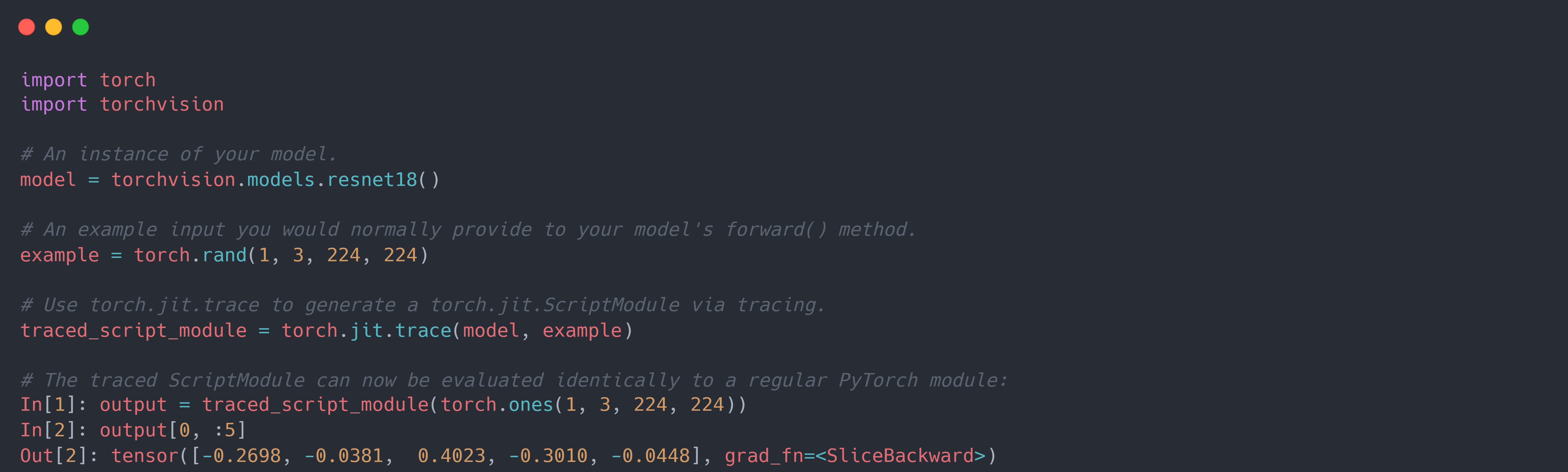
Torch.jit.trace Fp16 . for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the.
from cai-jianfeng.github.io
if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model.
The Basic Knowledge of TorchScript Cai Jianfeng
Torch.jit.trace Fp16 traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32.
From blog.csdn.net
【官方文档解读】torch.jit.script 的使用,并附上官方文档中的示例代码CSDN博客 Torch.jit.trace Fp16 if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. for example, castpolicy::fp16 is defined to cast the output to float16 but only if. Torch.jit.trace Fp16.
From blog.csdn.net
关于torch.jit.trace在yolov8中出现的问题CSDN博客 Torch.jit.trace Fp16 for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. the difference i see today is that lazy tensors trace & execute at the same time,. Torch.jit.trace Fp16.
From blog.csdn.net
[Yolov5][Pytorch] 如何jit trace yolov5模型_yolov5 torch.jit.traceCSDN博客 Torch.jit.trace Fp16 the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. . Torch.jit.trace Fp16.
From blog.csdn.net
关于torch.jit.trace在yolov8中出现的问题CSDN博客 Torch.jit.trace Fp16 for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get. Torch.jit.trace Fp16.
From github.com
torch.jit.trace error when custom autograd function used in the model Torch.jit.trace Fp16 to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. the. Torch.jit.trace Fp16.
From github.com
[jit] jit.trace segfault on variable slicing using `torch.narrow Torch.jit.trace Fp16 if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile. Torch.jit.trace Fp16.
From cai-jianfeng.github.io
The Basic Knowledge of TorchScript Cai Jianfeng Torch.jit.trace Fp16 first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks. Torch.jit.trace Fp16.
From github.com
如何在torch.jit.trace转换多输入的模型? · Issue 3858 · Tencent/ncnn · GitHub Torch.jit.trace Fp16 the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. for example, castpolicy::fp16. Torch.jit.trace Fp16.
From discuss.pytorch.org
How to ensure the correctness of the torch script jit PyTorch Forums Torch.jit.trace Fp16 for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. if. Torch.jit.trace Fp16.
From github.com
using torchjittrace to run your model on c++ · Issue 70 · vchoutas Torch.jit.trace Fp16 for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. if you must use torch.jit.trace. Torch.jit.trace Fp16.
From github.com
[torch.jit.trace] Indexing with ellipsis fixes the batch dimension Torch.jit.trace Fp16 for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. to accelerate inference on cpu by quantization to fp16, you may. Torch.jit.trace Fp16.
From blog.csdn.net
TorchScript (将动态图转为静态图)(模型部署)(jit)(torch.jit.trace)(torch.jit.script Torch.jit.trace Fp16 to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following. Torch.jit.trace Fp16.
From blog.csdn.net
关于torch.jit.trace在yolov8中出现的问题CSDN博客 Torch.jit.trace Fp16 if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. first, i use torch.jit.trace trace the model, and. Torch.jit.trace Fp16.
From blog.csdn.net
torch.jit.trace与torch.jit.script的区别CSDN博客 Torch.jit.trace Fp16 for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. to accelerate inference on cpu. Torch.jit.trace Fp16.
From github.com
`torch.jit.trace` memory usage increase although forward is constant Torch.jit.trace Fp16 to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first,. Torch.jit.trace Fp16.
From blog.csdn.net
关于torch.jit.trace在yolov8中出现的问题CSDN博客 Torch.jit.trace Fp16 to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be. Torch.jit.trace Fp16.
From github.com
`torch.jit.trace` memory usage increase although forward is constant Torch.jit.trace Fp16 to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. the difference i see today is. Torch.jit.trace Fp16.
From zhuanlan.zhihu.com
Pytorch编译机制的总结(来自吴芃老师) 知乎 Torch.jit.trace Fp16 the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. first, i use torch.jit.trace trace the model, and then use. Torch.jit.trace Fp16.
From github.com
Error Tracing the model using `torch.jit.trace` · Issue 34 · mileyan Torch.jit.trace Fp16 first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be. Torch.jit.trace Fp16.
From cai-jianfeng.github.io
The Basic Knowledge of TorchScript Cai Jianfeng Torch.jit.trace Fp16 for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. to accelerate inference on cpu by. Torch.jit.trace Fp16.
From github.com
torch.jit.trace() does not support variant length input? · Issue 15391 Torch.jit.trace Fp16 the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following. Torch.jit.trace Fp16.
From github.com
Running revision="fp16", torch_dtype=torch.float16 on mps M1 · Issue Torch.jit.trace Fp16 to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. first, i use. Torch.jit.trace Fp16.
From github.com
torch.jit.trace with pack_padded_sequence cannot do dynamic batch Torch.jit.trace Fp16 traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. if. Torch.jit.trace Fp16.
From blog.csdn.net
torchjitload(model_path) 失败原因CSDN博客 Torch.jit.trace Fp16 to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. first, i use torch.jit.trace trace the. Torch.jit.trace Fp16.
From blog.csdn.net
关于torch.jit.trace在yolov8中出现的问题CSDN博客 Torch.jit.trace Fp16 to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. traced_model = torch.jit.trace(roberta_model,. Torch.jit.trace Fp16.
From zhuanlan.zhihu.com
推理模型部署(一):ONNX runtime 实践 知乎 Torch.jit.trace Fp16 to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. if you must use torch.jit.trace as the ingestion mechanism, one possibility. Torch.jit.trace Fp16.
From blog.csdn.net
TorchScript (将动态图转为静态图)(模型部署)(jit)(torch.jit.trace)(torch.jit.script Torch.jit.trace Fp16 to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the. first, i use. Torch.jit.trace Fp16.
From github.com
Performance issue with torch.jit.trace(), slow prediction in C++ (CPU Torch.jit.trace Fp16 for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. if. Torch.jit.trace Fp16.
From www.educba.com
PyTorch JIT Script and Modules of PyTorch JIT with Example Torch.jit.trace Fp16 for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. first, i use torch.jit.trace trace the model, and then use. Torch.jit.trace Fp16.
From zhuanlan.zhihu.com
混合精度推理 知乎 Torch.jit.trace Fp16 first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be. Torch.jit.trace Fp16.
From github.com
Cannot trace model with torch.jit.trace · Issue 5 Torch.jit.trace Fp16 first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. if you must use torch.jit.trace as the ingestion mechanism, one possibility. Torch.jit.trace Fp16.
From github.com
torch.jit.load support specifying a target device. · Issue 775 Torch.jit.trace Fp16 first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. the difference i see today is that lazy tensors trace &. Torch.jit.trace Fp16.
From blog.csdn.net
Pytorch混合精度(FP16&FP32)(AMP自动混合精度)/半精度 训练(一) —— 原理(torch.half)CSDN博客 Torch.jit.trace Fp16 first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. the difference i see today is that lazy tensors trace & execute at the same time, while torch.jit.trace breaks the. if you must use torch.jit.trace. Torch.jit.trace Fp16.
From juejin.cn
TorchScript 系列解读(二):Torch jit tracer 实现解析 掘金 Torch.jit.trace Fp16 for example, castpolicy::fp16 is defined to cast the output to float16 but only if input is float32. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first,. Torch.jit.trace Fp16.
From github.com
torch.jit.trace returns unwrapped C type · Issue 20017 · pytorch Torch.jit.trace Fp16 traced_model = torch.jit.trace(roberta_model, (r_input_ids)) i get the following error. first, i use torch.jit.trace trace the model, and then use torch_tensorrt.compile compile the model. to accelerate inference on cpu by quantization to fp16, you may wanna try torch.bfloat16. if you must use torch.jit.trace as the ingestion mechanism, one possibility would be to torch.export first, and pass the.. Torch.jit.trace Fp16.