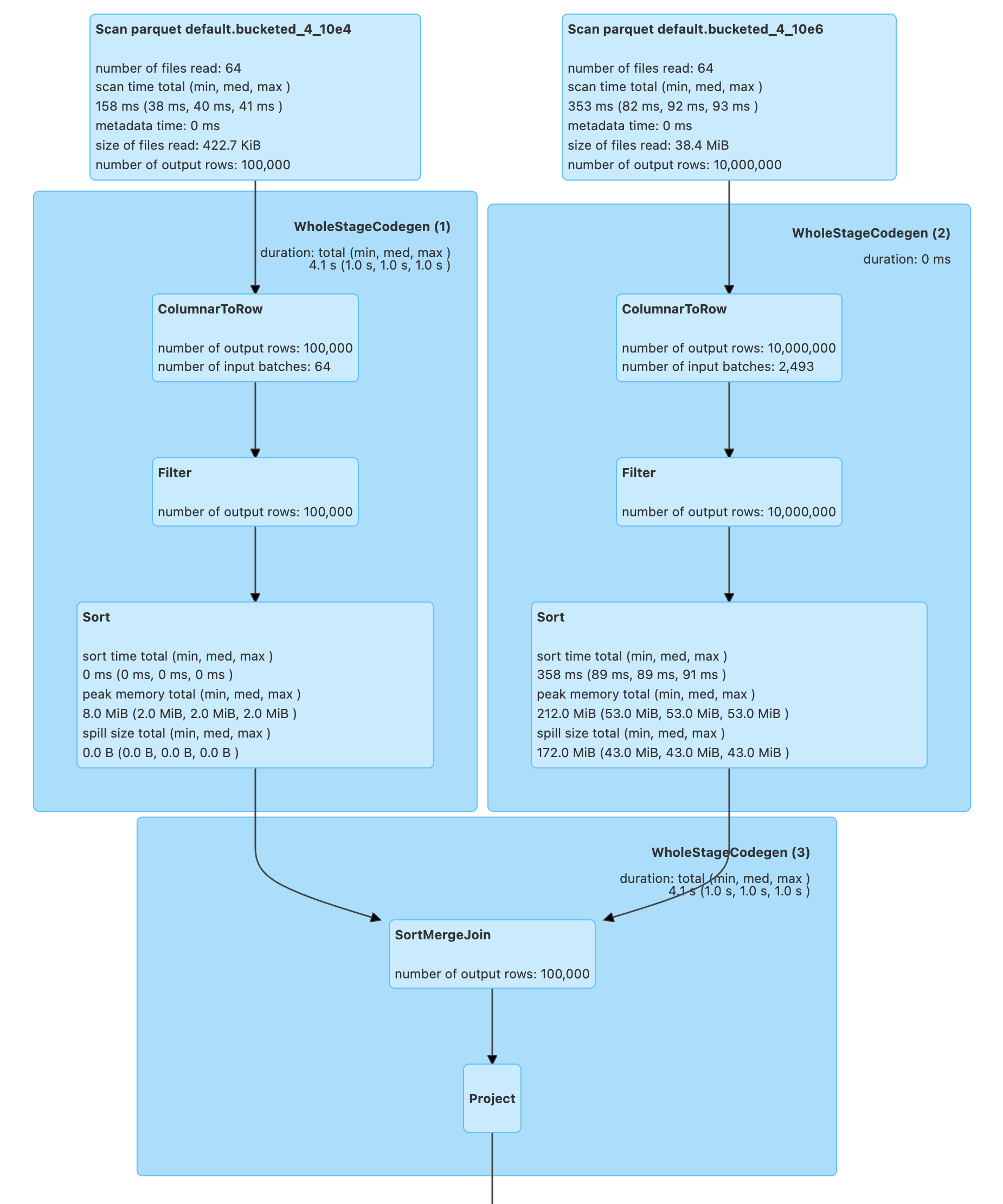
Bucketing Is Not Supported For Delta Tables . this article provides an overview of how you can partition tables on azure databricks and specific. if you are using delta lake and you have enabled bucket versioning on the s3 bucket, you have two entities managing table. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. We are trying to optimize the jobs but couldn't use. to improve the performance of queries, convert to delta and run the optimize command on the table. we are migrating a job from onprem to databricks. hi @rahul samant , we checked internally on this due to certain limitations bucketing is not supported on. readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes.
from books.japila.pl
if you are using delta lake and you have enabled bucket versioning on the s3 bucket, you have two entities managing table. this article provides an overview of how you can partition tables on azure databricks and specific. We are trying to optimize the jobs but couldn't use. to improve the performance of queries, convert to delta and run the optimize command on the table. readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes. we are migrating a job from onprem to databricks. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. hi @rahul samant , we checked internally on this due to certain limitations bucketing is not supported on.
Bucketing The Internals of Spark SQL
Bucketing Is Not Supported For Delta Tables if you are using delta lake and you have enabled bucket versioning on the s3 bucket, you have two entities managing table. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes. if you are using delta lake and you have enabled bucket versioning on the s3 bucket, you have two entities managing table. We are trying to optimize the jobs but couldn't use. to improve the performance of queries, convert to delta and run the optimize command on the table. this article provides an overview of how you can partition tables on azure databricks and specific. we are migrating a job from onprem to databricks. hi @rahul samant , we checked internally on this due to certain limitations bucketing is not supported on.
From stackoverflow.com
Table bucketing is not leveraged in a join spark Glue Stack Overflow Bucketing Is Not Supported For Delta Tables We are trying to optimize the jobs but couldn't use. this article provides an overview of how you can partition tables on azure databricks and specific. if you are using delta lake and you have enabled bucket versioning on the s3 bucket, you have two entities managing table. we are migrating a job from onprem to databricks.. Bucketing Is Not Supported For Delta Tables.
From learn.microsoft.com
Lakehouse Load to Delta Lake tables Microsoft Fabric Microsoft Learn Bucketing Is Not Supported For Delta Tables readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes. to improve the performance of queries, convert to delta and run the optimize command on the table. this article provides an overview of how you can partition tables on azure databricks and specific. if you are using delta lake. Bucketing Is Not Supported For Delta Tables.
From delta.io
How to Create Delta Lake tables Delta Lake Bucketing Is Not Supported For Delta Tables if you are using delta lake and you have enabled bucket versioning on the s3 bucket, you have two entities managing table. to improve the performance of queries, convert to delta and run the optimize command on the table. this article provides an overview of how you can partition tables on azure databricks and specific. hi. Bucketing Is Not Supported For Delta Tables.
From www.mssqltips.com
Delta Live Tables Databricks Framework a Data Transformation Tool Bucketing Is Not Supported For Delta Tables We are trying to optimize the jobs but couldn't use. readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. hi @rahul samant , we checked internally on this due to certain limitations bucketing is not. Bucketing Is Not Supported For Delta Tables.
From www.boltic.io
Databricks Delta Tables Key Features, Functional Bucketing Is Not Supported For Delta Tables to improve the performance of queries, convert to delta and run the optimize command on the table. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. if you are using delta lake and you have enabled bucket versioning on the s3 bucket, you have two entities managing table. hi @rahul samant. Bucketing Is Not Supported For Delta Tables.
From www.plcmart.com
[중고] ACC28E DELTA TAU HighResolution AD 컨버터 (1665480341) PLC전문 Bucketing Is Not Supported For Delta Tables We are trying to optimize the jobs but couldn't use. to improve the performance of queries, convert to delta and run the optimize command on the table. we are migrating a job from onprem to databricks. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. this article provides an overview of. Bucketing Is Not Supported For Delta Tables.
From blank.udlvirtual.edu.pe
What Is Delta Tables In Azure Databricks Blank Printable Bucketing Is Not Supported For Delta Tables bucketing improves performance by shuffling and sorting data prior to downstream operations such as. readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes. to improve the performance of queries, convert to delta and run the optimize command on the table. we are migrating a job from onprem to. Bucketing Is Not Supported For Delta Tables.
From www.pinterest.cl
Thomas Birthday Parties, Ninja Turtles Birthday Party, Trains Birthday Bucketing Is Not Supported For Delta Tables we are migrating a job from onprem to databricks. this article provides an overview of how you can partition tables on azure databricks and specific. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. if you are using delta lake and you have enabled bucket versioning on the s3 bucket, you. Bucketing Is Not Supported For Delta Tables.
From www.solcomp.com
Uso de Delta Lake y Delta Tables en Microsoft Fabric Bucketing Is Not Supported For Delta Tables bucketing improves performance by shuffling and sorting data prior to downstream operations such as. hi @rahul samant , we checked internally on this due to certain limitations bucketing is not supported on. we are migrating a job from onprem to databricks. this article provides an overview of how you can partition tables on azure databricks and. Bucketing Is Not Supported For Delta Tables.
From www.delta.com.qa
Home page Bucketing Is Not Supported For Delta Tables this article provides an overview of how you can partition tables on azure databricks and specific. We are trying to optimize the jobs but couldn't use. to improve the performance of queries, convert to delta and run the optimize command on the table. if you are using delta lake and you have enabled bucket versioning on the. Bucketing Is Not Supported For Delta Tables.
From anhcodes.dev
Deep Dive Into Delta Lake Bucketing Is Not Supported For Delta Tables readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. this article provides an overview of how you can partition tables on azure databricks and specific. hi @rahul samant , we checked internally on this. Bucketing Is Not Supported For Delta Tables.
From sparkbyexamples.com
Time Travel with Delta Tables in Databricks? Spark By {Examples} Bucketing Is Not Supported For Delta Tables bucketing improves performance by shuffling and sorting data prior to downstream operations such as. we are migrating a job from onprem to databricks. hi @rahul samant , we checked internally on this due to certain limitations bucketing is not supported on. readers of delta tables use snapshot isolation, which means that they are not interrupted when. Bucketing Is Not Supported For Delta Tables.
From books.japila.pl
Bucketing The Internals of Spark SQL Bucketing Is Not Supported For Delta Tables We are trying to optimize the jobs but couldn't use. to improve the performance of queries, convert to delta and run the optimize command on the table. if you are using delta lake and you have enabled bucket versioning on the s3 bucket, you have two entities managing table. we are migrating a job from onprem to. Bucketing Is Not Supported For Delta Tables.
From medium.com
Sync Delta Tables Stored in DBFS (Managed or External) To Unity Catalog Bucketing Is Not Supported For Delta Tables bucketing improves performance by shuffling and sorting data prior to downstream operations such as. this article provides an overview of how you can partition tables on azure databricks and specific. hi @rahul samant , we checked internally on this due to certain limitations bucketing is not supported on. if you are using delta lake and you. Bucketing Is Not Supported For Delta Tables.
From dokumen.tips
(PDF) Using Apache Hive · Transactional tables in Hive 3 are on a par Bucketing Is Not Supported For Delta Tables readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes. we are migrating a job from onprem to databricks. this article provides an overview of how you can partition tables on azure databricks and specific. We are trying to optimize the jobs but couldn't use. bucketing improves performance by. Bucketing Is Not Supported For Delta Tables.
From books.japila.pl
Bucketing The Internals of Spark SQL Bucketing Is Not Supported For Delta Tables we are migrating a job from onprem to databricks. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. hi @rahul samant , we checked internally on this due to certain limitations bucketing is not supported on. to improve the performance of queries, convert to delta and run the optimize command on. Bucketing Is Not Supported For Delta Tables.
From newsletter.pragmaticengineer.com
Performance Calibrations at Tech Companies Part 1 Bucketing Is Not Supported For Delta Tables readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes. we are migrating a job from onprem to databricks. We are trying to optimize the jobs but couldn't use. this article provides an overview of how you can partition tables on azure databricks and specific. if you are using. Bucketing Is Not Supported For Delta Tables.
From fabric.guru
How to check If Delta Table in Fabric is VORDER Optimized DirectLake Bucketing Is Not Supported For Delta Tables hi @rahul samant , we checked internally on this due to certain limitations bucketing is not supported on. if you are using delta lake and you have enabled bucket versioning on the s3 bucket, you have two entities managing table. readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes.. Bucketing Is Not Supported For Delta Tables.
From www.borealisai.com
How to use Great Expectations to Validate Delta Tables Borealis AI Bucketing Is Not Supported For Delta Tables this article provides an overview of how you can partition tables on azure databricks and specific. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. We are trying to optimize the jobs but couldn't use. readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes.. Bucketing Is Not Supported For Delta Tables.
From www.youtube.com
Ask an Expert Introduction to Delta Live Tables YouTube Bucketing Is Not Supported For Delta Tables to improve the performance of queries, convert to delta and run the optimize command on the table. this article provides an overview of how you can partition tables on azure databricks and specific. we are migrating a job from onprem to databricks. We are trying to optimize the jobs but couldn't use. bucketing improves performance by. Bucketing Is Not Supported For Delta Tables.
From medium.com
Delta tables with Dataproc, Jupyter (and BigQuery) by Neil Kolban Bucketing Is Not Supported For Delta Tables We are trying to optimize the jobs but couldn't use. readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes. hi @rahul samant , we checked internally on this due to certain limitations bucketing is not supported on. to improve the performance of queries, convert to delta and run the. Bucketing Is Not Supported For Delta Tables.
From www.pinterest.com
Happy Founders Day, Delta Sigma Theta Gifts, Professional Headshots Bucketing Is Not Supported For Delta Tables We are trying to optimize the jobs but couldn't use. hi @rahul samant , we checked internally on this due to certain limitations bucketing is not supported on. this article provides an overview of how you can partition tables on azure databricks and specific. if you are using delta lake and you have enabled bucket versioning on. Bucketing Is Not Supported For Delta Tables.
From delta.io
Reading Delta Lake Tables into Polars DataFrames Delta Lake Bucketing Is Not Supported For Delta Tables hi @rahul samant , we checked internally on this due to certain limitations bucketing is not supported on. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. to improve the performance of queries, convert to delta and run the optimize command on the table. if you are using delta lake and. Bucketing Is Not Supported For Delta Tables.
From learn.microsoft.com
Caps are not preserved when Creating delta tables in Azure Synapse Bucketing Is Not Supported For Delta Tables to improve the performance of queries, convert to delta and run the optimize command on the table. if you are using delta lake and you have enabled bucket versioning on the s3 bucket, you have two entities managing table. We are trying to optimize the jobs but couldn't use. we are migrating a job from onprem to. Bucketing Is Not Supported For Delta Tables.
From www.youtube.com
Delta Tables with Data Flows YouTube Bucketing Is Not Supported For Delta Tables we are migrating a job from onprem to databricks. readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. We are trying to optimize the jobs but couldn't use. hi @rahul samant , we checked. Bucketing Is Not Supported For Delta Tables.
From www.povison.com
Modern White Round Dining Table with X Carbon Base Free Shipping Bucketing Is Not Supported For Delta Tables this article provides an overview of how you can partition tables on azure databricks and specific. We are trying to optimize the jobs but couldn't use. readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes. if you are using delta lake and you have enabled bucket versioning on the. Bucketing Is Not Supported For Delta Tables.
From help.noibu.com
Session Bucketing Intervals Noibu Knowledge Base Bucketing Is Not Supported For Delta Tables hi @rahul samant , we checked internally on this due to certain limitations bucketing is not supported on. to improve the performance of queries, convert to delta and run the optimize command on the table. readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes. We are trying to optimize. Bucketing Is Not Supported For Delta Tables.
From vapefuse.com
Dispensary Grade Delta 9 THC Gummies VapeFuse Bucketing Is Not Supported For Delta Tables We are trying to optimize the jobs but couldn't use. to improve the performance of queries, convert to delta and run the optimize command on the table. this article provides an overview of how you can partition tables on azure databricks and specific. readers of delta tables use snapshot isolation, which means that they are not interrupted. Bucketing Is Not Supported For Delta Tables.
From www.stylepark.com
Delta occasional table by Established & Sons STYLEPARK Bucketing Is Not Supported For Delta Tables we are migrating a job from onprem to databricks. readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes. this article provides an overview of how you can partition tables on azure databricks and specific. hi @rahul samant , we checked internally on this due to certain limitations bucketing. Bucketing Is Not Supported For Delta Tables.
From www.povison.com
Round Pedestal Dining Table with Lazy Susan Bucketing Is Not Supported For Delta Tables readers of delta tables use snapshot isolation, which means that they are not interrupted when optimize removes. this article provides an overview of how you can partition tables on azure databricks and specific. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. to improve the performance of queries, convert to delta. Bucketing Is Not Supported For Delta Tables.
From www.vrogue.co
Delta Lake With Azure Databricks vrogue.co Bucketing Is Not Supported For Delta Tables to improve the performance of queries, convert to delta and run the optimize command on the table. if you are using delta lake and you have enabled bucket versioning on the s3 bucket, you have two entities managing table. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. this article provides. Bucketing Is Not Supported For Delta Tables.
From www.craiyon.com
Stylish logo for delta functional center on Craiyon Bucketing Is Not Supported For Delta Tables this article provides an overview of how you can partition tables on azure databricks and specific. we are migrating a job from onprem to databricks. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. hi @rahul samant , we checked internally on this due to certain limitations bucketing is not supported. Bucketing Is Not Supported For Delta Tables.
From www.cnbc.com
Delta, Southwest, Spirit 10 highestranking domestic airlines Bucketing Is Not Supported For Delta Tables to improve the performance of queries, convert to delta and run the optimize command on the table. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. this article provides an overview of how you can partition tables on azure databricks and specific. readers of delta tables use snapshot isolation, which means. Bucketing Is Not Supported For Delta Tables.
From www.youtube.com
Azure Databricks Tutorial 17Time travel and Versioning in Bucketing Is Not Supported For Delta Tables hi @rahul samant , we checked internally on this due to certain limitations bucketing is not supported on. to improve the performance of queries, convert to delta and run the optimize command on the table. bucketing improves performance by shuffling and sorting data prior to downstream operations such as. We are trying to optimize the jobs but. Bucketing Is Not Supported For Delta Tables.
From delta.io
Delta Lake Time Travel Delta Lake Bucketing Is Not Supported For Delta Tables bucketing improves performance by shuffling and sorting data prior to downstream operations such as. if you are using delta lake and you have enabled bucket versioning on the s3 bucket, you have two entities managing table. this article provides an overview of how you can partition tables on azure databricks and specific. We are trying to optimize. Bucketing Is Not Supported For Delta Tables.