partition Data In Pyspark.
From builtin.com
A Complete Guide to PySpark DataFrames Built In Partition Data In Pyspark The repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. There are two functions you can use in spark to repartition data and coalesce is one of them. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. In. Partition Data In Pyspark.
From urlit.me
PySpark — Dynamic Partition Overwrite Partition Data In Pyspark In this article, we will see different methods to perform data partition. Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Union [int, columnorname], * cols: Choosing the right partitioning method is crucial and depends on factors such as. There are two functions you can use in spark to repartition data and. Partition Data In Pyspark.
From urlit.me
PySpark — Dynamic Partition Overwrite Partition Data In Pyspark Union [int, columnorname], * cols: In this article, we will see different methods to perform data partition. This function is defined as the. Methods of data partitioning in pyspark. Use repartition() before joins, groupbys to avoid. The repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. Explore partitioning and shuffling in. Partition Data In Pyspark.
From stackoverflow.com
python Repartitioning a pyspark dataframe fails and how to avoid the Partition Data In Pyspark Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Use repartition() before joins, groupbys to avoid. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly. Partition Data In Pyspark.
From www.youtube.com
Using PySpark on Dataproc Hadoop Cluster to process large CSV file Partition Data In Pyspark In this article, we will see different methods to perform data partition. Union [int, columnorname], * cols: Methods of data partitioning in pyspark. Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. The repartition() method in pyspark. Partition Data In Pyspark.
From www.youtube.com
Analysing Covid19 Dataset using Pyspark Part4 (Partition By & Window Partition Data In Pyspark This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Choosing the right partitioning method is crucial and depends on factors such as. This function is defined as the. Explore partitioning and shuffling. Partition Data In Pyspark.
From builtin.com
A Complete Guide to PySpark DataFrames Built In Partition Data In Pyspark The repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. Methods of data partitioning in pyspark. Use repartition() before joins, groupbys to avoid. There are two functions you can use in spark to repartition data and coalesce is one of them. This operation triggers a full shuffle of the data, which. Partition Data In Pyspark.
From ashishware.com
Creating scalable NLP pipelines using PySpark and Nlphose Partition Data In Pyspark Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Union [int, columnorname], * cols: This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. Methods of data partitioning in pyspark. This function is defined as the. The repartition() method in. Partition Data In Pyspark.
From medium.com
How does PySpark work? — step by step (with pictures) Partition Data In Pyspark Methods of data partitioning in pyspark. Repartitioning redistributes data across partitions by column or partition count. Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. The repartition() method in pyspark. Partition Data In Pyspark.
From ujjwalrastogi.hashnode.dev
Introduction to Big Data with pySpark Partition Data In Pyspark Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. This function is defined as the. Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. In this article, we will see different methods to perform data partition. Choosing the right partitioning method is crucial and depends on. Partition Data In Pyspark.
From fyojprmwb.blob.core.windows.net
Partition By Key Pyspark at Marjorie Lamontagne blog Partition Data In Pyspark Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Choosing the right partitioning method is crucial and depends on factors such as. There are two functions you can use in spark to repartition data and coalesce is one of them. Use repartition() before joins, groupbys to avoid. This operation triggers a full. Partition Data In Pyspark.
From ittutorial.org
PySpark RDD Example IT Tutorial Partition Data In Pyspark Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. There are two functions you can use in spark to repartition data and coalesce is one of them. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. Partitioning in spark. Partition Data In Pyspark.
From www.dataiku.com
How to use PySpark in Dataiku DSS Dataiku Partition Data In Pyspark Methods of data partitioning in pyspark. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. Union [int, columnorname], * cols: There are two functions you can use in spark to repartition data and coalesce is one of them. Partitioning in spark improves performance by reducing data shuffle. Partition Data In Pyspark.
From techvidvan.com
Apache Spark Partitioning and Spark Partition TechVidvan Partition Data In Pyspark Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Use repartition() before joins, groupbys to avoid. Union [int, columnorname], * cols: This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. Methods of data partitioning in pyspark. Repartitioning redistributes data. Partition Data In Pyspark.
From www.mamicode.com
[pySpark][笔记]spark tutorial from spark official site在ipython notebook 下 Partition Data In Pyspark Explore partitioning and shuffling in pyspark and learn how these concepts impact your big data processing tasks. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. This function is defined as the. There are two functions you can use in spark to repartition data and coalesce is one of them. This operation triggers a. Partition Data In Pyspark.
From www.youtube.com
100. Databricks Pyspark Spark Architecture Internals of Partition Partition Data In Pyspark This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. Use repartition() before joins, groupbys to avoid. This function is defined as the. The repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. Partitioning in spark improves performance by. Partition Data In Pyspark.