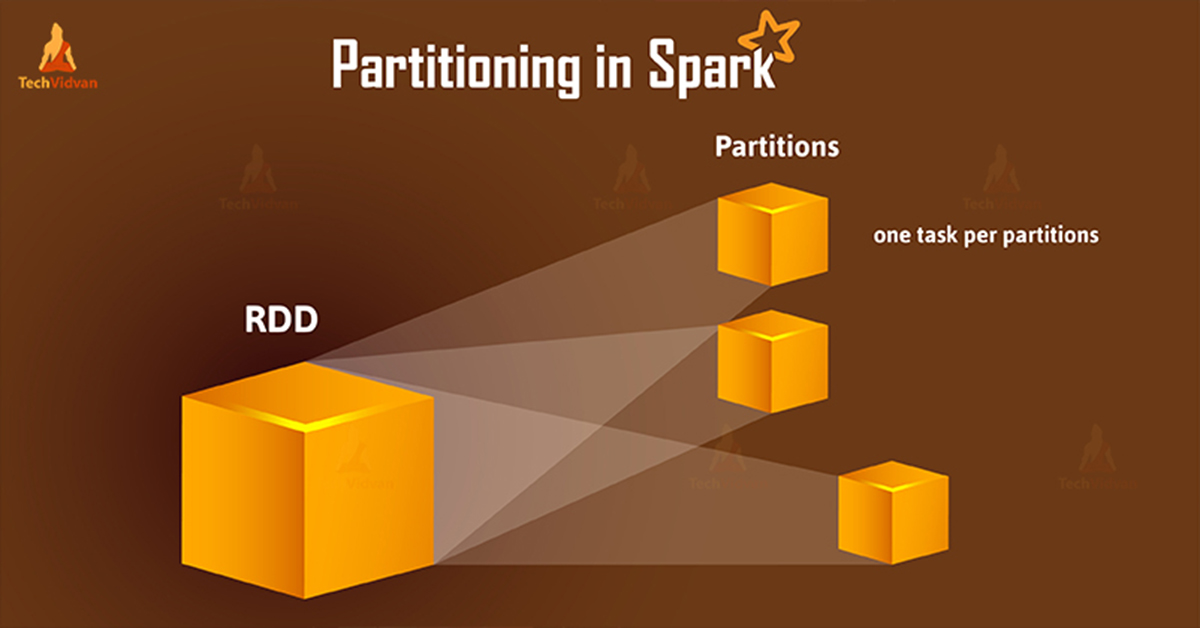
Partitions Output Spark . The number of output files saved to the disk is equal to the number of partitions in the spark executors when. See the syntax, types, and examples of. in a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. partitioning is nothing but dividing data structure into parts. In the context of apache spark, it can be defined as a dividing. the key to understanding: learn how to use partitioning hints to suggest a partitioning strategy to spark sql. spark partitioning is a key concept in optimizing the performance of data processing with spark. learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python and other languages. in apache spark, the spark.sql.shuffle.partitions configuration parameter plays a critical role in determining how data is. By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. In a distributed system like apache spark, it can be defined as a division of a.
from techvidvan.com
In a distributed system like apache spark, it can be defined as a division of a. spark partitioning is a key concept in optimizing the performance of data processing with spark. In the context of apache spark, it can be defined as a dividing. partitioning is nothing but dividing data structure into parts. in a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. learn how to use partitioning hints to suggest a partitioning strategy to spark sql. The number of output files saved to the disk is equal to the number of partitions in the spark executors when. the key to understanding: in apache spark, the spark.sql.shuffle.partitions configuration parameter plays a critical role in determining how data is. learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python and other languages.
Apache Spark Partitioning and Spark Partition TechVidvan
Partitions Output Spark spark partitioning is a key concept in optimizing the performance of data processing with spark. in a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In a distributed system like apache spark, it can be defined as a division of a. See the syntax, types, and examples of. By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. partitioning is nothing but dividing data structure into parts. the key to understanding: in apache spark, the spark.sql.shuffle.partitions configuration parameter plays a critical role in determining how data is. learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python and other languages. spark partitioning is a key concept in optimizing the performance of data processing with spark. In the context of apache spark, it can be defined as a dividing. learn how to use partitioning hints to suggest a partitioning strategy to spark sql. The number of output files saved to the disk is equal to the number of partitions in the spark executors when.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders Partitions Output Spark partitioning is nothing but dividing data structure into parts. See the syntax, types, and examples of. In a distributed system like apache spark, it can be defined as a division of a. The number of output files saved to the disk is equal to the number of partitions in the spark executors when. In the context of apache spark,. Partitions Output Spark.
From sparkbyexamples.com
Spark Get Current Number of Partitions of DataFrame Spark By {Examples} Partitions Output Spark learn how to use partitioning hints to suggest a partitioning strategy to spark sql. spark partitioning is a key concept in optimizing the performance of data processing with spark. in a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In a distributed system like apache spark,. Partitions Output Spark.
From developer.hpe.com
Tips and Best Practices to Take Advantage of Spark 2.x HPE Developer Portal Partitions Output Spark in a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. the key to understanding: partitioning is nothing but dividing data structure into parts. learn how to use resilient distributed datasets (rdds) in. Partitions Output Spark.
From www.jowanza.com
Partitions in Apache Spark — Jowanza Joseph Partitions Output Spark The number of output files saved to the disk is equal to the number of partitions in the spark executors when. See the syntax, types, and examples of. learn how to use partitioning hints to suggest a partitioning strategy to spark sql. In the context of apache spark, it can be defined as a dividing. partitioning is nothing. Partitions Output Spark.
From www.researchgate.net
(PDF) Spark as Data Supplier for MPI Deep Learning Processes Partitions Output Spark the key to understanding: See the syntax, types, and examples of. in apache spark, the spark.sql.shuffle.partitions configuration parameter plays a critical role in determining how data is. By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. partitioning is nothing but dividing data structure into parts. In a distributed system like apache spark, it. Partitions Output Spark.
From dzone.com
Dynamic Partition Pruning in Spark 3.0 DZone Partitions Output Spark partitioning is nothing but dividing data structure into parts. In a distributed system like apache spark, it can be defined as a division of a. See the syntax, types, and examples of. By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. learn how to use resilient distributed datasets (rdds) in spark, a parallel computing. Partitions Output Spark.
From 0x0fff.com
Spark Architecture Shuffle Distributed Systems Architecture Partitions Output Spark in a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In the context of apache spark, it can be defined as a dividing. learn how to use partitioning hints to suggest a partitioning strategy to spark sql. in apache spark, the spark.sql.shuffle.partitions configuration parameter plays a. Partitions Output Spark.
From developer.hpe.com
Spark 101 What Is It, What It Does, and Why It Matters HPE Developer Portal Partitions Output Spark spark partitioning is a key concept in optimizing the performance of data processing with spark. In the context of apache spark, it can be defined as a dividing. The number of output files saved to the disk is equal to the number of partitions in the spark executors when. learn how to use resilient distributed datasets (rdds) in. Partitions Output Spark.
From discover.qubole.com
Introducing Dynamic Partition Pruning Optimization for Spark Partitions Output Spark the key to understanding: In a distributed system like apache spark, it can be defined as a division of a. The number of output files saved to the disk is equal to the number of partitions in the spark executors when. learn how to use partitioning hints to suggest a partitioning strategy to spark sql. in apache. Partitions Output Spark.
From laptrinhx.com
Managing Partitions Using Spark Dataframe Methods LaptrinhX / News Partitions Output Spark By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. spark partitioning is a key concept in optimizing the performance of data processing with spark. in apache spark, the spark.sql.shuffle.partitions configuration parameter plays a critical role in determining how data is. the key to understanding: in a simple manner, partitioning in data engineering. Partitions Output Spark.
From spaziocodice.com
Spark SQL Partitions and Sizes SpazioCodice Partitions Output Spark spark partitioning is a key concept in optimizing the performance of data processing with spark. partitioning is nothing but dividing data structure into parts. In the context of apache spark, it can be defined as a dividing. In a distributed system like apache spark, it can be defined as a division of a. See the syntax, types, and. Partitions Output Spark.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Partitions Output Spark the key to understanding: In the context of apache spark, it can be defined as a dividing. See the syntax, types, and examples of. By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python and other languages. in. Partitions Output Spark.
From towardsdata.dev
Partitions and Bucketing in Spark towards data Partitions Output Spark the key to understanding: learn how to use partitioning hints to suggest a partitioning strategy to spark sql. in a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. in apache spark, the spark.sql.shuffle.partitions configuration parameter plays a critical role in determining how data is. The. Partitions Output Spark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Partitions Output Spark learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python and other languages. By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. learn how to use partitioning hints to suggest a partitioning strategy to spark sql. The number of output files saved to the disk is equal to. Partitions Output Spark.
From www.youtube.com
Apache Spark Dynamic Partition Pruning Spark Tutorial Part 11 YouTube Partitions Output Spark In the context of apache spark, it can be defined as a dividing. spark partitioning is a key concept in optimizing the performance of data processing with spark. By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. partitioning is nothing but dividing data structure into parts. in apache spark, the spark.sql.shuffle.partitions configuration parameter. Partitions Output Spark.
From www.researchgate.net
Spark partition an LMDB Database Download Scientific Diagram Partitions Output Spark the key to understanding: learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python and other languages. spark partitioning is a key concept in optimizing the performance of data processing with spark. In a distributed system like apache spark, it can be defined as a division of a. in apache. Partitions Output Spark.
From www.youtube.com
How to create partitions with parquet using spark YouTube Partitions Output Spark In a distributed system like apache spark, it can be defined as a division of a. learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python and other languages. spark partitioning is a key concept in optimizing the performance of data processing with spark. The number of output files saved to the. Partitions Output Spark.
From www.youtube.com
Spark Application Partition By in Spark Chapter 2 LearntoSpark YouTube Partitions Output Spark The number of output files saved to the disk is equal to the number of partitions in the spark executors when. learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python and other languages. By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. In the context of apache spark,. Partitions Output Spark.
From nebash.com
What's new in Apache Spark 3.0 dynamic partition pruning (2023) Partitions Output Spark in apache spark, the spark.sql.shuffle.partitions configuration parameter plays a critical role in determining how data is. in a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. The number of output files saved to the disk is equal to the number of partitions in the spark executors when.. Partitions Output Spark.
From zhuanlan.zhihu.com
深入浅出理解 Spark 部署与工作原理 知乎 Partitions Output Spark In the context of apache spark, it can be defined as a dividing. See the syntax, types, and examples of. By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. the key to understanding: learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python and other languages. partitioning. Partitions Output Spark.
From stackoverflow.com
optimization Spark AQE drastically reduces number of partitions Stack Overflow Partitions Output Spark See the syntax, types, and examples of. in a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. learn how to use partitioning hints to suggest a partitioning strategy to spark sql. By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. in apache. Partitions Output Spark.
From medium.com
Dynamic Partition Pruning. Query performance optimization in Spark… by Amit Singh Rathore Partitions Output Spark learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python and other languages. the key to understanding: See the syntax, types, and examples of. in apache spark, the spark.sql.shuffle.partitions configuration parameter plays a critical role in determining how data is. In a distributed system like apache spark, it can be defined. Partitions Output Spark.
From dzone.com
Dynamic Partition Pruning in Spark 3.0 DZone Partitions Output Spark learn how to use partitioning hints to suggest a partitioning strategy to spark sql. in apache spark, the spark.sql.shuffle.partitions configuration parameter plays a critical role in determining how data is. In a distributed system like apache spark, it can be defined as a division of a. In the context of apache spark, it can be defined as a. Partitions Output Spark.
From gyuhoonk.github.io
Partition, Spill in Spark Partitions Output Spark the key to understanding: By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. See the syntax, types, and examples of. In a distributed system like apache spark, it can be defined as a division of a. In the context of apache spark, it can be defined as a dividing. The number of output files saved. Partitions Output Spark.
From www.projectpro.io
How Data Partitioning in Spark helps achieve more parallelism? Partitions Output Spark The number of output files saved to the disk is equal to the number of partitions in the spark executors when. By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. spark partitioning is a key concept in optimizing the performance of data processing with spark. In a distributed system like apache spark, it can be. Partitions Output Spark.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient Partitions Output Spark in a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. spark partitioning is a key concept in optimizing the performance of data processing with spark. learn how to use partitioning hints to suggest a partitioning strategy to spark sql. the key to understanding: The number. Partitions Output Spark.
From sparkbyexamples.com
Get the Size of Each Spark Partition Spark By {Examples} Partitions Output Spark In the context of apache spark, it can be defined as a dividing. See the syntax, types, and examples of. By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. learn how to use partitioning hints to suggest a partitioning strategy to spark sql. in apache spark, the spark.sql.shuffle.partitions configuration parameter plays a critical role. Partitions Output Spark.
From zhuanlan.zhihu.com
Spark 之分区算子Repartition() vs Coalesce() 知乎 Partitions Output Spark The number of output files saved to the disk is equal to the number of partitions in the spark executors when. in a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python. Partitions Output Spark.
From www.youtube.com
How to partition and write DataFrame in Spark without deleting partitions with no new data Partitions Output Spark the key to understanding: learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python and other languages. partitioning is nothing but dividing data structure into parts. in apache spark, the spark.sql.shuffle.partitions configuration parameter plays a critical role in determining how data is. In a distributed system like apache spark, it. Partitions Output Spark.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Salesforce Engineering Blog Partitions Output Spark The number of output files saved to the disk is equal to the number of partitions in the spark executors when. In the context of apache spark, it can be defined as a dividing. the key to understanding: partitioning is nothing but dividing data structure into parts. in a simple manner, partitioning in data engineering means splitting. Partitions Output Spark.
From sparkbyexamples.com
Spark Partitioning & Partition Understanding Spark By {Examples} Partitions Output Spark learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python and other languages. partitioning is nothing but dividing data structure into parts. The number of output files saved to the disk is equal to the number of partitions in the spark executors when. In a distributed system like apache spark, it can. Partitions Output Spark.
From 0x0fff.com
Spark Architecture Shuffle Distributed Systems Architecture Partitions Output Spark See the syntax, types, and examples of. The number of output files saved to the disk is equal to the number of partitions in the spark executors when. learn how to use partitioning hints to suggest a partitioning strategy to spark sql. in apache spark, the spark.sql.shuffle.partitions configuration parameter plays a critical role in determining how data is.. Partitions Output Spark.
From www.youtube.com
Why should we partition the data in spark? YouTube Partitions Output Spark See the syntax, types, and examples of. The number of output files saved to the disk is equal to the number of partitions in the spark executors when. learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python and other languages. the key to understanding: in a simple manner, partitioning in. Partitions Output Spark.
From techvidvan.com
Apache Spark Partitioning and Spark Partition TechVidvan Partitions Output Spark By dividing data into smaller, manageable chunks, spark partitioning allows for more efficient. In a distributed system like apache spark, it can be defined as a division of a. learn how to use resilient distributed datasets (rdds) in spark, a parallel computing framework for python and other languages. in a simple manner, partitioning in data engineering means splitting. Partitions Output Spark.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Partitions Output Spark In the context of apache spark, it can be defined as a dividing. the key to understanding: The number of output files saved to the disk is equal to the number of partitions in the spark executors when. in a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined. Partitions Output Spark.