Default Shuffle Partitions In Spark . Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. By default, the number of shuffle partitions in spark is set to 200. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. To change this value according to specific workloads and. When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'.
from zhuanlan.zhihu.com
Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. By default, the number of shuffle partitions in spark is set to 200. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. To change this value according to specific workloads and. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data.
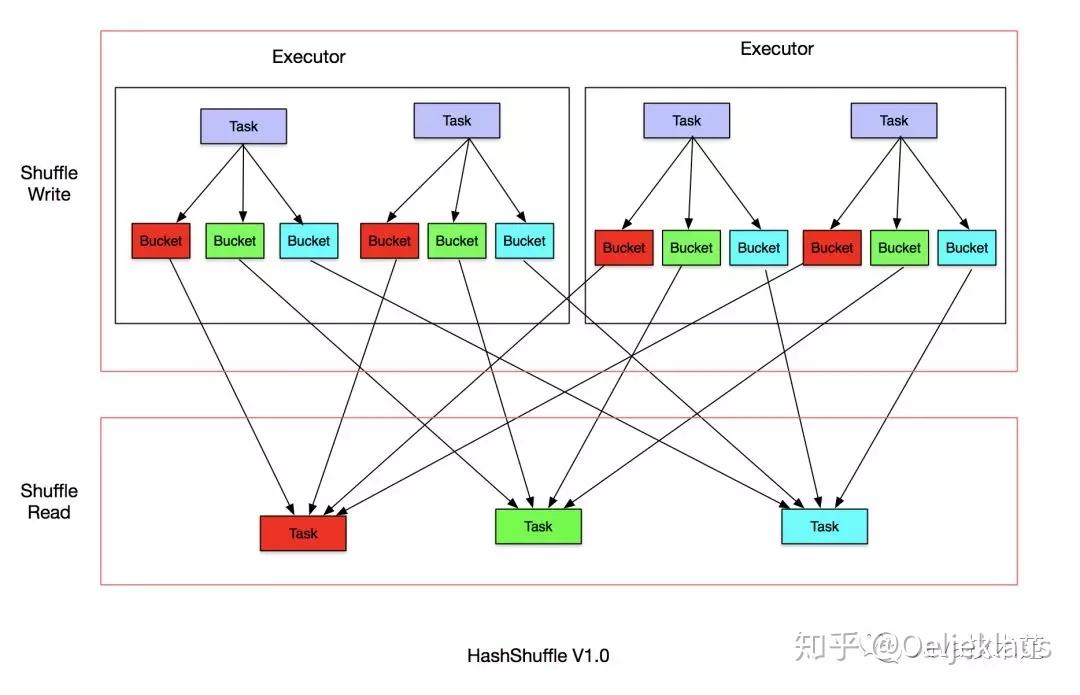
Spark的Shuffle原理(一)HashShuffle 知乎
Default Shuffle Partitions In Spark Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. By default, the number of shuffle partitions in spark is set to 200. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. To change this value according to specific workloads and. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data.
From www.upscpdf.in
spark.sql.shuffle.partitions UPSCPDF Default Shuffle Partitions In Spark By default, the number of shuffle partitions in spark is set to 200. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. To change this value according to specific workloads and. From the. Default Shuffle Partitions In Spark.
From sivaprasad-mandapati.medium.com
Spark Joins Tuning Part2(Shuffle Partitions,AQE) by Sivaprasad Default Shuffle Partitions In Spark Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. To change this value according to specific workloads and. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark. Default Shuffle Partitions In Spark.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Default Shuffle Partitions In Spark Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. When true, spark does not respect the target size specified. Default Shuffle Partitions In Spark.
From blog.csdn.net
浅析 Spark Shuffle 内存使用CSDN博客 Default Shuffle Partitions In Spark To change this value according to specific workloads and. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Spark.sql.shuffle.partitions. Default Shuffle Partitions In Spark.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Default Shuffle Partitions In Spark From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. Spark automatically triggers the shuffle when we perform. Default Shuffle Partitions In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Default Shuffle Partitions In Spark When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. By default, the number of shuffle partitions in spark is set to 200. Spark.sql.shuffle.partitions. Default Shuffle Partitions In Spark.
From exokeufcv.blob.core.windows.net
Max Number Of Partitions In Spark at Manda Salazar blog Default Shuffle Partitions In Spark Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. To change this value according to specific workloads. Default Shuffle Partitions In Spark.
From www.simplilearn.com
Spark Parallelize The Essential Element of Spark Default Shuffle Partitions In Spark Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. To change this value according to specific workloads and. When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. By default, the number of. Default Shuffle Partitions In Spark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Default Shuffle Partitions In Spark Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd. Default Shuffle Partitions In Spark.
From dataengineer1.blogspot.com
What's new in Spark 3.0? Default Shuffle Partitions In Spark Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. From the answer here, spark.sql.shuffle.partitions configures the number. Default Shuffle Partitions In Spark.
From zhuanlan.zhihu.com
Spark的Shuffle原理(一)HashShuffle 知乎 Default Shuffle Partitions In Spark Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. By default, the number of shuffle partitions in spark is set to 200. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. To change this value according to specific workloads and. From the answer here,. Default Shuffle Partitions In Spark.
From blog.csdn.net
对比 Hadoop MapReduce 和 Spark 的 Shuffle 过程_mapreduce和spark的shuffleCSDN博客 Default Shuffle Partitions In Spark To change this value according to specific workloads and. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. When. Default Shuffle Partitions In Spark.
From sparkbyexamples.com
Difference between spark.sql.shuffle.partitions vs spark.default Default Shuffle Partitions In Spark From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. By default, the number of shuffle partitions in spark is set to 200. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. Spark. Default Shuffle Partitions In Spark.
From anhcodes.dev
Spark working internals, and why should you care? Default Shuffle Partitions In Spark When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or. Default Shuffle Partitions In Spark.
From www.youtube.com
Why should we partition the data in spark? YouTube Default Shuffle Partitions In Spark When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. By default, the number of shuffle partitions in spark is set to 200. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. To. Default Shuffle Partitions In Spark.
From www.youtube.com
What is Shuffle How to minimize shuffle in Spark Spark Interview Default Shuffle Partitions In Spark Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. To change this value according to specific workloads and. By. Default Shuffle Partitions In Spark.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Default Shuffle Partitions In Spark By default, the number of shuffle partitions in spark is set to 200. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. Spark.sql.shuffle.partitions. Default Shuffle Partitions In Spark.
From 0x0fff.com
Spark Architecture Shuffle Distributed Systems Architecture Default Shuffle Partitions In Spark Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. To change this value according to specific workloads and. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. Spark automatically triggers the shuffle. Default Shuffle Partitions In Spark.
From www.dezyre.com
How Data Partitioning in Spark helps achieve more parallelism? Default Shuffle Partitions In Spark When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. By default, the number of shuffle partitions in spark is set to 200. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation. Default Shuffle Partitions In Spark.
From www.reddit.com
Are Spark shuffle partitions differed in 3.2 and 3.1 spark version? r Default Shuffle Partitions In Spark By default, the number of shuffle partitions in spark is set to 200. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. To change this value according to specific workloads and. Spark.sql.shuffle.partitions determines the number. Default Shuffle Partitions In Spark.
From timepasstechies.com
mapreduce shuffle and sort phase Big Data Default Shuffle Partitions In Spark When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. By default, the number of shuffle partitions in spark is set to 200. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. Spark.sql.shuffle.partitions. Default Shuffle Partitions In Spark.
From exocpydfk.blob.core.windows.net
What Is Shuffle Partitions In Spark at Joe Warren blog Default Shuffle Partitions In Spark From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. To change this value according to specific workloads and. By default, the number of shuffle partitions in spark is set to 200. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. Spark automatically triggers the. Default Shuffle Partitions In Spark.
From lionheartwang.github.io
Spark Shuffle工作原理详解 Workspace of LionHeart Default Shuffle Partitions In Spark From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. To change this value according to specific workloads and. By default, the number of shuffle partitions in spark is set to 200. Spark automatically triggers the shuffle when we perform aggregation and. Default Shuffle Partitions In Spark.
From blog.csdn.net
spark基本知识点之Shuffle_separate file for each media typeCSDN博客 Default Shuffle Partitions In Spark Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. By default, the number of shuffle partitions in spark is set to 200. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. To change this value according to specific workloads and. Spark.sql.shuffle.partitions determines the number. Default Shuffle Partitions In Spark.
From gyuhoonk.github.io
Partition, Spill in Spark Default Shuffle Partitions In Spark From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. When true, spark does not respect the target. Default Shuffle Partitions In Spark.
From kyuubi.readthedocs.io
How To Use Spark Adaptive Query Execution (AQE) in Kyuubi — Apache Kyuubi Default Shuffle Partitions In Spark Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. To change this value according to specific workloads and. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling. Default Shuffle Partitions In Spark.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Default Shuffle Partitions In Spark By default, the number of shuffle partitions in spark is set to 200. To change this value according to specific workloads and. When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions. Default Shuffle Partitions In Spark.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders Default Shuffle Partitions In Spark Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. By default, the number of shuffle partitions in spark is set to 200. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins. Default Shuffle Partitions In Spark.
From medium.com
Understanding Apache Spark Shuffle by Philipp Brunenberg Medium Default Shuffle Partitions In Spark Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. By default, the number of shuffle partitions in spark is set to 200. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used. Default Shuffle Partitions In Spark.
From etheleon.github.io
Not so big queries, hitchhiker’s guide to datawarehousing with Default Shuffle Partitions In Spark From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions. Default Shuffle Partitions In Spark.
From blog.csdn.net
PySpark基础入门(6):Spark Shuffle_pyspark shuffle writeCSDN博客 Default Shuffle Partitions In Spark By default, the number of shuffle partitions in spark is set to 200. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. To change this. Default Shuffle Partitions In Spark.
From docs.aws.amazon.com
存储 Spark 随机排序数据 AWS 连接词 Default Shuffle Partitions In Spark Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins or aggregation i.e. When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are. Default Shuffle Partitions In Spark.
From exocpydfk.blob.core.windows.net
What Is Shuffle Partitions In Spark at Joe Warren blog Default Shuffle Partitions In Spark Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. By default, the number of shuffle partitions in spark is set to 200. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. Spark.sql.shuffle.partitions is the parameter which decides the number of partitions while doing shuffles like joins. Default Shuffle Partitions In Spark.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Default Shuffle Partitions In Spark To change this value according to specific workloads and. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Spark.sql.shuffle.partitions determines the number of partitions to use when shuffling data for joins or aggregations in spark sql. From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. When. Default Shuffle Partitions In Spark.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient Default Shuffle Partitions In Spark From the answer here, spark.sql.shuffle.partitions configures the number of partitions that are used when shuffling data. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. When true, spark does not respect the target size specified by 'spark.sql.adaptive.advisorypartitionsizeinbytes'. By default, the number of shuffle partitions in spark is set to 200. Spark.sql.shuffle.partitions determines the. Default Shuffle Partitions In Spark.