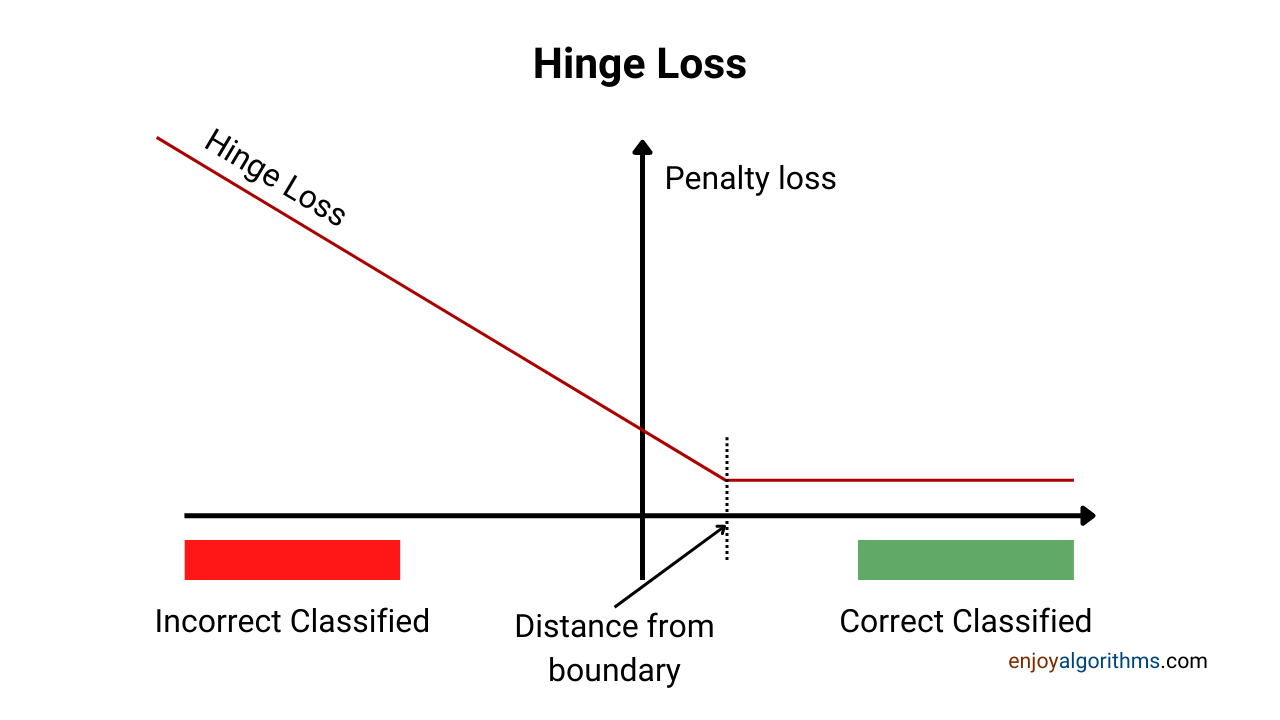
Hinge Loss Explained . Here is a really good visualisation. Introduction to the hinge loss function. — what is hinge loss? Hinge loss encourages svms to find hyperplanes with a large margin. Hinge loss is robust to noise in the data. Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’. In the realm of machine learning and optimization, the square hinge loss has emerged as a. — the hinge loss is a loss function used for training classifiers, most notably the svm. 1 (w · xj + b) yj ⌘. However, when yf(x) < 1 , then. Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. — hinge loss is a simple and efficient loss function to optimize. into the objective, we get:
from www.enjoyalgorithms.com
Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’. into the objective, we get: Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. — the hinge loss is a loss function used for training classifiers, most notably the svm. — hinge loss is a simple and efficient loss function to optimize. 1 (w · xj + b) yj ⌘. — what is hinge loss? Here is a really good visualisation. Introduction to the hinge loss function. However, when yf(x) < 1 , then.
Loss and Cost Function in Machine Learning
Hinge Loss Explained However, when yf(x) < 1 , then. into the objective, we get: — the hinge loss is a loss function used for training classifiers, most notably the svm. Here is a really good visualisation. Introduction to the hinge loss function. Hinge loss is robust to noise in the data. Hinge loss encourages svms to find hyperplanes with a large margin. 1 (w · xj + b) yj ⌘. However, when yf(x) < 1 , then. — what is hinge loss? In the realm of machine learning and optimization, the square hinge loss has emerged as a. — hinge loss is a simple and efficient loss function to optimize. Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’. Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘.
From www.iqsdirectory.com
Hinge What Is It? How Does It Work? Types & Considerations Hinge Loss Explained — what is hinge loss? into the objective, we get: — hinge loss is a simple and efficient loss function to optimize. Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’. In the realm of machine learning and optimization, the square hinge. Hinge Loss Explained.
From www.researchgate.net
17 The 0/1 loss function (green) is upper bound by the hinge loss Hinge Loss Explained However, when yf(x) < 1 , then. into the objective, we get: — what is hinge loss? Hinge loss encourages svms to find hyperplanes with a large margin. 1 (w · xj + b) yj ⌘. — the hinge loss is a loss function used for training classifiers, most notably the svm. Is defined as `hinge(y, ˆy). Hinge Loss Explained.
From zhuanlan.zhihu.com
一文弄懂各种loss function 知乎 Hinge Loss Explained Here is a really good visualisation. Hinge loss is robust to noise in the data. Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. Introduction to the hinge loss function. In the realm of machine learning and optimization, the square hinge loss has emerged as a. — the hinge loss is a loss function used for training classifiers, most. Hinge Loss Explained.
From www.researchgate.net
5 Loss functions for commonly used classifier hinge loss (SVM Hinge Loss Explained 1 (w · xj + b) yj ⌘. Here is a really good visualisation. In the realm of machine learning and optimization, the square hinge loss has emerged as a. into the objective, we get: Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’.. Hinge Loss Explained.
From www.researchgate.net
Double hinge loss function for positive examples, with P − = 0.4 and P Hinge Loss Explained — the hinge loss is a loss function used for training classifiers, most notably the svm. Introduction to the hinge loss function. 1 (w · xj + b) yj ⌘. — hinge loss is a simple and efficient loss function to optimize. Here is a really good visualisation. Hinge loss encourages svms to find hyperplanes with a large. Hinge Loss Explained.
From www.researchgate.net
Smoothed Hinge loss function, with δ = 0.5 Download Scientific Diagram Hinge Loss Explained 1 (w · xj + b) yj ⌘. — the hinge loss is a loss function used for training classifiers, most notably the svm. — hinge loss is a simple and efficient loss function to optimize. — what is hinge loss? Here is a really good visualisation. Introduction to the hinge loss function. Hinge loss encourages svms. Hinge Loss Explained.
From www.enjoyalgorithms.com
Loss and Cost Function in Machine Learning Hinge Loss Explained Introduction to the hinge loss function. 1 (w · xj + b) yj ⌘. Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’. Here is a really good visualisation. — what is hinge loss? — the hinge loss is a loss function used. Hinge Loss Explained.
From icode.best
理解原始Gan Loss 和 Hinge Gan Loss爱代码爱编程 Hinge Loss Explained Introduction to the hinge loss function. — hinge loss is a simple and efficient loss function to optimize. — the hinge loss is a loss function used for training classifiers, most notably the svm. However, when yf(x) < 1 , then. In the realm of machine learning and optimization, the square hinge loss has emerged as a. . Hinge Loss Explained.
From www.researchgate.net
The Robust Rescaled hinge loss function vs z with different η values Hinge Loss Explained 1 (w · xj + b) yj ⌘. Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’. — the hinge loss is a loss function used for training classifiers, most notably the svm. Hinge loss is robust to noise in the data. Hinge loss. Hinge Loss Explained.
From www.youtube.com
Hinge Loss for Binary Classifiers YouTube Hinge Loss Explained — the hinge loss is a loss function used for training classifiers, most notably the svm. Introduction to the hinge loss function. Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’. 1 (w · xj + b) yj ⌘. However, when yf(x) < 1. Hinge Loss Explained.
From www.researchgate.net
Hinge loss Hs(z) with Hinge point at 1 Download Scientific Diagram Hinge Loss Explained Here is a really good visualisation. Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’. — hinge loss is a simple and efficient loss function to optimize. Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. In the realm of machine learning and optimization,. Hinge Loss Explained.
From programmathically.com
Understanding Hinge Loss and the SVM Cost Function Programmathically Hinge Loss Explained However, when yf(x) < 1 , then. Introduction to the hinge loss function. Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’. — hinge loss is a simple and efficient loss function to optimize. Hinge loss encourages svms to find hyperplanes with a large. Hinge Loss Explained.
From programmathically.com
Understanding Hinge Loss and the SVM Cost Function Programmathically Hinge Loss Explained Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’. However, when yf(x) < 1 , then. Here is a really good visualisation. Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. Introduction to the hinge loss function. — what is hinge loss? Hinge loss. Hinge Loss Explained.
From zhuanlan.zhihu.com
hinge loss的一种实现方法 知乎 Hinge Loss Explained In the realm of machine learning and optimization, the square hinge loss has emerged as a. Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. Here is a really good visualisation. However, when yf(x) < 1 , then. — hinge loss is a simple and efficient loss function to optimize. — what is hinge loss? — the. Hinge Loss Explained.
From www.slideserve.com
PPT Soft Large Margin classifiers PowerPoint Presentation, free Hinge Loss Explained Introduction to the hinge loss function. — what is hinge loss? Hinge loss is robust to noise in the data. Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. — hinge loss is a simple and efficient loss function to optimize. Hinge loss encourages svms to find hyperplanes with a large margin. into the objective, we get:. Hinge Loss Explained.
From ai.stackexchange.com
neural networks How do I calculate the gradient of the hinge loss Hinge Loss Explained 1 (w · xj + b) yj ⌘. In the realm of machine learning and optimization, the square hinge loss has emerged as a. into the objective, we get: Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’. Hinge loss encourages svms to find. Hinge Loss Explained.
From sisyphus.gitbook.io
Hinge Loss The Truth of Sisyphus Hinge Loss Explained into the objective, we get: Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’. Hinge loss encourages svms to find hyperplanes with a large margin. In the realm of machine learning and optimization, the square. Hinge Loss Explained.
From www.researchgate.net
The hinge loss and the Huberized hinge loss (with δ = −1). Download Hinge Loss Explained Introduction to the hinge loss function. Here is a really good visualisation. In the realm of machine learning and optimization, the square hinge loss has emerged as a. — hinge loss is a simple and efficient loss function to optimize. — the hinge loss is a loss function used for training classifiers, most notably the svm. into. Hinge Loss Explained.
From www.baeldung.com
Differences Between Hinge Loss and Logistic Loss Baeldung on Computer Hinge Loss Explained Hinge loss is robust to noise in the data. Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’. Here is a really good visualisation. Hinge loss encourages svms to find hyperplanes with a large margin. into the objective, we get: However, when yf(x) <. Hinge Loss Explained.
From www.youtube.com
What is the Hinge Loss in SVM in Machine Learning Data Science Hinge Loss Explained In the realm of machine learning and optimization, the square hinge loss has emerged as a. Hinge loss is robust to noise in the data. — hinge loss is a simple and efficient loss function to optimize. — the hinge loss is a loss function used for training classifiers, most notably the svm. However, when yf(x) < 1. Hinge Loss Explained.
From www.youtube.com
Introduction to Hinge Loss Loss function SVM Machine Learning YouTube Hinge Loss Explained However, when yf(x) < 1 , then. — hinge loss is a simple and efficient loss function to optimize. Hinge loss is robust to noise in the data. 1 (w · xj + b) yj ⌘. Here is a really good visualisation. Hinge loss encourages svms to find hyperplanes with a large margin. In the realm of machine learning. Hinge Loss Explained.
From paperswithcode.com
GAN Hinge Loss Explained Papers With Code Hinge Loss Explained into the objective, we get: However, when yf(x) < 1 , then. — the hinge loss is a loss function used for training classifiers, most notably the svm. Introduction to the hinge loss function. — hinge loss is a simple and efficient loss function to optimize. In the realm of machine learning and optimization, the square hinge. Hinge Loss Explained.
From handwiki.org
Hinge loss HandWiki Hinge Loss Explained — hinge loss is a simple and efficient loss function to optimize. into the objective, we get: Hinge loss encourages svms to find hyperplanes with a large margin. Introduction to the hinge loss function. 1 (w · xj + b) yj ⌘. Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. However, when yf(x) < 1 , then.. Hinge Loss Explained.
From www.researchgate.net
The squared hinge loss functions for positive and negative labels Hinge Loss Explained — hinge loss is a simple and efficient loss function to optimize. Here is a really good visualisation. Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. In the realm of machine learning and optimization, the square hinge loss has emerged as a. Introduction to the hinge loss function. — the hinge loss is a loss function used. Hinge Loss Explained.
From github.com
GANHingeLoss/model.py at master · WangZesen/GANHingeLoss · GitHub Hinge Loss Explained 1 (w · xj + b) yj ⌘. — the hinge loss is a loss function used for training classifiers, most notably the svm. Hinge loss is robust to noise in the data. Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. However, when yf(x) < 1 , then. Looking at the graph for svm in fig 4, we. Hinge Loss Explained.
From programmathically.com
Understanding Hinge Loss and the SVM Cost Function Programmathically Hinge Loss Explained — hinge loss is a simple and efficient loss function to optimize. 1 (w · xj + b) yj ⌘. — what is hinge loss? into the objective, we get: — the hinge loss is a loss function used for training classifiers, most notably the svm. Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. Hinge. Hinge Loss Explained.
From www.researchgate.net
The marginbased Hinge loss function Download Scientific Diagram Hinge Loss Explained Here is a really good visualisation. Hinge loss is robust to noise in the data. — hinge loss is a simple and efficient loss function to optimize. Introduction to the hinge loss function. 1 (w · xj + b) yj ⌘. into the objective, we get: Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. In the realm. Hinge Loss Explained.
From www.researchgate.net
The hinge and the huberized hinge loss functions (with ¼ 2). Note that Hinge Loss Explained Here is a really good visualisation. — what is hinge loss? However, when yf(x) < 1 , then. — the hinge loss is a loss function used for training classifiers, most notably the svm. In the realm of machine learning and optimization, the square hinge loss has emerged as a. Is defined as `hinge(y, ˆy) = max 1. Hinge Loss Explained.
From stats.stackexchange.com
Visualizing the hinge loss and 01 loss Cross Validated Hinge Loss Explained Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is ‘ 0 ’. — hinge loss is a simple and efficient loss function to optimize. — what is hinge loss? In the realm of machine learning and optimization,. Hinge Loss Explained.
From www.youtube.com
Perceptron Loss Function Hinge Loss Binary Cross Entropy Sigmoid Hinge Loss Explained — what is hinge loss? In the realm of machine learning and optimization, the square hinge loss has emerged as a. — the hinge loss is a loss function used for training classifiers, most notably the svm. Looking at the graph for svm in fig 4, we can see that for yf(x) ≥ 1 , hinge loss is. Hinge Loss Explained.
From www.researchgate.net
Hinge loss function and squared hinge loss function. Download Hinge Loss Explained into the objective, we get: In the realm of machine learning and optimization, the square hinge loss has emerged as a. Hinge loss is robust to noise in the data. Introduction to the hinge loss function. However, when yf(x) < 1 , then. Looking at the graph for svm in fig 4, we can see that for yf(x) ≥. Hinge Loss Explained.
From www.youtube.com
42 Hinge Loss Cost Function for SVM Classifier YouTube Hinge Loss Explained Hinge loss encourages svms to find hyperplanes with a large margin. — hinge loss is a simple and efficient loss function to optimize. Introduction to the hinge loss function. Hinge loss is robust to noise in the data. — the hinge loss is a loss function used for training classifiers, most notably the svm. In the realm of. Hinge Loss Explained.
From www.theaidream.com
Loss Functions in Neural Networks Hinge Loss Explained 1 (w · xj + b) yj ⌘. Here is a really good visualisation. Introduction to the hinge loss function. In the realm of machine learning and optimization, the square hinge loss has emerged as a. — hinge loss is a simple and efficient loss function to optimize. — what is hinge loss? Hinge loss is robust to. Hinge Loss Explained.
From www.researchgate.net
The geometric description of the hinge loss and ramp loss functions Hinge Loss Explained — hinge loss is a simple and efficient loss function to optimize. — the hinge loss is a loss function used for training classifiers, most notably the svm. Introduction to the hinge loss function. Hinge loss is robust to noise in the data. Hinge loss encourages svms to find hyperplanes with a large margin. Looking at the graph. Hinge Loss Explained.
From www.researchgate.net
A comparison of Hard Margin Loss, Hinge Loss and Rescaled Hinge Loss Hinge Loss Explained Is defined as `hinge(y, ˆy) = max 1 ˆyy⌘. 1 (w · xj + b) yj ⌘. — the hinge loss is a loss function used for training classifiers, most notably the svm. Here is a really good visualisation. In the realm of machine learning and optimization, the square hinge loss has emerged as a. — hinge loss. Hinge Loss Explained.