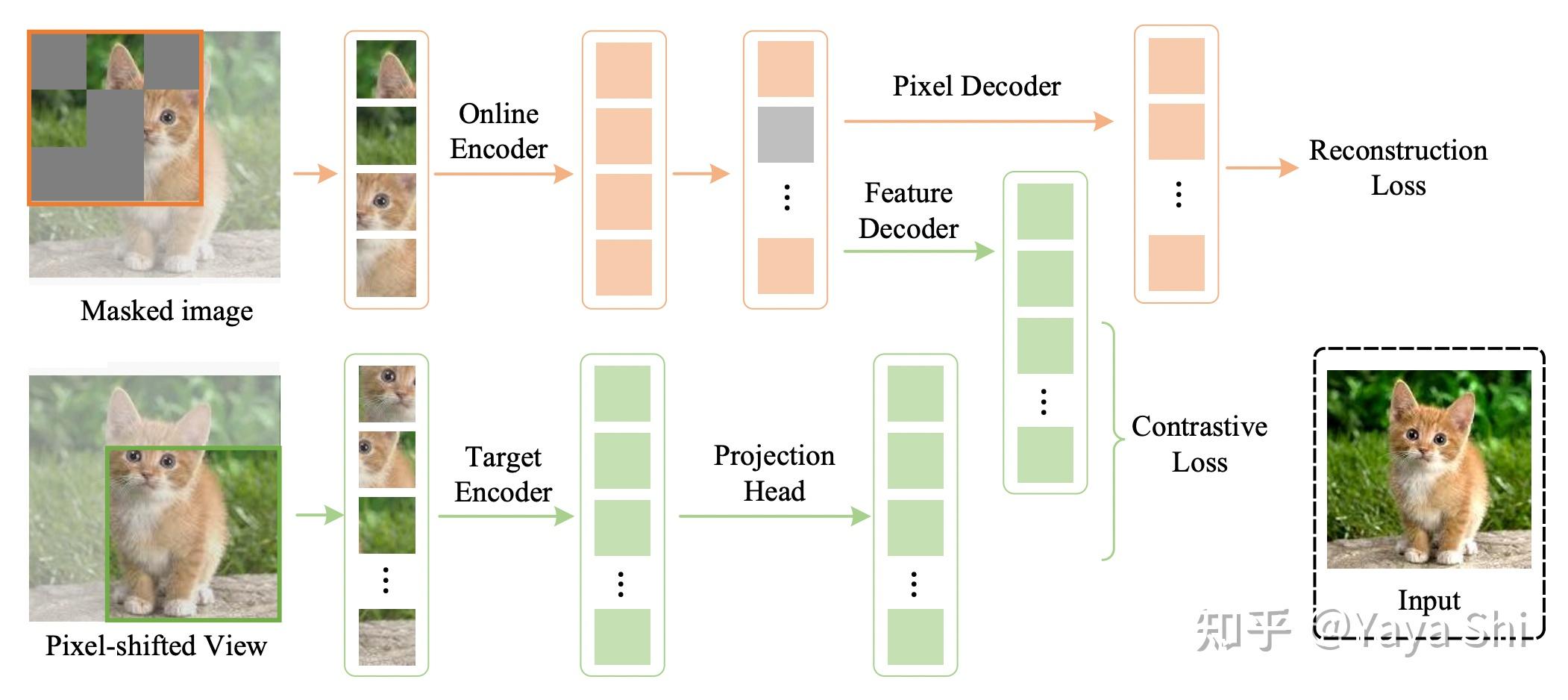
Multimodal Masked Autoencoders Learn Transferable Representations . 01 feb 2023, last modified: 11 mar 2024 submitted to iclr 2023 readers: to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. learn how to train a unified encoder for vision and language data via masked token prediction, without. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),.
from zhuanlan.zhihu.com
01 feb 2023, last modified: we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. 11 mar 2024 submitted to iclr 2023 readers: learn how to train a unified encoder for vision and language data via masked token prediction, without. to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a.
MIM in CV 知乎
Multimodal Masked Autoencoders Learn Transferable Representations 11 mar 2024 submitted to iclr 2023 readers: learn how to train a unified encoder for vision and language data via masked token prediction, without. to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. 11 mar 2024 submitted to iclr 2023 readers: this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. 01 feb 2023, last modified:
From deepai.org
Learning 3D Representations from 2D Pretrained Models via Imageto Multimodal Masked Autoencoders Learn Transferable Representations 11 mar 2024 submitted to iclr 2023 readers: to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. 01 feb 2023, last modified: learn how to train a unified encoder for vision and language data via masked token prediction, without. this paper proposes a simple and scalable network architecture,. Multimodal Masked Autoencoders Learn Transferable Representations.
From deepai.org
Multimodal Learning with ChannelMixing and Masked Autoencoder on Multimodal Masked Autoencoders Learn Transferable Representations we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. learn how to train a unified encoder for vision and language data via masked token prediction, without. to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. 01 feb 2023, last modified: 11 mar 2024 submitted. Multimodal Masked Autoencoders Learn Transferable Representations.
From deepai.org
Multimodal Masked Autoencoders Learn Compositional Histopathological Multimodal Masked Autoencoders Learn Transferable Representations 11 mar 2024 submitted to iclr 2023 readers: we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. 01 feb 2023, last modified: learn how to train a unified encoder for vision and language data via masked token prediction, without. this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. Multimodal Masked Autoencoders Learn Transferable Representations.
From www.pnas.org
Robust probabilistic modeling for singlecell multimodal mosaic Multimodal Masked Autoencoders Learn Transferable Representations 11 mar 2024 submitted to iclr 2023 readers: this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. 01. Multimodal Masked Autoencoders Learn Transferable Representations.
From www.frontiersin.org
Frontiers Multimodal Medical Supervised Image Fusion Method by CNN Multimodal Masked Autoencoders Learn Transferable Representations this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. 01 feb 2023, last modified: we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. 11 mar 2024 submitted to iclr 2023 readers: learn how to train a unified encoder for vision and language data via masked. Multimodal Masked Autoencoders Learn Transferable Representations.
From zhuanlan.zhihu.com
Masked Autoencoders Are Scalable Vision Learners.(Kaiming He,Arxiv2021 Multimodal Masked Autoencoders Learn Transferable Representations to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. learn how to train a unified encoder for vision and language data via masked token prediction, without. 11 mar 2024 submitted to iclr 2023 readers: 01 feb 2023, last modified: we propose a simple and scalable network architecture, the. Multimodal Masked Autoencoders Learn Transferable Representations.
From learnopencv.com
Variational Autoencoder in TensorFlow (Python Code) Multimodal Masked Autoencoders Learn Transferable Representations 01 feb 2023, last modified: learn how to train a unified encoder for vision and language data via masked token prediction, without. this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. 11 mar 2024 submitted to. Multimodal Masked Autoencoders Learn Transferable Representations.
From www.researchgate.net
Multimodal masked autoencoder (M3AE) consists of an encoder that maps Multimodal Masked Autoencoders Learn Transferable Representations 01 feb 2023, last modified: learn how to train a unified encoder for vision and language data via masked token prediction, without. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. 11 mar 2024 submitted. Multimodal Masked Autoencoders Learn Transferable Representations.
From www.semanticscholar.org
Figure 1 from CodeAligned Autoencoders for Unsupervised Change Multimodal Masked Autoencoders Learn Transferable Representations to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. 11 mar 2024 submitted to iclr 2023 readers: this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. . Multimodal Masked Autoencoders Learn Transferable Representations.
From www.semanticscholar.org
Figure 2 from Multimodal Masked Autoencoders Learn Transferable Multimodal Masked Autoencoders Learn Transferable Representations to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. 11 mar 2024 submitted to iclr 2023 readers: . Multimodal Masked Autoencoders Learn Transferable Representations.
From deepai.org
Multimodal Masked Autoencoders Learn Transferable Representations DeepAI Multimodal Masked Autoencoders Learn Transferable Representations this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. 11 mar 2024 submitted to iclr 2023 readers: 01 feb 2023, last modified: learn how to train a unified encoder for vision and language data via masked. Multimodal Masked Autoencoders Learn Transferable Representations.
From zhuanlan.zhihu.com
MIM in CV 知乎 Multimodal Masked Autoencoders Learn Transferable Representations learn how to train a unified encoder for vision and language data via masked token prediction, without. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. 11 mar 2024 submitted to iclr 2023 readers: 01 feb 2023, last modified: this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. Multimodal Masked Autoencoders Learn Transferable Representations.
From www.researchgate.net
Hyperparameters for linear classification on 1K Download Multimodal Masked Autoencoders Learn Transferable Representations we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. learn how to train a unified encoder for vision and language data via masked token prediction, without. 01 feb 2023, last modified: 11 mar 2024 submitted to. Multimodal Masked Autoencoders Learn Transferable Representations.
From www.researchgate.net
(PDF) Variational autoencoders learn transferrable representations of Multimodal Masked Autoencoders Learn Transferable Representations 11 mar 2024 submitted to iclr 2023 readers: we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. 01 feb 2023, last modified: to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. learn how to train a unified encoder for vision and language data via. Multimodal Masked Autoencoders Learn Transferable Representations.
From www.semanticscholar.org
[PDF] Multimodal Masked Autoencoders Learn Transferable Representations Multimodal Masked Autoencoders Learn Transferable Representations to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. 01 feb 2023, last modified: 11 mar 2024 submitted to iclr 2023 readers: learn how to train a unified encoder for vision. Multimodal Masked Autoencoders Learn Transferable Representations.
From www.v7labs.com
Autoencoders in Deep Learning Tutorial & Use Cases [2023] Multimodal Masked Autoencoders Learn Transferable Representations to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. 11 mar 2024 submitted to iclr 2023 readers: this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. 01. Multimodal Masked Autoencoders Learn Transferable Representations.
From zhuanlan.zhihu.com
MIM for CV and VL 知乎 Multimodal Masked Autoencoders Learn Transferable Representations 11 mar 2024 submitted to iclr 2023 readers: to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. learn how to train a unified encoder for vision and language data via masked token prediction, without. this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. Multimodal Masked Autoencoders Learn Transferable Representations.
From quantpedia.com
BERT Model Bidirectional Encoder Representations from Transformers Multimodal Masked Autoencoders Learn Transferable Representations 11 mar 2024 submitted to iclr 2023 readers: learn how to train a unified encoder for vision and language data via masked token prediction, without. 01 feb 2023, last modified: we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. to address the above limitations for visual representation learning, we propose a simple and. Multimodal Masked Autoencoders Learn Transferable Representations.
From www.researchgate.net
(PDF) Multimodal Masked Autoencoders Learn Transferable Representations Multimodal Masked Autoencoders Learn Transferable Representations 11 mar 2024 submitted to iclr 2023 readers: to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. learn how to train a unified encoder for vision and language data via masked. Multimodal Masked Autoencoders Learn Transferable Representations.
From deepai.org
SurgMAE Masked Autoencoders for Long Surgical Video Analysis DeepAI Multimodal Masked Autoencoders Learn Transferable Representations 11 mar 2024 submitted to iclr 2023 readers: 01 feb 2023, last modified: this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. to address the above limitations for visual representation learning, we propose a simple and. Multimodal Masked Autoencoders Learn Transferable Representations.
From paperswithcode.com
ConvMAE Masked Convolution Meets Masked Autoencoders Papers With Code Multimodal Masked Autoencoders Learn Transferable Representations this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. 11 mar 2024 submitted to iclr 2023 readers: 01. Multimodal Masked Autoencoders Learn Transferable Representations.
From zhuanlan.zhihu.com
MIM in CV 知乎 Multimodal Masked Autoencoders Learn Transferable Representations 11 mar 2024 submitted to iclr 2023 readers: to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. learn how to train a unified encoder for vision and language data via masked token prediction, without. 01 feb 2023, last modified: we propose a simple and scalable network architecture, the. Multimodal Masked Autoencoders Learn Transferable Representations.
From sparsey.com
Sparsey multimodal crossmodal learning Multimodal Masked Autoencoders Learn Transferable Representations learn how to train a unified encoder for vision and language data via masked token prediction, without. this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. 01 feb 2023, last modified: to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the.. Multimodal Masked Autoencoders Learn Transferable Representations.
From www.semanticscholar.org
[PDF] Multimodal Masked Autoencoders Learn Transferable Representations Multimodal Masked Autoencoders Learn Transferable Representations 11 mar 2024 submitted to iclr 2023 readers: 01 feb 2023, last modified: we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. learn how to train a unified encoder for vision and language data via masked. Multimodal Masked Autoencoders Learn Transferable Representations.
From paperswithcode.com
MultiMAE Multimodal Multitask Masked Autoencoders Papers With Code Multimodal Masked Autoencoders Learn Transferable Representations learn how to train a unified encoder for vision and language data via masked token prediction, without. to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. 01 feb 2023, last modified: 11 mar 2024 submitted to iclr 2023 readers: this paper proposes a simple and scalable network architecture,. Multimodal Masked Autoencoders Learn Transferable Representations.
From www.v7labs.com
An Introduction to Autoencoders Everything You Need to Know Multimodal Masked Autoencoders Learn Transferable Representations this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. 01 feb 2023, last modified: learn how to train a unified encoder for vision and language data via masked token prediction, without. 11 mar 2024 submitted to iclr 2023 readers: we propose a simple and scalable network architecture, the multimodal. Multimodal Masked Autoencoders Learn Transferable Representations.
From speakerdeck.com
Multimodal Masked Autoencoders Learn Transferable Representations Multimodal Masked Autoencoders Learn Transferable Representations 01 feb 2023, last modified: 11 mar 2024 submitted to iclr 2023 readers: this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. we propose a simple and scalable network architecture, the. Multimodal Masked Autoencoders Learn Transferable Representations.
From deepai.org
Efficient Video Representation Learning via Masked Video Modeling with Multimodal Masked Autoencoders Learn Transferable Representations we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. learn how to train a unified encoder for vision and language data via masked token prediction, without. 11 mar 2024 submitted to iclr 2023 readers: this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. to. Multimodal Masked Autoencoders Learn Transferable Representations.
From www.semanticscholar.org
Figure 2 from A vector quantized masked autoencoder for audiovisual Multimodal Masked Autoencoders Learn Transferable Representations this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. 01 feb 2023, last modified: 11 mar 2024 submitted. Multimodal Masked Autoencoders Learn Transferable Representations.
From zhuanlan.zhihu.com
MIM for CV and VL 知乎 Multimodal Masked Autoencoders Learn Transferable Representations 11 mar 2024 submitted to iclr 2023 readers: 01 feb 2023, last modified: to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. learn how to train a unified encoder for vision and language data via. Multimodal Masked Autoencoders Learn Transferable Representations.
From www.slideshare.net
Multimodal deep learning Multimodal Masked Autoencoders Learn Transferable Representations this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. 11 mar 2024 submitted to iclr 2023 readers: . Multimodal Masked Autoencoders Learn Transferable Representations.
From zhuanlan.zhihu.com
MIM for CV and VL 知乎 Multimodal Masked Autoencoders Learn Transferable Representations we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. 11 mar 2024 submitted to iclr 2023 readers: 01 feb 2023, last modified: to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder. Multimodal Masked Autoencoders Learn Transferable Representations.
From deepai.org
Learning Transferable Pedestrian Representation from Multimodal Multimodal Masked Autoencoders Learn Transferable Representations 01 feb 2023, last modified: this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. learn how to train a unified encoder for vision and language data via masked token prediction, without. to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the.. Multimodal Masked Autoencoders Learn Transferable Representations.
From velog.io
[논문리뷰]Masked Autoencoders Are Scalable Vision Learners Multimodal Masked Autoencoders Learn Transferable Representations to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. this paper proposes a simple and scalable network architecture, the multimodal masked autoencoder (m3ae), which learns a. learn how to train a unified encoder for vision and language data via masked token prediction, without. we propose a simple. Multimodal Masked Autoencoders Learn Transferable Representations.
From www.semanticscholar.org
Figure 1 from Learning Transferable Pedestrian Representation from Multimodal Masked Autoencoders Learn Transferable Representations to address the above limitations for visual representation learning, we propose a simple and scalable architecture called the. 11 mar 2024 submitted to iclr 2023 readers: we propose a simple and scalable network architecture, the multimodal masked autoencoder (m3ae),. 01 feb 2023, last modified: learn how to train a unified encoder for vision and language data via. Multimodal Masked Autoencoders Learn Transferable Representations.