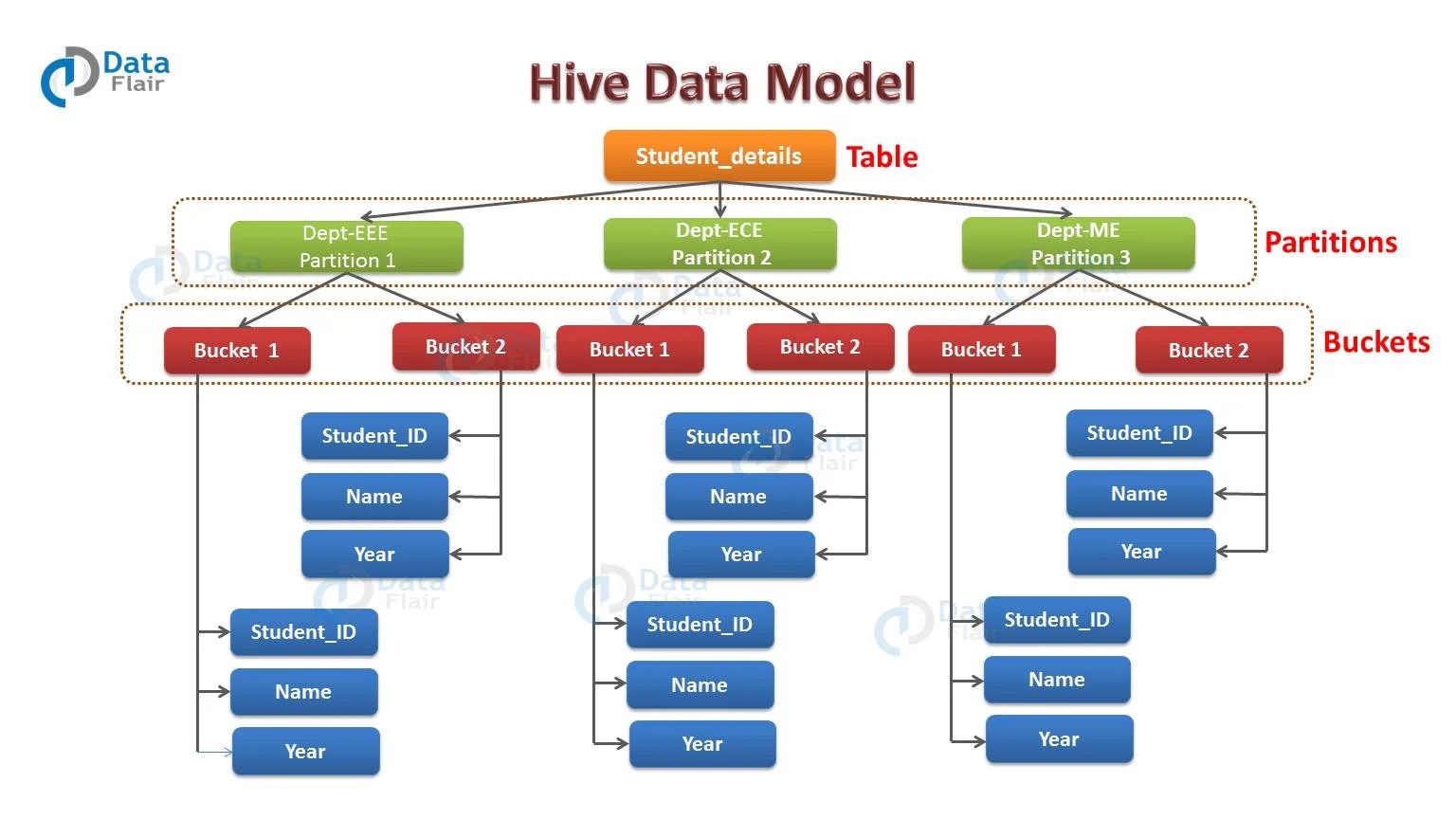
Why Bucketing Is Faster Than Partitioning . Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results for the search queries. For example, suppose a table using date. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing columns is not a. Bucketing is another technique for decomposing data sets into more manageable parts. Partitioning enhances query performance by allowing the database system to operate on. In the world of data and analytics, storing and processing vast amounts of data. Photo by joshua sortino on unsplash.
from data-flair.training
First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. For example, suppose a table using date. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing columns is not a. Partitioning enhances query performance by allowing the database system to operate on. Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. Bucketing is another technique for decomposing data sets into more manageable parts. Photo by joshua sortino on unsplash. Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results for the search queries. In the world of data and analytics, storing and processing vast amounts of data.
Hive Partitioning vs Bucketing Advantages and Disadvantages DataFlair
Why Bucketing Is Faster Than Partitioning Bucketing is another technique for decomposing data sets into more manageable parts. In the world of data and analytics, storing and processing vast amounts of data. Bucketing is another technique for decomposing data sets into more manageable parts. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing columns is not a. Photo by joshua sortino on unsplash. Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results for the search queries. First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. For example, suppose a table using date. Partitioning enhances query performance by allowing the database system to operate on.
From www.newsletter.swirlai.com
SAI 26 Partitioning and Bucketing in Spark (Part 1) Why Bucketing Is Faster Than Partitioning For example, suppose a table using date. Bucketing is another technique for decomposing data sets into more manageable parts. Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. In the world of data and analytics, storing and processing vast amounts of data. First things first — both partitioning and bucketing are. Why Bucketing Is Faster Than Partitioning.
From quotessayings.net
Top 10 Bucketing And Partitioning Quotes & Sayings Why Bucketing Is Faster Than Partitioning Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. Partitioning enhances query performance by allowing the database system to operate on. In the world of data and analytics, storing and processing vast amounts. Why Bucketing Is Faster Than Partitioning.
From medium.com
When to use partitioning and when to use bucketing? by Brahmareddy Why Bucketing Is Faster Than Partitioning For example, suppose a table using date. Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results for the search queries. Bucketing is another technique for decomposing data sets into more. Why Bucketing Is Faster Than Partitioning.
From 9to5answer.com
[Solved] What is the difference between partitioning and 9to5Answer Why Bucketing Is Faster Than Partitioning The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing columns is not a. Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. Bucketing is another technique for decomposing data sets into more manageable parts. Partitioning enhances. Why Bucketing Is Faster Than Partitioning.
From data-flair.training
Bucketing in Hive Creation of Bucketed Table in Hive DataFlair Why Bucketing Is Faster Than Partitioning Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. In the world of data and analytics, storing and processing vast amounts of data. Photo by joshua sortino on unsplash. First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. The key observation is. Why Bucketing Is Faster Than Partitioning.
From www.youtube.com
Hive Partition And Bucketing Example Bigdata Hive Tutorial Hive Why Bucketing Is Faster Than Partitioning First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. Photo by joshua sortino on unsplash. Bucketing is another technique for decomposing data sets into more manageable parts. In the world of data and. Why Bucketing Is Faster Than Partitioning.
From www.youtube.com
Partitioning and bucketing in Spark Lec9 Practical video YouTube Why Bucketing Is Faster Than Partitioning In the world of data and analytics, storing and processing vast amounts of data. First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results for the search queries. Partitioning enhances query. Why Bucketing Is Faster Than Partitioning.
From www.youtube.com
Bucketing in Hive with Example Hive Partitioning with Bucketing Why Bucketing Is Faster Than Partitioning Partitioning enhances query performance by allowing the database system to operate on. First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results for the search queries. Photo by joshua sortino on. Why Bucketing Is Faster Than Partitioning.
From www.vrogue.co
Hive Partitioning Vs Bucketing Advantages And Disadva vrogue.co Why Bucketing Is Faster Than Partitioning In the world of data and analytics, storing and processing vast amounts of data. Photo by joshua sortino on unsplash. For example, suppose a table using date. Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. The key observation is that because the number of buckets is fixed (per partition), having. Why Bucketing Is Faster Than Partitioning.
From thepythoncoding.blogspot.com
Coding with python What is the difference between 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗶𝗻𝗴 𝗮𝗻𝗱 Why Bucketing Is Faster Than Partitioning Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results for the search queries. In the world of data and analytics, storing and processing vast amounts of data. First things first. Why Bucketing Is Faster Than Partitioning.
From realha.us.to
Hive Partitioning vs Bucketing Advantages and Disadvantages DataFlair Why Bucketing Is Faster Than Partitioning For example, suppose a table using date. In the world of data and analytics, storing and processing vast amounts of data. Photo by joshua sortino on unsplash. First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. Partitioning enhances query performance by allowing the database system to operate on. Bucketing is another. Why Bucketing Is Faster Than Partitioning.
From quotessayings.net
Top 10 Bucketing And Partitioning Quotes & Sayings Why Bucketing Is Faster Than Partitioning Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results for the search queries. In the world of data and analytics, storing and processing vast amounts of data. Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. The key observation. Why Bucketing Is Faster Than Partitioning.
From www.analyticsvidhya.com
Partitioning And Bucketing in Hive Bucketing vs Partitioning Why Bucketing Is Faster Than Partitioning In the world of data and analytics, storing and processing vast amounts of data. Photo by joshua sortino on unsplash. Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in. Why Bucketing Is Faster Than Partitioning.
From www.youtube.com
Ch.0234 Partitioning vs Bucketing Data Modeling YouTube Why Bucketing Is Faster Than Partitioning Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing. Why Bucketing Is Faster Than Partitioning.
From www.youtube.com
Partition vs Bucketing Data Engineer interview YouTube Why Bucketing Is Faster Than Partitioning Partitioning enhances query performance by allowing the database system to operate on. Photo by joshua sortino on unsplash. For example, suppose a table using date. First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular. Why Bucketing Is Faster Than Partitioning.
From engineering.chartboost.com
Partitioning and Bucketing Data. There are a lot of things we’d like to Why Bucketing Is Faster Than Partitioning For example, suppose a table using date. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing columns is not a. Photo by joshua sortino on unsplash. In the world of data and analytics, storing and processing vast amounts of data. Partitioning splits a large dataset. Why Bucketing Is Faster Than Partitioning.
From quadexcel.com
Partition vs bucketing Spark and Hive Interview Question Why Bucketing Is Faster Than Partitioning The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing columns is not a. Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results for the search queries. In the world of data and analytics,. Why Bucketing Is Faster Than Partitioning.
From sparkbyexamples.com
Hive Partitioning vs Bucketing with Examples? Spark By {Examples} Why Bucketing Is Faster Than Partitioning The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing columns is not a. Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. In the world of data and analytics, storing and processing vast amounts of data.. Why Bucketing Is Faster Than Partitioning.
From www.youtube.com
Partitioning and Bucketing in Hive 1 YouTube Why Bucketing Is Faster Than Partitioning Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing columns is not a. For example, suppose a table using date. In the world of data and analytics,. Why Bucketing Is Faster Than Partitioning.
From bigdatansql.com
When to avoid bucketing in Hive Big Data and SQL Why Bucketing Is Faster Than Partitioning For example, suppose a table using date. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing columns is not a. In the world of data and analytics, storing and processing vast amounts of data. Partitioning enhances query performance by allowing the database system to operate. Why Bucketing Is Faster Than Partitioning.
From www.youtube.com
Hive Partition And Bucketing Explained Hive Tutorial For Beginners Why Bucketing Is Faster Than Partitioning First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. Photo by joshua sortino on unsplash. Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results for the search queries. The key observation is that because the number of buckets is. Why Bucketing Is Faster Than Partitioning.
From bigdatansql.com
Bucketing_With_Partitioning Big Data and SQL Why Bucketing Is Faster Than Partitioning Partitioning enhances query performance by allowing the database system to operate on. In the world of data and analytics, storing and processing vast amounts of data. Bucketing is another technique for decomposing data sets into more manageable parts. For example, suppose a table using date. Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so. Why Bucketing Is Faster Than Partitioning.
From www.youtube.com
Hadoop Tutorial for Beginners 29 Hive Bucketing with Example Why Bucketing Is Faster Than Partitioning Photo by joshua sortino on unsplash. Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing columns is not a. Bucketing is another technique for decomposing data sets. Why Bucketing Is Faster Than Partitioning.
From data-flair.training
Hive Partitioning vs Bucketing Advantages and Disadvantages DataFlair Why Bucketing Is Faster Than Partitioning First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. For example, suppose a table using date. In the world of data and analytics, storing and processing vast amounts of data. Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results. Why Bucketing Is Faster Than Partitioning.
From medium.com
Partitioning and Bucketing in Hive Which and when? by Dennis de Why Bucketing Is Faster Than Partitioning Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results for the search queries. Partitioning enhances query performance by allowing the database system to operate on. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the. Why Bucketing Is Faster Than Partitioning.
From www.analyticsvidhya.com
Partitioning And Bucketing in Hive Bucketing vs Partitioning Why Bucketing Is Faster Than Partitioning Bucketing is another technique for decomposing data sets into more manageable parts. Partitioning enhances query performance by allowing the database system to operate on. Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results for the search queries. The key observation is that because the number of buckets is. Why Bucketing Is Faster Than Partitioning.
From www.newsletter.swirlai.com
SAI 26 Partitioning and Bucketing in Spark (Part 1) Why Bucketing Is Faster Than Partitioning Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results for the search queries. Partitioning enhances query performance by allowing the database system to operate on. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the. Why Bucketing Is Faster Than Partitioning.
From neuralmagic.com
2x Faster Inference with Sequence Bucketing and DeepSparse Neural Magic Why Bucketing Is Faster Than Partitioning In the world of data and analytics, storing and processing vast amounts of data. Partitioning enhances query performance by allowing the database system to operate on. Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. The key observation is that because the number of buckets is fixed (per partition), having a. Why Bucketing Is Faster Than Partitioning.
From self-learning-java-tutorial.blogspot.com
Programming for beginners Hive How to use Bucketing, partitioning Why Bucketing Is Faster Than Partitioning Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing columns is not a. Partitioning enhances query performance by allowing the database system to operate on. Photo by. Why Bucketing Is Faster Than Partitioning.
From quotessayings.net
Top 10 Bucketing And Partitioning Quotes & Sayings Why Bucketing Is Faster Than Partitioning Photo by joshua sortino on unsplash. Partitioning enhances query performance by allowing the database system to operate on. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing columns is not a. For example, suppose a table using date. Similar kinds of storage techniques like partitioning. Why Bucketing Is Faster Than Partitioning.
From medium.com
Spark Partitioning vs Bucketing partitionBy vs bucketBy Medium Why Bucketing Is Faster Than Partitioning In the world of data and analytics, storing and processing vast amounts of data. First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. Partitioning enhances query performance by allowing the database system to operate on. The key observation is that because the number of buckets is fixed (per partition), having a. Why Bucketing Is Faster Than Partitioning.
From www.okera.com
Bucketing in Hive Hive Bucketing Example With Okera Okera Why Bucketing Is Faster Than Partitioning Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing. Why Bucketing Is Faster Than Partitioning.
From medium.com
Apache Spark Bucketing and Partitioning. by Jay Nerd For Tech Medium Why Bucketing Is Faster Than Partitioning In the world of data and analytics, storing and processing vast amounts of data. Partitioning enhances query performance by allowing the database system to operate on. The key observation is that because the number of buckets is fixed (per partition), having a large number of distinct values in the bucketing columns is not a. Bucketing is another technique for decomposing. Why Bucketing Is Faster Than Partitioning.
From www.vrogue.co
Hive Partitioning Vs Bucketing Advantages And Disadva vrogue.co Why Bucketing Is Faster Than Partitioning Partitioning splits a large dataset into smaller, more manageable parts based on the values of a particular column. For example, suppose a table using date. Bucketing is another technique for decomposing data sets into more manageable parts. In the world of data and analytics, storing and processing vast amounts of data. Partitioning enhances query performance by allowing the database system. Why Bucketing Is Faster Than Partitioning.
From docs.cloudera.com
Hash and range partitioning Why Bucketing Is Faster Than Partitioning First things first — both partitioning and bucketing are techniques for dividing large datasets into manageable parts, thereby. Similar kinds of storage techniques like partitioning and bucketing are there in apache hive so that we can get faster results for the search queries. Partitioning enhances query performance by allowing the database system to operate on. Bucketing is another technique for. Why Bucketing Is Faster Than Partitioning.