V100 Shared Memory . First introduced in nvidia tesla v100, the nvidia combined l1 data cache and shared memory subsystem. Void saxpy(int n, float a, float *x, float *y) { int i =. Given that the v100 allows the user to allocate up to 96 kb of shared memory per sm, and both a and b are 32 kb, there is enough space to pad. Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; It’s powered by nvidia volta.
from www.sobyte.net
Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. Given that the v100 allows the user to allocate up to 96 kb of shared memory per sm, and both a and b are 32 kb, there is enough space to pad. Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. Void saxpy(int n, float a, float *x, float *y) { int i =. The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. First introduced in nvidia tesla v100, the nvidia combined l1 data cache and shared memory subsystem. It’s powered by nvidia volta.
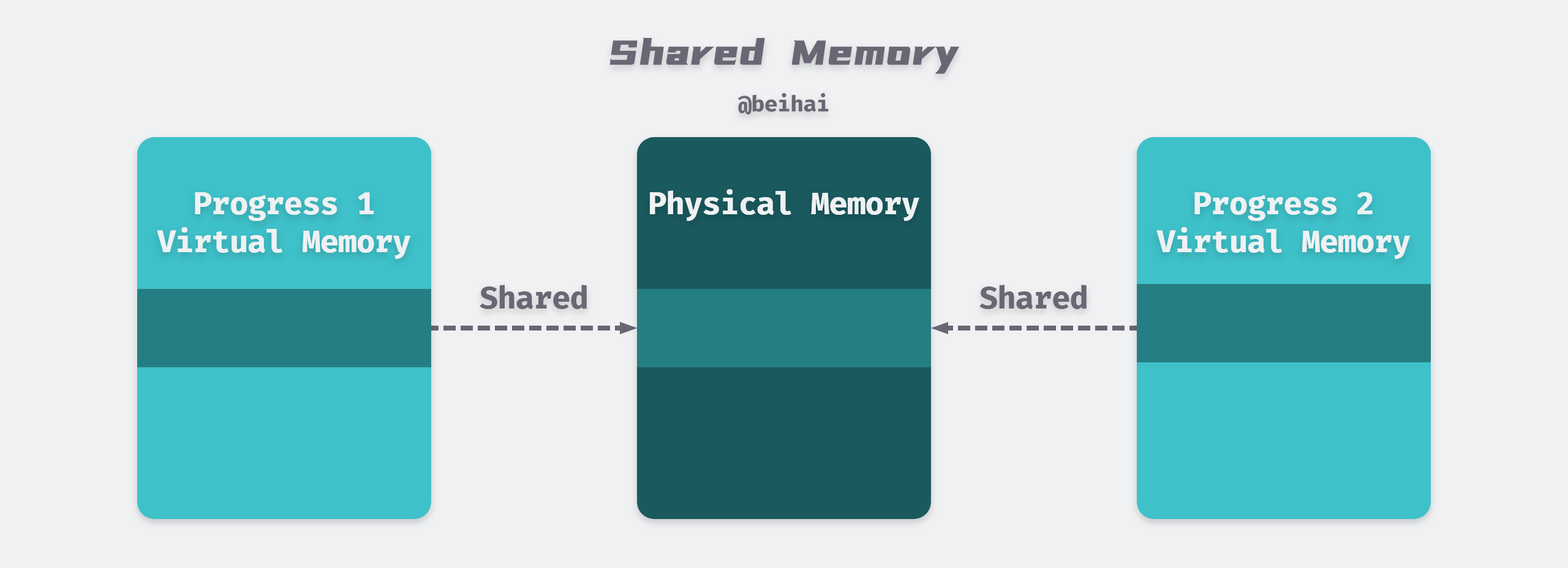
Virtual memory in Linux systems SoByte
V100 Shared Memory Void saxpy(int n, float a, float *x, float *y) { int i =. It’s powered by nvidia volta. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; Given that the v100 allows the user to allocate up to 96 kb of shared memory per sm, and both a and b are 32 kb, there is enough space to pad. First introduced in nvidia tesla v100, the nvidia combined l1 data cache and shared memory subsystem. Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. Void saxpy(int n, float a, float *x, float *y) { int i =.
From cvw.cac.cornell.edu
Cornell Virtual > Understanding GPU Architecture > GPU Memory V100 Shared Memory First introduced in nvidia tesla v100, the nvidia combined l1 data cache and shared memory subsystem. It’s powered by nvidia volta. Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory. V100 Shared Memory.
From www.slidestalk.com
7_Shared_Memory V100 Shared Memory Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. It’s powered by nvidia volta. First introduced. V100 Shared Memory.
From www.aliexpress.com
EMMC16G V100 16G emmc empty blank memory emmcin Integrated Circuits V100 Shared Memory The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. It’s powered by nvidia volta. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. First introduced in nvidia tesla v100, the nvidia combined l1 data. V100 Shared Memory.
From www.pldworld.com
Shared Memory vs Distributed Memory V100 Shared Memory Given that the v100 allows the user to allocate up to 96 kb of shared memory per sm, and both a and b are 32 kb, there is enough space to pad. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance.. V100 Shared Memory.
From www.scaler.com
What is Shared Memory in Linux? Scaler Topics V100 Shared Memory The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. It’s powered by nvidia volta. Void saxpy(int n, float a, float *x, float *y) { int i =. Given. V100 Shared Memory.
From slideplayer.com
SharedMemory Programming ppt download V100 Shared Memory It’s powered by nvidia volta. Void saxpy(int n, float a, float *x, float *y) { int i =. First introduced in nvidia tesla v100, the nvidia combined l1 data cache and shared memory subsystem. Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory. V100 Shared Memory.
From www.researchgate.net
Simplified GPU architecture for NVIDIA GeForce GTX 1080 Ti (orange V100 Shared Memory Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. First introduced in nvidia tesla v100, the nvidia combined l1 data cache and shared memory subsystem. The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. Std::transform(par, x, x+n,. V100 Shared Memory.
From wccftech.com
NVIDIA Volta GV100 12nm FinFET GPU Unveiled Tesla V100 Detailed V100 Shared Memory The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. It’s powered by nvidia volta. Void saxpy(int n, float a, float *x, float *y) { int i =. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared. V100 Shared Memory.
From studylib.net
CMSC 611 Advanced Computer Architecture Shared Memory V100 Shared Memory The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; First introduced in nvidia tesla v100, the nvidia combined l1 data cache and shared memory subsystem. Given that the v100 allows the user to allocate up to 96 kb of shared memory. V100 Shared Memory.
From www.linkedin.com
Compute.AI's Vertically Integrated vs Distributed Shared Memory Spark V100 Shared Memory The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. Void saxpy(int n, float a, float *x, float *y) { int i =. First introduced in. V100 Shared Memory.
From liujunming.top
Introduction to Shared Virtual Memory L V100 Shared Memory First introduced in nvidia tesla v100, the nvidia combined l1 data cache and shared memory subsystem. It’s powered by nvidia volta. Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. Given that the v100 allows the user to allocate up to. V100 Shared Memory.
From eric-lo.gitbook.io
Shared Memory Synchronization V100 Shared Memory Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. Given that the v100. V100 Shared Memory.
From www.primerpy.com
Linux Shared Memory PrimerPy V100 Shared Memory Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; Given that the v100 allows the user to allocate up to 96 kb of shared memory per sm, and both a and b are 32 kb, there is enough space to pad. The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared.. V100 Shared Memory.
From jwher.github.io
7가지 동시성 모델(소개) JWHer Tech Blog V100 Shared Memory Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; Void saxpy(int n, float a, float *x, float *y) { int i =. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. Given that the v100 allows the user. V100 Shared Memory.
From www.slidestalk.com
7_Shared_Memory V100 Shared Memory A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. First introduced in nvidia tesla v100, the nvidia combined l1 data cache and shared memory subsystem. Given that the v100 allows the user to allocate up to 96 kb of shared memory. V100 Shared Memory.
From www.reddit.com
Datasheet required (V100) r/AskElectronics V100 Shared Memory Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. Given that the v100 allows the user. V100 Shared Memory.
From www.youtube.com
DS28Distributed Shared Memory Algorithm for implementation Shared V100 Shared Memory Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; It’s powered by nvidia volta. Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. Given that the v100 allows the user to allocate up to 96 kb of shared memory per sm,. V100 Shared Memory.
From www.sobyte.net
Virtual memory in Linux systems SoByte V100 Shared Memory Void saxpy(int n, float a, float *x, float *y) { int i =. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; The nvidia ampere gpu architecture adds hardware. V100 Shared Memory.
From blog.engcore.ru
Межпроцессовое взаимодействие в Codesys. Разделяемая память(Shared V100 Shared Memory First introduced in nvidia tesla v100, the nvidia combined l1 data cache and shared memory subsystem. It’s powered by nvidia volta. The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. Given that the v100 allows the user to allocate up to 96 kb of shared memory per sm, and both a and b. V100 Shared Memory.
From studylib.net
Set 16 Distributed Shared Memory V100 Shared Memory Given that the v100 allows the user to allocate up to 96 kb of shared memory per sm, and both a and b are 32 kb, there is enough space to pad. Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. A key reason. V100 Shared Memory.
From www.gear4music.com
Vintage V100 Reissued FM, Thru Honeyburst at Gear4music V100 Shared Memory Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. First introduced in nvidia tesla v100, the. V100 Shared Memory.
From www.slidestalk.com
7_Shared_Memory V100 Shared Memory First introduced in nvidia tesla v100, the nvidia combined l1 data cache and shared memory subsystem. Void saxpy(int n, float a, float *x, float *y) { int i =. The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. It’s powered by nvidia volta. Given that the v100 allows the user to allocate up. V100 Shared Memory.
From www.youtube.com
Simple Shared Memory in C (mmap) YouTube V100 Shared Memory A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. Given that the v100 allows the user to allocate up to 96 kb of shared memory per sm, and both a and b are 32 kb, there is enough space to pad.. V100 Shared Memory.
From www.youtube.com
V100 Memory Management Virtual Memory (Part 1) YouTube V100 Shared Memory The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. First introduced in nvidia tesla v100, the nvidia combined l1 data cache and shared memory subsystem.. V100 Shared Memory.
From www.pngegg.com
Shared memory Memorymapped file Semaphore Race condition Mutual V100 Shared Memory It’s powered by nvidia volta. The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. Void saxpy(int n, float a, float *x, float *y) { int i =. Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; First introduced in nvidia tesla v100, the nvidia combined l1 data cache and shared. V100 Shared Memory.
From www.researchgate.net
16 Distributed shared memory architecture Download Scientific Diagram V100 Shared Memory It’s powered by nvidia volta. Given that the v100 allows the user to allocate up to 96 kb of shared memory per sm, and both a and b are 32 kb, there is enough space to pad. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the. V100 Shared Memory.
From devcodef1.com
Understanding CUDA Shared Memory for Medical Data Analysis on V100 GPUs V100 Shared Memory Void saxpy(int n, float a, float *x, float *y) { int i =. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. Std::transform(par, x, x+n,. V100 Shared Memory.
From developer.nvidia.com
CUDA Refresher The CUDA Programming Model NVIDIA Technical Blog V100 Shared Memory Void saxpy(int n, float a, float *x, float *y) { int i =. It’s powered by nvidia volta. Given that the v100 allows the user to allocate up to 96 kb of shared memory per sm, and both a and b are 32 kb, there is enough space to pad. A key reason to merge the l1 data cache with. V100 Shared Memory.
From www.slidestalk.com
7_Shared_Memory V100 Shared Memory Void saxpy(int n, float a, float *x, float *y) { int i =. It’s powered by nvidia volta. Given that the v100 allows the user to allocate up to 96 kb of shared memory per sm, and both a and b are 32 kb, there is enough space to pad. Nvidia ® v100 tensor core is the most advanced data. V100 Shared Memory.
From wccftech.com
NVIDIA Previewing 20nm Maxwell Architecture With Unified Memory V100 Shared Memory First introduced in nvidia tesla v100, the nvidia combined l1 data cache and shared memory subsystem. The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; It’s powered by nvidia volta. Nvidia ® v100 tensor core is the most advanced data center. V100 Shared Memory.
From binfintech.com
Distributed Shared Memory and its advantages and disadvantages V100 Shared Memory A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; Given that the v100 allows the user to allocate up to 96 kb of shared memory per sm, and both. V100 Shared Memory.
From www.youtube.com
Shared Memory Systems YouTube V100 Shared Memory The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache. V100 Shared Memory.
From pld.guru
Simplest Shared Memory System V100 Shared Memory Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. A key reason to merge the l1 data cache with shared memory in gv100 is to allow l1 cache operations to attain the benefits of shared memory performance. Given that the v100 allows the user. V100 Shared Memory.
From slideplayer.com
Lecture 27 Multiprocessors ppt download V100 Shared Memory The nvidia ampere gpu architecture adds hardware acceleration for copying data from global memory to shared. Std::transform(par, x, x+n, y, y, [=](float float y){ return y + a*x; It’s powered by nvidia volta. Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. Void saxpy(int. V100 Shared Memory.
From servernews.ru
Эра NVIDIA Volta началась с ускорителя Tesla V100 / ServerNews V100 Shared Memory Given that the v100 allows the user to allocate up to 96 kb of shared memory per sm, and both a and b are 32 kb, there is enough space to pad. Nvidia ® v100 tensor core is the most advanced data center gpu ever built to accelerate ai, high performance computing (hpc), data science and graphics. First introduced in. V100 Shared Memory.