Where Does Spark Store Data . Cache stores the dataframe in memory and disk. Any persist option which includes memory in it, spark will store that data in this. Storage memory is used for storing all of the cached data, broadcast variables are also stored here. When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this later). Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. Spark uses hdfs file system for data storage purposes. A cache prioritizes memory until there’s no more memory, then it stores the rest of the. It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc.
from engineeringblog.yelp.com
Any persist option which includes memory in it, spark will store that data in this. It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this later). Storage memory is used for storing all of the cached data, broadcast variables are also stored here. A cache prioritizes memory until there’s no more memory, then it stores the rest of the. Cache stores the dataframe in memory and disk. Spark uses hdfs file system for data storage purposes. Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use.
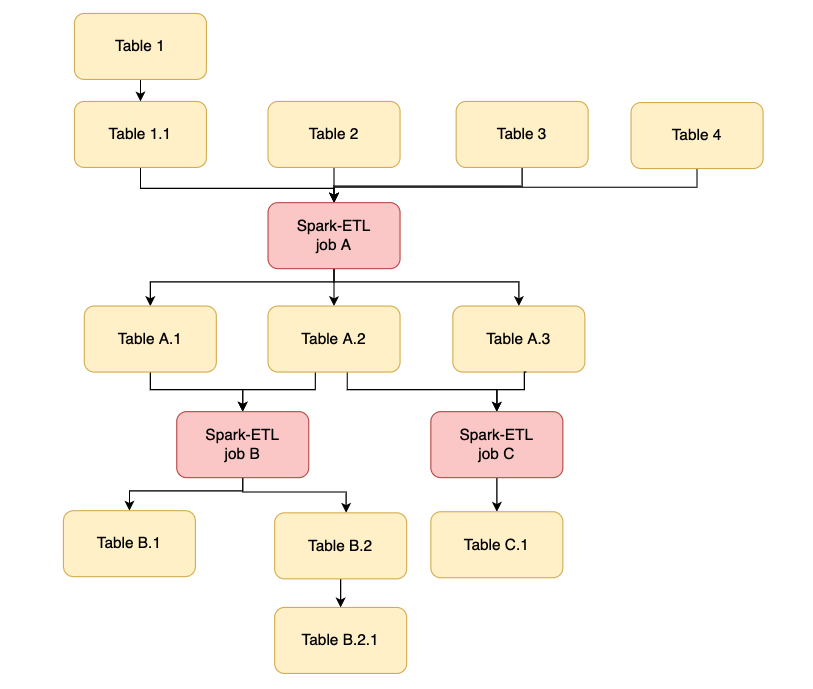
Spark Data Lineage
Where Does Spark Store Data Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. Storage memory is used for storing all of the cached data, broadcast variables are also stored here. A cache prioritizes memory until there’s no more memory, then it stores the rest of the. Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this later). Spark uses hdfs file system for data storage purposes. Any persist option which includes memory in it, spark will store that data in this. It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Cache stores the dataframe in memory and disk.
From www.pinterest.com
NEW REFERENCE ARCHITECTURE Batch scoring of Spark models on Azure Where Does Spark Store Data Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. Any persist option which includes memory in it, spark will store that data in this. Storage memory is used for storing all of the cached data, broadcast variables are also stored here. A cache prioritizes memory until. Where Does Spark Store Data.
From k21academy.com
Spark & MapReduce Introduction, Differences & Use Case Where Does Spark Store Data It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this. Where Does Spark Store Data.
From data-flair.training
Spark SQL Optimization Understanding the Catalyst Optimizer DataFlair Where Does Spark Store Data Storage memory is used for storing all of the cached data, broadcast variables are also stored here. Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Cache stores the dataframe in memory and. Where Does Spark Store Data.
From www.pinterest.com
Spark Streaming Diving into it's Architecture and Execution Model Where Does Spark Store Data Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this later). Spark uses hdfs file system for data storage purposes. A cache prioritizes. Where Does Spark Store Data.
From spoddutur.github.io
Building Realtime interactions with Spark sparknotes Where Does Spark Store Data Storage memory is used for storing all of the cached data, broadcast variables are also stored here. It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Any persist option which includes memory in it, spark will store that data in this. Cache stores the dataframe in memory and disk. Spark uses hdfs file system for data. Where Does Spark Store Data.
From jelvix.com
Spark vs Hadoop What to Choose to Process Big Data Where Does Spark Store Data When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this later). Storage memory is used for storing all of the cached data, broadcast variables are also stored here. Cache stores the dataframe in memory and disk. A cache prioritizes memory until there’s no more memory, then. Where Does Spark Store Data.
From engineeringblog.yelp.com
Spark Data Lineage Where Does Spark Store Data Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. Storage memory is used for storing all of the cached data, broadcast variables are also stored here. Any persist option which includes memory in it, spark will store that data in this. Cache stores the dataframe in. Where Does Spark Store Data.
From github.com
GitHub opensearchproject/opensearchspark Spark Accelerator Where Does Spark Store Data Any persist option which includes memory in it, spark will store that data in this. Cache stores the dataframe in memory and disk. When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this later). Storage memory is used for storing all of the cached data, broadcast. Where Does Spark Store Data.
From engineeringblog.yelp.com
Spark Data Lineage Where Does Spark Store Data Cache stores the dataframe in memory and disk. Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. A cache prioritizes memory until there’s no more memory, then it stores the rest of the. Spark uses hdfs file system for data storage purposes. It works with any. Where Does Spark Store Data.
From www.youtube.com
Big Data Analytics With Spark Big Data and Spark Tutorial Spark for Where Does Spark Store Data Any persist option which includes memory in it, spark will store that data in this. Spark uses hdfs file system for data storage purposes. Storage memory is used for storing all of the cached data, broadcast variables are also stored here. Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability,. Where Does Spark Store Data.
From www.edureka.co
Apache Spark Architecture Distributed System Architecture Explained Where Does Spark Store Data It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Storage memory is used for storing all of the cached data, broadcast variables are also stored here. Spark uses hdfs file system for data storage purposes. When you create a table in spark, it stores the data as a collection of files in a distributed file system. Where Does Spark Store Data.
From www.zdnet.com
A standard for storing big data? Apache Spark creators release open Where Does Spark Store Data Storage memory is used for storing all of the cached data, broadcast variables are also stored here. Spark uses hdfs file system for data storage purposes. Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. Any persist option which includes memory in it, spark will store. Where Does Spark Store Data.
From www.altexsoft.com
Apache Hadoop vs Spark Main Big Data Tools Explained Where Does Spark Store Data Any persist option which includes memory in it, spark will store that data in this. It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Storage memory is used for storing all of the cached data, broadcast variables are also stored here. A cache prioritizes memory until there’s no more memory, then it stores the rest of. Where Does Spark Store Data.
From developer.hpe.com
Spark 101 What Is It, What It Does, and Why It Matters HPE Developer Where Does Spark Store Data Any persist option which includes memory in it, spark will store that data in this. A cache prioritizes memory until there’s no more memory, then it stores the rest of the. Spark uses hdfs file system for data storage purposes. Storage memory is used for storing all of the cached data, broadcast variables are also stored here. When you create. Where Does Spark Store Data.
From staff.csie.ncu.edu.tw
SE6023 Lab4 Spark & Scala HackMD Where Does Spark Store Data Any persist option which includes memory in it, spark will store that data in this. Cache stores the dataframe in memory and disk. It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this. Where Does Spark Store Data.
From www.altexsoft.com
Apache Hadoop vs Spark Main Big Data Tools Explained AltexSoft Where Does Spark Store Data Storage memory is used for storing all of the cached data, broadcast variables are also stored here. Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. Cache stores the dataframe in memory and disk. Any persist option which includes memory in it, spark will store that. Where Does Spark Store Data.
From towardsdatascience.com
A Beginner’s Guide to Apache Spark by Dilyan Kovachev Towards Data Where Does Spark Store Data Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. Spark uses hdfs file system for data storage purposes. Storage memory is used for storing all of the cached data, broadcast variables are also stored here. It works with any hadoop compatible data source including hdfs, hbase,. Where Does Spark Store Data.
From www.acte.in
What is Spark Algorithm & Tutorial? Defined, Explained, & Explored ACTE Where Does Spark Store Data When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this later). It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. A cache prioritizes memory until there’s no more memory, then it stores the rest of the. Apache spark has emerged as one. Where Does Spark Store Data.
From itnext.io
Getting Started with Spark Structured Streaming and Kafka on AWS using Where Does Spark Store Data It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Storage memory is used for storing all of the cached data, broadcast variables are also stored here. When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this later). Spark uses hdfs file system. Where Does Spark Store Data.
From www.cloudduggu.com
Apache Spark Introduction Tutorial CloudDuggu Where Does Spark Store Data It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. Spark uses hdfs file system for data storage purposes. Storage memory is used for storing all of the cached data, broadcast variables are also. Where Does Spark Store Data.
From subscription.packtpub.com
What is the Spark Streaming application data flow? Learning PySpark Where Does Spark Store Data It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. Storage memory is used for storing all of the cached data, broadcast variables are also stored here. When you create a table in spark,. Where Does Spark Store Data.
From www.superoutlier.tech
Spark Streaming A Comprehensive Guide to RealTime Data Processing Where Does Spark Store Data When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this later). Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. Cache stores the dataframe in memory and disk. Storage memory is used. Where Does Spark Store Data.
From towardsdatascience.com
Modern Data Stack Which Place for Spark ? by Furcy Pin Towards Where Does Spark Store Data Cache stores the dataframe in memory and disk. Storage memory is used for storing all of the cached data, broadcast variables are also stored here. Any persist option which includes memory in it, spark will store that data in this. It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Apache spark has emerged as one of. Where Does Spark Store Data.
From www.youtube.com
Anatomy of a Spark Application DAG data dataengineering it spark Where Does Spark Store Data A cache prioritizes memory until there’s no more memory, then it stores the rest of the. When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this later). It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Spark uses hdfs file system for. Where Does Spark Store Data.
From forum.huawei.com
Create RDD in Apache Spark using Pyspark Analytics Vidhya Where Does Spark Store Data When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this later). Spark uses hdfs file system for data storage purposes. Cache stores the dataframe in memory and disk. It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Any persist option which includes. Where Does Spark Store Data.
From sparkbyexamples.com
Where Does Hive Stores Data Files in HDFS? Spark By {Examples} Where Does Spark Store Data Cache stores the dataframe in memory and disk. Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Any persist option which includes memory in it, spark will store that data in this. Storage. Where Does Spark Store Data.
From gaohaojun.cn
Apache Spark the New ‘king’ of Big Data Gao Haojun Where Does Spark Store Data Spark uses hdfs file system for data storage purposes. A cache prioritizes memory until there’s no more memory, then it stores the rest of the. Storage memory is used for storing all of the cached data, broadcast variables are also stored here. Cache stores the dataframe in memory and disk. Any persist option which includes memory in it, spark will. Where Does Spark Store Data.
From www.gatorsmile.io
What is Spark SQL? Developer Diaries of gatorsmile Apache Spark Where Does Spark Store Data When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this later). Spark uses hdfs file system for data storage purposes. Any persist option which includes memory in it, spark will store that data in this. A cache prioritizes memory until there’s no more memory, then it. Where Does Spark Store Data.
From www.youtube.com
How Does Spark Store Data Hadoop Interview Questions and Answers Where Does Spark Store Data It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Storage memory is used for storing all of the cached data, broadcast variables are also stored here. Spark uses hdfs file system for data storage purposes. Any persist option which includes memory in it, spark will store that data in this. Cache stores the dataframe in memory. Where Does Spark Store Data.
From www.youtube.com
PySpark Tutorial24 How Spark read and writes the data on AWS S3 Where Does Spark Store Data Any persist option which includes memory in it, spark will store that data in this. Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. Cache stores the dataframe in memory and disk. Spark uses hdfs file system for data storage purposes. It works with any hadoop. Where Does Spark Store Data.
From www.yurishwedoff.com
How To Find Data Blocks In Spark UI Yuri Shwedoff Where Does Spark Store Data It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. Any persist option which includes memory in it, spark will store that data in this. Spark uses hdfs file system for data storage purposes.. Where Does Spark Store Data.
From renovacloud.com
An Introduction to and Evaluation of Apache Spark for Big Data Where Does Spark Store Data Apache spark has emerged as one of the most popular big data processing frameworks due to its speed, scalability, and ease of use. Any persist option which includes memory in it, spark will store that data in this. A cache prioritizes memory until there’s no more memory, then it stores the rest of the. Storage memory is used for storing. Where Does Spark Store Data.
From github.com
GitHub infyprakash/bigdata Where Does Spark Store Data Spark uses hdfs file system for data storage purposes. Any persist option which includes memory in it, spark will store that data in this. A cache prioritizes memory until there’s no more memory, then it stores the rest of the. It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Storage memory is used for storing all. Where Does Spark Store Data.
From www.projectpro.io
A Beginners Guide to Spark Streaming Architecture with Example Where Does Spark Store Data When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this later). It works with any hadoop compatible data source including hdfs, hbase, cassandra, etc. Spark uses hdfs file system for data storage purposes. A cache prioritizes memory until there’s no more memory, then it stores the. Where Does Spark Store Data.
From techvidvan.com
Spark Streaming Architecture, Working and Operations TechVidvan Where Does Spark Store Data Storage memory is used for storing all of the cached data, broadcast variables are also stored here. A cache prioritizes memory until there’s no more memory, then it stores the rest of the. When you create a table in spark, it stores the data as a collection of files in a distributed file system (more on this later). Any persist. Where Does Spark Store Data.