Glue Dynamodb Sink . The following sections walk you through building a streaming etl job in aws glue. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). You connect to dynamodb using iam permissions. You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. Before you create an aws glue etl job to read from or write to a dynamodb table, consider the following configuration updates. You can also write to arbitrary sinks using native apache spark structured streaming apis. With glue use dynamodb export feature, no data pull from dynamodb to glue and write to s3. In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api.
from noise.getoto.net
You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. Before you create an aws glue etl job to read from or write to a dynamodb table, consider the following configuration updates. You connect to dynamodb using iam permissions. In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. You can also write to arbitrary sinks using native apache spark structured streaming apis. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). With glue use dynamodb export feature, no data pull from dynamodb to glue and write to s3. The following sections walk you through building a streaming etl job in aws glue.
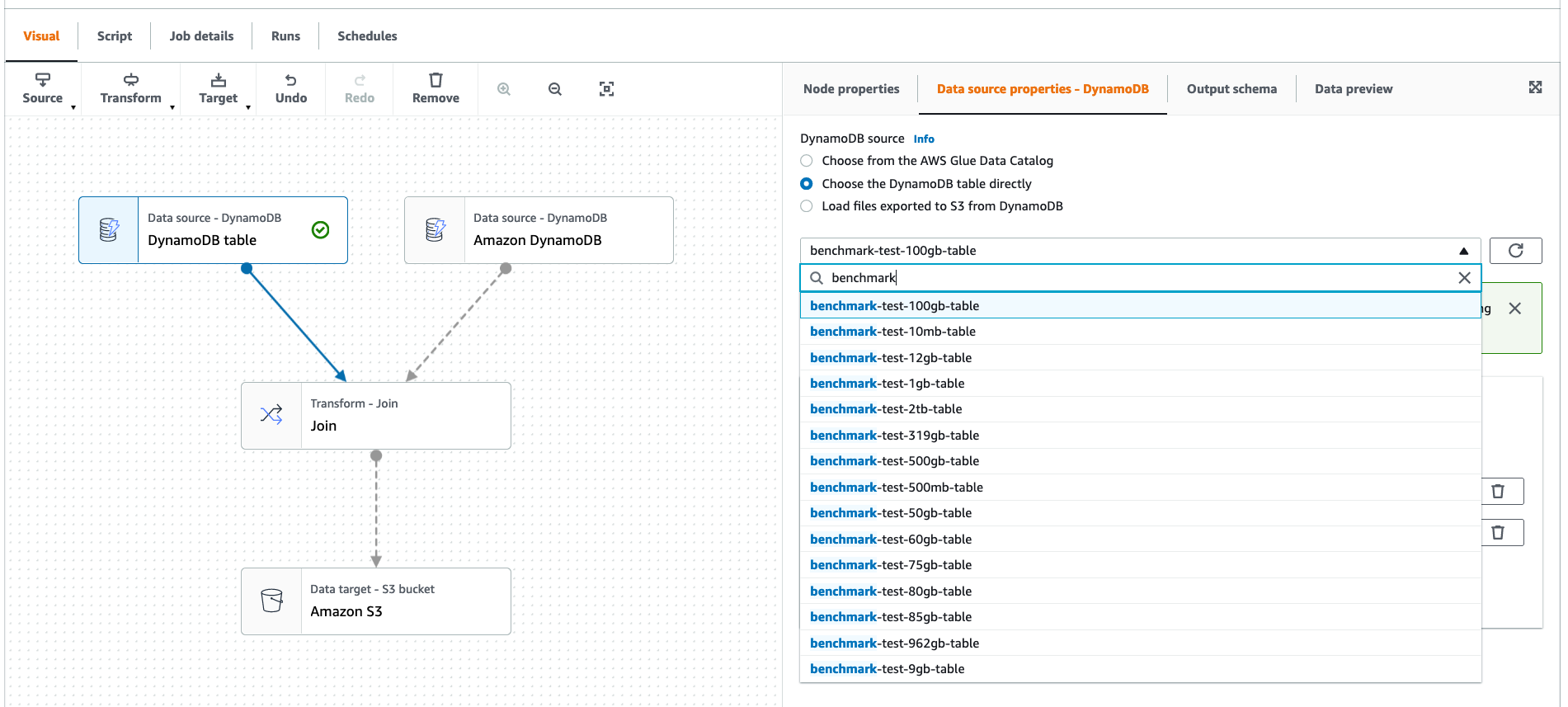
Accelerate Amazon DynamoDB data access in AWS Glue jobs using the new
Glue Dynamodb Sink You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). With glue use dynamodb export feature, no data pull from dynamodb to glue and write to s3. Before you create an aws glue etl job to read from or write to a dynamodb table, consider the following configuration updates. You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. You can also write to arbitrary sinks using native apache spark structured streaming apis. You connect to dynamodb using iam permissions. The following sections walk you through building a streaming etl job in aws glue. You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter.
From cevo.com.au
Kafka Connect for AWS Services Integration Part 3 Deploy Camel Glue Dynamodb Sink Before you create an aws glue etl job to read from or write to a dynamodb table, consider the following configuration updates. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). The following sections walk you through building a streaming etl job in aws glue. You connect to dynamodb using iam permissions. You can use aws glue for spark to read. Glue Dynamodb Sink.
From cevo.com.au
Kafka Connect for AWS Services Integration Part 3 Deploy Camel Glue Dynamodb Sink >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. Before you create an aws glue etl job to read from or write. Glue Dynamodb Sink.
From www.youtube.com
Add DynamoDB Data Source in AWS Glue YouTube Glue Dynamodb Sink The following sections walk you through building a streaming etl job in aws glue. In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. You connect to dynamodb using iam permissions.. Glue Dynamodb Sink.
From jaehyeon.me
Kafka Connect for AWS Services Integration Part 2 Develop Camel Glue Dynamodb Sink You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). You connect to dynamodb using iam permissions. You can also write to arbitrary sinks using. Glue Dynamodb Sink.
From dev.classmethod.jp
Glue Studio で DynamoDB JSON を CSV に変換するジョブを作成してみる DevelopersIO Glue Dynamodb Sink You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. With glue use dynamodb export feature, no data pull from dynamodb to glue and write to s3. In aws glue for spark, various. Glue Dynamodb Sink.
From exomvzzvq.blob.core.windows.net
Waterproof Glue For Kitchen Sink at Ola Delreal blog Glue Dynamodb Sink You can also write to arbitrary sinks using native apache spark structured streaming apis. You connect to dynamodb using iam permissions. You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. The following sections walk you through building a streaming etl job in aws glue. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>>. Glue Dynamodb Sink.
From www.youtube.com
Simplify Amazon DynamoDB data extraction and analysis by using AWS Glue Glue Dynamodb Sink You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. With glue use dynamodb export feature, no data pull from dynamodb to glue and write to s3. Before you create an aws glue etl job to read from or write to a dynamodb table, consider the following configuration updates. In aws. Glue Dynamodb Sink.
From yomon.hatenablog.com
AWS GlueでDynamoDBがサポートされたので触ってみた Glue Dynamodb Sink You connect to dynamodb using iam permissions. With glue use dynamodb export feature, no data pull from dynamodb to glue and write to s3. You can also write to arbitrary sinks using native apache spark structured streaming apis. In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. Before you. Glue Dynamodb Sink.
From dev.classmethod.jp
DynamoDB から S3 への定期的なエクスポートの仕組みを AWS Glue と Step Functions を使用して実装してみた Glue Dynamodb Sink In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. You can also write to arbitrary sinks using native apache spark structured streaming apis. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). You can use aws glue for spark to read from and write to tables in dynamodb in aws. Glue Dynamodb Sink.
From hevodata.com
Connecting DynamoDB to S3 Using AWS Glue 2 Easy Steps Glue Dynamodb Sink >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. Before you create an aws glue etl job to read from or write to a dynamodb table, consider the following configuration updates. You can use aws glue for spark to read from and write. Glue Dynamodb Sink.
From www.youtube.com
AWS Glue Overview and Integration with DynamoDB YouTube Glue Dynamodb Sink The following sections walk you through building a streaming etl job in aws glue. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. You connect to dynamodb using iam permissions. You can use aws glue for spark to read from and write to. Glue Dynamodb Sink.
From hevodata.com
DynamoDB to S3 Using AWS Glue Steps to Export Data Hevo Glue Dynamodb Sink With glue use dynamodb export feature, no data pull from dynamodb to glue and write to s3. The following sections walk you through building a streaming etl job in aws glue. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. You can. Glue Dynamodb Sink.
From aws.amazon.com
Join a streaming data source with CDC data for realtime serverless Glue Dynamodb Sink You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). With glue use dynamodb export feature, no data pull from dynamodb to glue and write to s3. In aws glue for spark, various pyspark and scala methods and transforms specify the connection type. Glue Dynamodb Sink.
From blog.csdn.net
使用新的 Amazon Glue DynamoDB Export 加速 Amazon DynamoDB 数据访问评论源CSDN博客 Glue Dynamodb Sink Before you create an aws glue etl job to read from or write to a dynamodb table, consider the following configuration updates. You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. You can also write to arbitrary sinks using native apache spark structured streaming apis. In aws glue for spark, various. Glue Dynamodb Sink.
From aws.amazon.com
Accelerate Amazon DynamoDB data access in AWS Glue jobs using the new Glue Dynamodb Sink The following sections walk you through building a streaming etl job in aws glue. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. You can also write to arbitrary sinks using native apache spark structured streaming apis. You connect to dynamodb. Glue Dynamodb Sink.
From github.com
GitHub ramitsurana/dynamodbglueathena Info on Glue (ETL), Athena Glue Dynamodb Sink The following sections walk you through building a streaming etl job in aws glue. You can also write to arbitrary sinks using native apache spark structured streaming apis. You connect to dynamodb using iam permissions. You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>>. Glue Dynamodb Sink.
From jjeanjacques10.medium.com
Atualizando dados no DynamoDB utilizando AWS Glue by Jean Jacques Glue Dynamodb Sink Before you create an aws glue etl job to read from or write to a dynamodb table, consider the following configuration updates. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). You connect to dynamodb using iam permissions. In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. You can read. Glue Dynamodb Sink.
From github.com
GitHub UlkeshPatil/apilambdagluedynamodb Glue Dynamodb Sink In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. You can also write to arbitrary sinks using native apache spark structured streaming apis. You connect to dynamodb using iam permissions. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). You can use aws glue for spark to read from and. Glue Dynamodb Sink.
From www.youtube.com
Step by Step guide How to Move data from DynamoDB to Aurora Postgres Glue Dynamodb Sink >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). You connect to dynamodb using iam permissions. The following sections walk you through building a streaming etl job in aws glue. With glue use dynamodb export feature, no data pull from dynamodb to glue and write to s3. You can read from the data stream and write to amazon s3 using the. Glue Dynamodb Sink.
From rockset.com
DynamoDB Analytics Elasticsearch, Athena & Spark Rockset Glue Dynamodb Sink >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. You can also write to arbitrary sinks using native apache spark structured streaming apis. You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. With. Glue Dynamodb Sink.
From cloudacademy.com
Amazon RDS vs DynamoDB 12 Differences You Should Know Glue Dynamodb Sink You can also write to arbitrary sinks using native apache spark structured streaming apis. The following sections walk you through building a streaming etl job in aws glue. You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. You can read from the data stream and write to amazon s3 using. Glue Dynamodb Sink.
From cevo.com.au
Kafka Connect for AWS Services Integration Part 3 Deploy Camel Glue Dynamodb Sink In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. The following sections walk you through building a streaming etl job in aws glue. You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>>. Glue Dynamodb Sink.
From blog.csdn.net
使用新的 Amazon Glue DynamoDB Export 加速 Amazon DynamoDB 数据访问评论源CSDN博客 Glue Dynamodb Sink In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. With glue use dynamodb export feature, no data pull from dynamodb to glue and write to s3. Before you create an aws. Glue Dynamodb Sink.
From jaehyeon.me
Kafka Connect for AWS Services Integration Part 2 Develop Camel Glue Dynamodb Sink You can also write to arbitrary sinks using native apache spark structured streaming apis. The following sections walk you through building a streaming etl job in aws glue. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). You connect to dynamodb using iam permissions. You can read from the data stream and write to amazon s3 using the aws glue dynamicframe. Glue Dynamodb Sink.
From developers.cyberagent.co.jp
AWSのDynamoDB, S3, Glueを組み合わせて実現したコスト最適化 CyberAgent Developers Blog Glue Dynamodb Sink In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. You can also write to arbitrary sinks using native apache spark structured streaming apis. You connect to dynamodb using iam permissions. Before you create an aws glue etl job to read from or write to a dynamodb table, consider the. Glue Dynamodb Sink.
From www.studypool.com
SOLUTION Dynamodb quick guide Studypool Glue Dynamodb Sink You connect to dynamodb using iam permissions. The following sections walk you through building a streaming etl job in aws glue. With glue use dynamodb export feature, no data pull from dynamodb to glue and write to s3. In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. >>> data_sink. Glue Dynamodb Sink.
From noise.getoto.net
Accelerate Amazon DynamoDB data access in AWS Glue jobs using the new Glue Dynamodb Sink You can also write to arbitrary sinks using native apache spark structured streaming apis. The following sections walk you through building a streaming etl job in aws glue. You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. With glue use dynamodb export feature, no data pull from dynamodb to glue and. Glue Dynamodb Sink.
From dev.classmethod.jp
Glue Studio で DynamoDB JSON を CSV に変換するジョブを作成してみる DevelopersIO Glue Dynamodb Sink In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. You connect to dynamodb using iam permissions. You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. You can use aws glue for spark to read from and write to tables in. Glue Dynamodb Sink.
From cevo.com.au
Kafka Connect for AWS Services Integration Part 3 Deploy Camel Glue Dynamodb Sink You connect to dynamodb using iam permissions. With glue use dynamodb export feature, no data pull from dynamodb to glue and write to s3. You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a. Glue Dynamodb Sink.
From blog.searce.com
Streamlined AWS Ops Automating Lambda, Glue, DynamoDB Security by Glue Dynamodb Sink Before you create an aws glue etl job to read from or write to a dynamodb table, consider the following configuration updates. You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. You can read from the data stream and write to amazon s3 using the aws glue dynamicframe api. In. Glue Dynamodb Sink.
From www.bitcoininsider.org
Building Serverless Data Lake with AWS Glue DynamoDB and Athena Glue Dynamodb Sink >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). You connect to dynamodb using iam permissions. You can also write to arbitrary sinks using native apache spark structured streaming apis. With glue use dynamodb export feature, no data pull from dynamodb to glue and write to s3. In aws glue for spark, various pyspark and scala methods and transforms specify the. Glue Dynamodb Sink.
From aws.amazon.com
Implement vertical partitioning in Amazon DynamoDB using AWS Glue AWS Glue Dynamodb Sink Before you create an aws glue etl job to read from or write to a dynamodb table, consider the following configuration updates. >>> data_sink = context.getsink(s3) >>> data_sink.setformat(json), >>> data_sink.writeframe(myframe). The following sections walk you through building a streaming etl job in aws glue. You can read from the data stream and write to amazon s3 using the aws glue. Glue Dynamodb Sink.
From www.linkedin.com
DynamoDB to S3 using AWS Glue A Comprehensive Guide Glue Dynamodb Sink You can also write to arbitrary sinks using native apache spark structured streaming apis. In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. Before you create an aws glue etl job to read from or write to a dynamodb table, consider the following configuration updates. You can use aws. Glue Dynamodb Sink.
From www.rahulpnath.com
How to Ensure Data Consistency with DynamoDB Condition Expressions From Glue Dynamodb Sink In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. You can use aws glue for spark to read from and write to tables in dynamodb in aws glue. You connect to dynamodb using iam permissions. You can also write to arbitrary sinks using native apache spark structured streaming apis.. Glue Dynamodb Sink.
From yomon.hatenablog.com
AWS GlueでDynamoDBがサポートされたので触ってみた Glue Dynamodb Sink With glue use dynamodb export feature, no data pull from dynamodb to glue and write to s3. In aws glue for spark, various pyspark and scala methods and transforms specify the connection type using a connectiontype parameter. The following sections walk you through building a streaming etl job in aws glue. You can use aws glue for spark to read. Glue Dynamodb Sink.