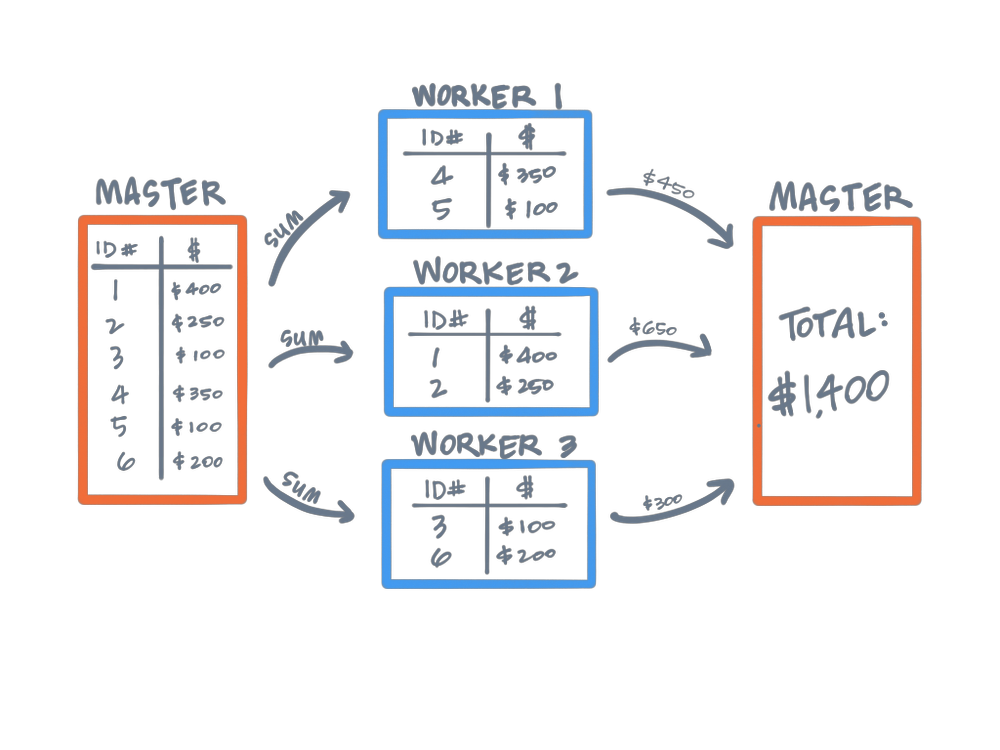
Types Of Partitions In Spark . In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. There are three main types of spark partitioning: In spark, these transformations are classified into two primary types: In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. Hash partitioning, range partitioning, and round robin partitioning. The main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in. Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. Narrow transformations and wide transformations. In a distributed computing environment, data is divided across multiple nodes to enable parallel. Each type offers unique benefits and considerations for data.
from www.jowanza.com
Each type offers unique benefits and considerations for data. The main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in. In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. In a distributed computing environment, data is divided across multiple nodes to enable parallel. Hash partitioning, range partitioning, and round robin partitioning. In spark, these transformations are classified into two primary types: There are three main types of spark partitioning: Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Narrow transformations and wide transformations.
Partitions in Apache Spark — Jowanza Joseph
Types Of Partitions In Spark There are three main types of spark partitioning: In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Each type offers unique benefits and considerations for data. The main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in. There are three main types of spark partitioning: Narrow transformations and wide transformations. Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. In a distributed computing environment, data is divided across multiple nodes to enable parallel. Hash partitioning, range partitioning, and round robin partitioning. In spark, these transformations are classified into two primary types: In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Types Of Partitions In Spark Narrow transformations and wide transformations. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. Each type offers unique benefits and considerations for data. Hash partitioning, range partitioning, and round robin partitioning. In. Types Of Partitions In Spark.
From techvidvan.com
Apache Spark Partitioning and Spark Partition TechVidvan Types Of Partitions In Spark There are three main types of spark partitioning: Narrow transformations and wide transformations. In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. In a distributed computing environment, data is divided across multiple nodes to enable parallel. In a simple manner, partitioning in data engineering means splitting. Types Of Partitions In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Types Of Partitions In Spark Narrow transformations and wide transformations. Each type offers unique benefits and considerations for data. In a distributed computing environment, data is divided across multiple nodes to enable parallel. Hash partitioning, range partitioning, and round robin partitioning. There are three main types of spark partitioning: Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and.. Types Of Partitions In Spark.
From andr83.io
How to work with Hive tables with a lot of partitions from Spark Andrei Tupitcyn Types Of Partitions In Spark In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. There are three main types of spark partitioning: In spark, these transformations are classified into two. Types Of Partitions In Spark.
From toien.github.io
Spark 分区数量 Kwritin Types Of Partitions In Spark In a distributed computing environment, data is divided across multiple nodes to enable parallel. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In spark, these transformations are classified into two primary types: Each type offers unique benefits and considerations for data. In this post, we’ll revisit a. Types Of Partitions In Spark.
From www.researchgate.net
Spark partition an LMDB Database Download Scientific Diagram Types Of Partitions In Spark In a distributed computing environment, data is divided across multiple nodes to enable parallel. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. Narrow transformations and wide transformations. The main abstraction spark. Types Of Partitions In Spark.
From www.scylladb.com
Apache Spark at ScyllaDB Summit, Part 1 Best Practices ScyllaDB Types Of Partitions In Spark Hash partitioning, range partitioning, and round robin partitioning. Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. There are three main types of spark partitioning: The main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that can be operated. Types Of Partitions In Spark.
From www.youtube.com
Apache Spark Data Partitioning Example YouTube Types Of Partitions In Spark There are three main types of spark partitioning: The main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in. Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. In a distributed computing environment, data. Types Of Partitions In Spark.
From dzone.com
Dynamic Partition Pruning in Spark 3.0 DZone Types Of Partitions In Spark Narrow transformations and wide transformations. In a distributed computing environment, data is divided across multiple nodes to enable parallel. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In spark, these transformations are classified into two primary types: Hash partitioning, range partitioning, and round robin partitioning. In this. Types Of Partitions In Spark.
From 0x0fff.com
Spark Architecture Shuffle Distributed Systems Architecture Types Of Partitions In Spark The main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In spark, these transformations are classified into two primary. Types Of Partitions In Spark.
From www.jowanza.com
Partitions in Apache Spark — Jowanza Joseph Types Of Partitions In Spark In spark, these transformations are classified into two primary types: In a distributed computing environment, data is divided across multiple nodes to enable parallel. Hash partitioning, range partitioning, and round robin partitioning. The main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that can be operated. Types Of Partitions In Spark.
From www.youtube.com
Why should we partition the data in spark? YouTube Types Of Partitions In Spark In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. Narrow transformations and wide transformations. In spark, these transformations are classified into two primary types: Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. Hash partitioning, range partitioning, and round. Types Of Partitions In Spark.
From izhangzhihao.github.io
Spark The Definitive Guide In Short — MyNotes Types Of Partitions In Spark In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. The main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in. Learn about the various partitioning strategies available,. Types Of Partitions In Spark.
From dzone.com
Dynamic Partition Pruning in Spark 3.0 DZone Types Of Partitions In Spark In a distributed computing environment, data is divided across multiple nodes to enable parallel. There are three main types of spark partitioning: Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. Each type offers unique benefits and considerations for data. In spark, these transformations are classified into two primary types: In a simple. Types Of Partitions In Spark.
From dzone.com
Dynamic Partition Pruning in Spark 3.0 DZone Types Of Partitions In Spark There are three main types of spark partitioning: Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. Hash partitioning, range partitioning, and round robin partitioning. The main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that can be operated. Types Of Partitions In Spark.
From techvidvan.com
Apache Spark Partitioning and Spark Partition TechVidvan Types Of Partitions In Spark In spark, these transformations are classified into two primary types: In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In a distributed computing environment, data is divided across multiple nodes to enable parallel. In this post, we’ll revisit a few details about partitioning in apache spark — from. Types Of Partitions In Spark.
From sparkbyexamples.com
Spark Partitioning & Partition Understanding Spark By {Examples} Types Of Partitions In Spark Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. The main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in. There are three main types of spark partitioning: In spark, these transformations are classified. Types Of Partitions In Spark.
From discover.qubole.com
Introducing Dynamic Partition Pruning Optimization for Spark Types Of Partitions In Spark Each type offers unique benefits and considerations for data. In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. Hash partitioning, range partitioning, and round robin partitioning. The main abstraction spark. Types Of Partitions In Spark.
From www.qwertee.io
Spark Secondary Sort Types Of Partitions In Spark There are three main types of spark partitioning: In a distributed computing environment, data is divided across multiple nodes to enable parallel. Each type offers unique benefits and considerations for data. In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. In spark, these transformations are classified. Types Of Partitions In Spark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Types Of Partitions In Spark Narrow transformations and wide transformations. In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. Each type offers unique benefits and considerations for data. There are three main types of spark partitioning: In a simple manner, partitioning in data engineering means splitting your data in smaller chunks. Types Of Partitions In Spark.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders Types Of Partitions In Spark In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. There are three main types of spark partitioning: Narrow transformations and wide transformations. In a distributed computing environment, data is divided across multiple. Types Of Partitions In Spark.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Types Of Partitions In Spark Narrow transformations and wide transformations. Each type offers unique benefits and considerations for data. Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. In a distributed computing environment, data is divided across multiple nodes to enable parallel. In spark, these transformations are classified into two primary types: In a simple manner, partitioning in. Types Of Partitions In Spark.
From www.cloudduggu.com
Apache Spark Transformations & Actions Tutorial CloudDuggu Types Of Partitions In Spark In spark, these transformations are classified into two primary types: In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Hash partitioning, range partitioning, and round robin partitioning. In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the. Types Of Partitions In Spark.
From www.youtube.com
Spark Application Partition By in Spark Chapter 2 LearntoSpark YouTube Types Of Partitions In Spark In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. Hash partitioning, range partitioning, and round robin partitioning. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Narrow transformations and wide transformations. In spark, these. Types Of Partitions In Spark.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient Types Of Partitions In Spark In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Each type offers unique benefits and considerations for data. Hash partitioning, range partitioning, and round robin partitioning. In a distributed computing environment, data is divided across multiple nodes to enable parallel. The main abstraction spark provides is a resilient. Types Of Partitions In Spark.
From medium.com
Dynamic Partition Pruning. Query performance optimization in Spark… by Amit Singh Rathore Types Of Partitions In Spark There are three main types of spark partitioning: In a distributed computing environment, data is divided across multiple nodes to enable parallel. Narrow transformations and wide transformations. In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. Each type offers unique benefits and considerations for data. The. Types Of Partitions In Spark.
From www.dezyre.com
How Data Partitioning in Spark helps achieve more parallelism? Types Of Partitions In Spark There are three main types of spark partitioning: Each type offers unique benefits and considerations for data. In spark, these transformations are classified into two primary types: Narrow transformations and wide transformations. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. The main abstraction spark provides is a. Types Of Partitions In Spark.
From spaziocodice.com
Spark SQL Partitions and Sizes SpazioCodice Types Of Partitions In Spark There are three main types of spark partitioning: Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. The main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in. In a simple manner, partitioning in. Types Of Partitions In Spark.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Salesforce Engineering Blog Types Of Partitions In Spark Hash partitioning, range partitioning, and round robin partitioning. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Narrow transformations and wide transformations. In spark, these transformations are classified into two primary types: In a distributed computing environment, data is divided across multiple nodes to enable parallel. There are. Types Of Partitions In Spark.
From dzone.com
Dynamic Partition Pruning in Spark 3.0 DZone Types Of Partitions In Spark Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. Each type offers unique benefits and considerations for data. In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. There are three main types of spark partitioning: In a distributed computing. Types Of Partitions In Spark.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Salesforce Engineering Blog Types Of Partitions In Spark In spark, these transformations are classified into two primary types: In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. There are three main types of spark partitioning: In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the. Types Of Partitions In Spark.
From medium.com
Spark Under The Hood Partition. Spark is a distributed computing engine… by Thejas Babu Medium Types Of Partitions In Spark In a distributed computing environment, data is divided across multiple nodes to enable parallel. Each type offers unique benefits and considerations for data. Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. The main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes. Types Of Partitions In Spark.
From medium.com
Managing Partitions with Spark. If you ever wonder why everyone moved… by Irem Ertuerk Medium Types Of Partitions In Spark Each type offers unique benefits and considerations for data. Learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. Hash partitioning, range partitioning, and round robin partitioning. In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. In a distributed computing. Types Of Partitions In Spark.
From cloud-fundis.co.za
Dynamically Calculating Spark Partitions at Runtime Cloud Fundis Types Of Partitions In Spark The main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in. In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. In a simple manner, partitioning in data. Types Of Partitions In Spark.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Types Of Partitions In Spark Narrow transformations and wide transformations. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In this post, we’ll revisit a few details about partitioning in apache spark — from reading parquet files to writing the results back. Learn about the various partitioning strategies available, including hash partitioning, range. Types Of Partitions In Spark.