Map Partition Spark Java Example . For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. The mappartitionsfunction in the apache spark java api is designed for transforming an rdd (resilient distributed. To address this issue, spark provides the mappartitions() function, which allows you to apply a function to each partition. In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of an rdd (resilient. Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and returns the new Tweak them based on your data and cluster size. Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. We use spark's ui to monitor task times and shuffle read/write times. Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. This will give you insights into whether you need to repartition your data.
from www.tpsearchtool.com
Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. The mappartitionsfunction in the apache spark java api is designed for transforming an rdd (resilient distributed. This will give you insights into whether you need to repartition your data. Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. We use spark's ui to monitor task times and shuffle read/write times. Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and returns the new For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of an rdd (resilient. To address this issue, spark provides the mappartitions() function, which allows you to apply a function to each partition. Tweak them based on your data and cluster size.
Java Sort Map By Key Ascending And Descending Orders Images
Map Partition Spark Java Example Tweak them based on your data and cluster size. For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. We use spark's ui to monitor task times and shuffle read/write times. Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. Tweak them based on your data and cluster size. The mappartitionsfunction in the apache spark java api is designed for transforming an rdd (resilient distributed. This will give you insights into whether you need to repartition your data. Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and returns the new Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. To address this issue, spark provides the mappartitions() function, which allows you to apply a function to each partition. In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of an rdd (resilient.
From sparkbyexamples.com
Spark UI Understanding Spark Execution Spark By {Examples} Map Partition Spark Java Example Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. This will give you insights into whether you need to repartition your data. For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. The mappartitionsfunction in the apache spark java. Map Partition Spark Java Example.
From jsmithmoore.com
Dataframe map spark java Map Partition Spark Java Example Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. This will give you insights into whether you need to repartition your data. Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. We use spark's ui to monitor task times and shuffle read/write times. For example, we see this scala code. Map Partition Spark Java Example.
From 0x0fff.com
Spark Architecture Shuffle Distributed Systems Architecture Map Partition Spark Java Example To address this issue, spark provides the mappartitions() function, which allows you to apply a function to each partition. Tweak them based on your data and cluster size. The mappartitionsfunction in the apache spark java api is designed for transforming an rdd (resilient distributed. This will give you insights into whether you need to repartition your data. Spark map() and. Map Partition Spark Java Example.
From read.cholonautas.edu.pe
Spark Dataframe Map Example Scala Printable Templates Free Map Partition Spark Java Example Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. To address this issue, spark provides the mappartitions() function, which allows you. Map Partition Spark Java Example.
From dagster.io
Partitions in Data Pipelines Dagster Blog Map Partition Spark Java Example This will give you insights into whether you need to repartition your data. Tweak them based on your data and cluster size. To address this issue, spark provides the mappartitions() function, which allows you to apply a function to each partition. In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of. Map Partition Spark Java Example.
From morioh.com
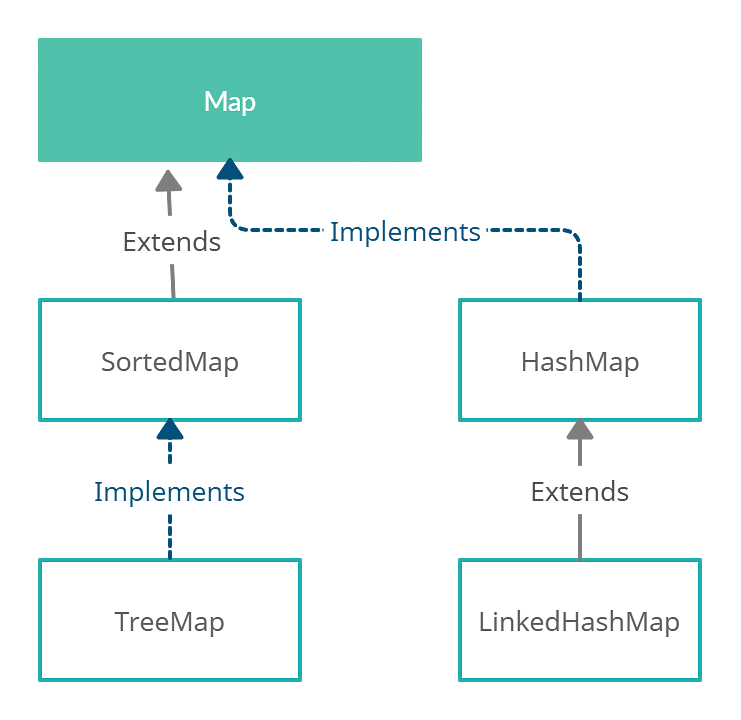
Java Map Interface Example Map Interface in Java Map Partition Spark Java Example For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of an. Map Partition Spark Java Example.
From www.projectpro.io
Explain Spark Lazy evaluation in detail Projectpro Map Partition Spark Java Example The mappartitionsfunction in the apache spark java api is designed for transforming an rdd (resilient distributed. We use spark's ui to monitor task times and shuffle read/write times. Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. Spark map() and mappartitions() transformations apply the function on each element/record/row of. Map Partition Spark Java Example.
From www.vrogue.co
Transform List Using Python Map Spark By Examples vrogue.co Map Partition Spark Java Example Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. This will give you insights into whether you need to repartition your data. Tweak them based on your data and cluster size. For example, we see this scala code using mappartitions written by zero323 on how to add columns into. Map Partition Spark Java Example.
From techvidvan.com
Apache Spark Partitioning and Spark Partition TechVidvan Map Partition Spark Java Example In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of an rdd (resilient. Tweak them based on your data and cluster size. Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and returns the new For example, we see this scala code using mappartitions written by. Map Partition Spark Java Example.
From blogs.vmware.com
How Virtualization Helps in the Data Science and Machine Learning Lab Map Partition Spark Java Example This will give you insights into whether you need to repartition your data. The mappartitionsfunction in the apache spark java api is designed for transforming an rdd (resilient distributed. To address this issue, spark provides the mappartitions() function, which allows you to apply a function to each partition. Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. Spark map() and mappartitions(). Map Partition Spark Java Example.
From zhuanlan.zhihu.com
深入浅出理解 Spark 部署与工作原理 知乎 Map Partition Spark Java Example This will give you insights into whether you need to repartition your data. Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and returns the new For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. The mappartitionsfunction in the apache spark java api is. Map Partition Spark Java Example.
From javarevisited.blogspot.com
Difference between map() and flatMap() in Java 8 Stream Map Partition Spark Java Example The mappartitionsfunction in the apache spark java api is designed for transforming an rdd (resilient distributed. Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. To address this issue, spark provides the mappartitions() function, which allows you to apply a function to each partition. For example, we see this scala code using mappartitions written by zero323 on how to add columns. Map Partition Spark Java Example.
From horicky.blogspot.com
Pragmatic Programming Techniques Big Data Processing in Spark Map Partition Spark Java Example Tweak them based on your data and cluster size. Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of an rdd (resilient. For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. We. Map Partition Spark Java Example.
From jsmithmoore.com
Dataframe map spark java Map Partition Spark Java Example Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. To address this issue, spark provides the mappartitions() function, which allows you to apply a function to each partition. We use spark's ui to monitor task times and shuffle read/write times. Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. The. Map Partition Spark Java Example.
From www.cloudduggu.com
Apache Spark Transformations & Actions Tutorial CloudDuggu Map Partition Spark Java Example For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. We use spark's ui to monitor task times and shuffle read/write times. The mappartitionsfunction in the apache spark java api is designed for transforming an rdd (resilient distributed. This will give you insights into whether you need to repartition your. Map Partition Spark Java Example.
From read.cholonautas.edu.pe
Spark Dataframe Map Example Scala Printable Templates Free Map Partition Spark Java Example We use spark's ui to monitor task times and shuffle read/write times. To address this issue, spark provides the mappartitions() function, which allows you to apply a function to each partition. Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and returns the new This will give you insights into whether you need to repartition. Map Partition Spark Java Example.
From jsmithmoore.com
Dataframe map spark java Map Partition Spark Java Example Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and returns the new In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of an rdd (resilient. Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. We use spark's ui to monitor task times and shuffle read/write times.. Map Partition Spark Java Example.
From manushgupta.github.io
SPARK vs Hadoop MapReduce Manush Gupta Map Partition Spark Java Example Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. The mappartitionsfunction in the apache spark java api is designed for transforming an rdd (resilient distributed. For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. Tweak them based on. Map Partition Spark Java Example.
From sparkbyexamples.com
PySpark RDD Tutorial Learn with Examples Spark by {Examples} Map Partition Spark Java Example For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of an rdd (resilient. Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and returns the new. Map Partition Spark Java Example.
From spideropsnet.com
Beyond MapReduce Igniting the Spark Spider Map Partition Spark Java Example Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. To address this issue, spark provides the mappartitions() function, which allows you to apply a function to each partition. The mappartitionsfunction in the apache spark java api is designed for transforming an. Map Partition Spark Java Example.
From linuxhint.com
How to Sort a Map by Value in Java Map Partition Spark Java Example Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and returns the new Tweak them based on your data and cluster size. To address this issue, spark provides the mappartitions() function, which allows you to apply a function to each partition. This will give you insights into whether you need to repartition your data. For. Map Partition Spark Java Example.
From www.youtube.com
Why should we partition the data in spark? YouTube Map Partition Spark Java Example Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and returns the new For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. The mappartitionsfunction in the apache spark java api is designed for transforming an rdd. Map Partition Spark Java Example.
From dagster.io
Partitions in Data Pipelines Dagster Blog Map Partition Spark Java Example The mappartitionsfunction in the apache spark java api is designed for transforming an rdd (resilient distributed. For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of an rdd (resilient. This will. Map Partition Spark Java Example.
From horicky.blogspot.com
Pragmatic Programming Techniques Spark Low latency, massively Map Partition Spark Java Example To address this issue, spark provides the mappartitions() function, which allows you to apply a function to each partition. In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of an rdd (resilient. For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row. Map Partition Spark Java Example.
From sparkbyexamples.com
Spark map() vs flatMap() with Examples Spark By {Examples} Map Partition Spark Java Example Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and returns the new The mappartitionsfunction in the apache spark java api is designed for transforming an rdd (resilient distributed. This will give you insights into whether you need to repartition your data. To address this issue, spark provides the mappartitions() function, which allows you to. Map Partition Spark Java Example.
From www.tpsearchtool.com
Java Sort Map By Key Ascending And Descending Orders Images Map Partition Spark Java Example Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. Tweak them based on your data and cluster size. We use spark's ui to monitor task times and shuffle read/write times. Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. Spark map() and mappartitions() transformations apply the function on each element/record/row. Map Partition Spark Java Example.
From www.cnblogs.com
[Spark学习] Spark RDD详解 LestatZ 博客园 Map Partition Spark Java Example In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of an rdd (resilient. The mappartitionsfunction in the apache spark java api is designed for transforming an rdd (resilient distributed. This will give you insights into whether you need to repartition your data. To address this issue, spark provides the mappartitions() function,. Map Partition Spark Java Example.
From techvidvan.com
Hadoop Partitioner Learn the Basics of MapReduce Partitioner TechVidvan Map Partition Spark Java Example For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. We use spark's ui to monitor task times and shuffle read/write times. Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. This will give you insights into whether you. Map Partition Spark Java Example.
From blog.csdn.net
hadoop&spark mapreduce对比 & 框架设计和理解_sparkhadoopmapreduceCSDN博客 Map Partition Spark Java Example Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of an rdd (resilient. Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and returns the new. Map Partition Spark Java Example.
From javarevisited.blogspot.com
How to Convert a Map to a List in Java Example Tutorial Map Partition Spark Java Example In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of an rdd (resilient. For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. Map works the function being utilized at a per element level while mappartitions exercises the function at the. Map Partition Spark Java Example.
From jsmithmoore.com
Dataframe map spark java Map Partition Spark Java Example Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. This will give you insights into whether you need to repartition your data. We use spark's ui to monitor task times and shuffle read/write times. Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and. Map Partition Spark Java Example.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Map Partition Spark Java Example The mappartitionsfunction in the apache spark java api is designed for transforming an rdd (resilient distributed. In apache spark, mappartitions is a transformation operation that allows you to apply a function to each partition of an rdd (resilient. To address this issue, spark provides the mappartitions() function, which allows you to apply a function to each partition. Tweak them based. Map Partition Spark Java Example.
From data-flair.training
Hadoop Partitioner Internals of MapReduce Partitioner DataFlair Map Partition Spark Java Example For example, we see this scala code using mappartitions written by zero323 on how to add columns into org.apache.spark.sql.row inside. This will give you insights into whether you need to repartition your data. Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. We use spark's ui to monitor task times and shuffle read/write times. The mappartitionsfunction in the apache spark java. Map Partition Spark Java Example.
From templates.udlvirtual.edu.pe
Pyspark Map Partition Example Printable Templates Map Partition Spark Java Example We use spark's ui to monitor task times and shuffle read/write times. Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and returns the new The mappartitionsfunction in the apache spark java api is designed for transforming an rdd (resilient distributed. This will give you insights into whether you need to repartition your data. In. Map Partition Spark Java Example.
From www.cnblogs.com
Spark:单词计数(Word Count)的MapReduce实现(Java/Python) orionorion 博客园 Map Partition Spark Java Example We use spark's ui to monitor task times and shuffle read/write times. Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. Map works the function being utilized at a per element level while mappartitions exercises the function at the partition level. Spark map() and mappartitions() transformations apply the function on each element/record/row of the dataframe/dataset and returns the new Tweak them. Map Partition Spark Java Example.