What Is Spill In Spark . Spill is a critical concept in apache spark that significantly impacts the performance and. What is spill in apache spark: Spill is the term used to refer to the act of moving an rdd from ram to disk, and later back into ram again. If you don’t see any. It starts to move data from memory to disk, and this can be quite expensive. Is the size of the data as it. At its core, data spill in apache spark signifies the situation wherein the system resorts to writing intermediate data to disk when memory resources are insufficient. It is most common during data shuffling. Spill is what happens when spark runs low on memory. Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. Spill is what happens when spark runs low on memory. It is most common during data shuffling. Spill is represented by two values: (these two values are always presented together.) spill (memory): It starts to move data from memory to disk, and this can be quite expensive.
from xuechendi.github.io
Spill is represented by two values: (these two values are always presented together.) spill (memory): Spill is a critical concept in apache spark that significantly impacts the performance and. It starts to move data from memory to disk, and this can be quite expensive. It is most common during data shuffling. It starts to move data from memory to disk, and this can be quite expensive. This occurs when a given partition is simply too large. It is most common during data shuffling. Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. If you don’t see any.
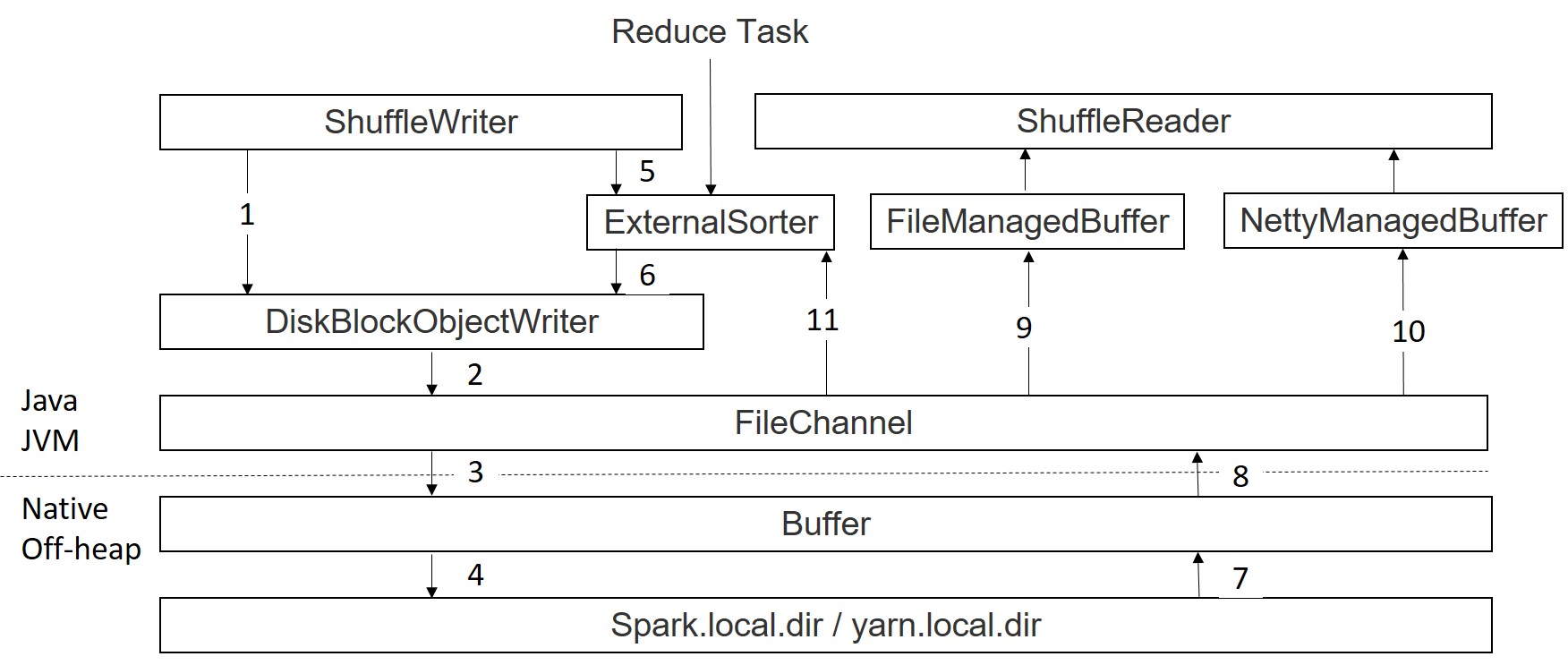
Difference between Spark Shuffle vs. Spill Chendi Xue's blog
What Is Spill In Spark It is most common during data shuffling. Spill problem happens when the moving of an rdd (resilient distributed dataset, aka fundamental data structure in spark) moves from ram to disk and then back to ram again. Spill is what happens when spark runs low on memory. It starts to move data from memory to disk, and this can be quite expensive. Spill is the term used to refer to the act of moving an rdd from ram to disk, and later back into ram again. It is most common during data shuffling. It starts to move data from memory to disk, and this can be quite expensive. What is spill in apache spark: This occurs when a given partition is simply too large. Is the size of the data as it. At its core, data spill in apache spark signifies the situation wherein the system resorts to writing intermediate data to disk when memory resources are insufficient. Spill is what happens when spark runs low on memory. (these two values are always presented together.) spill (memory): Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. It is most common during data shuffling. If you don’t see any.
From slideplayer.com
Saikat Biswas, A. Abuhoza, U. Frankenfeld, C. Garabatos, ppt download What Is Spill In Spark (these two values are always presented together.) spill (memory): Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. What is spill in apache spark: If you don’t see any. It starts to move data from memory to disk, and this can be quite expensive. It is most common during data shuffling.. What Is Spill In Spark.
From news.sky.com
Faulty sewage spill monitors spark accusations of 'environmental cover What Is Spill In Spark It starts to move data from memory to disk, and this can be quite expensive. Is the size of the data as it. It is most common during data shuffling. Spill is what happens when spark runs low on memory. Spill is the term used to refer to the act of moving an rdd from ram to disk, and later. What Is Spill In Spark.
From www.slideserve.com
PPT Chemical Spill Procedures PowerPoint Presentation, free download What Is Spill In Spark Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. Spill is the term used to refer to the act of moving an rdd from ram to disk, and later back into ram again. It is most common during data shuffling. This occurs when a given partition is simply too large. It. What Is Spill In Spark.
From slideplayer.com
Saikat Biswas, A. Abuhoza, U. Frankenfeld, C. Garabatos, ppt download What Is Spill In Spark Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. This occurs when a given partition is simply too large. (these two values are always presented together.) spill (memory): Spill is what happens when spark runs low on memory. It is most common during data shuffling. Spill is represented by two values:. What Is Spill In Spark.
From www.tastingtable.com
Why You Should Avoid Cleaning Up Your Spills At A Coffee Shop What Is Spill In Spark This occurs when a given partition is simply too large. (these two values are always presented together.) spill (memory): Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. It starts to move data from memory to disk, and this can be quite expensive. Is the size of the data as it.. What Is Spill In Spark.
From xuechendi.github.io
Difference between Spark Shuffle vs. Spill Chendi Xue's blog What Is Spill In Spark This occurs when a given partition is simply too large. Spill is represented by two values: It is most common during data shuffling. (these two values are always presented together.) spill (memory): What is spill in apache spark: It is most common during data shuffling. Spill is a critical concept in apache spark that significantly impacts the performance and. It. What Is Spill In Spark.
From www.spill.com.ng
Home SPILL NEWS What Is Spill In Spark If you don’t see any. What is spill in apache spark: Spill is the term used to refer to the act of moving an rdd from ram to disk, and later back into ram again. It is most common during data shuffling. Spill is what happens when spark runs low on memory. Spill is represented by two values: Is the. What Is Spill In Spark.
From time.com
Spill Is A New BlackOwned Twitter Alternative What to Know TIME What Is Spill In Spark This occurs when a given partition is simply too large. If you don’t see any. It is most common during data shuffling. Is the size of the data as it. Spill is what happens when spark runs low on memory. Spill is what happens when spark runs low on memory. (these two values are always presented together.) spill (memory): It. What Is Spill In Spark.
From kizastupid.weebly.com
kizastupid Blog What Is Spill In Spark It starts to move data from memory to disk, and this can be quite expensive. It is most common during data shuffling. Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. Spill problem happens when the moving of an rdd (resilient distributed dataset, aka fundamental data structure in spark) moves from. What Is Spill In Spark.
From www.uthsc.edu
Spark and Spill TLC UTHSC What Is Spill In Spark It is most common during data shuffling. Spill is represented by two values: It starts to move data from memory to disk, and this can be quite expensive. Spill is a critical concept in apache spark that significantly impacts the performance and. It starts to move data from memory to disk, and this can be quite expensive. What is spill. What Is Spill In Spark.
From oceanservice.noaa.gov
How does NOAA help clean up oil and chemical spills? What Is Spill In Spark What is spill in apache spark: At its core, data spill in apache spark signifies the situation wherein the system resorts to writing intermediate data to disk when memory resources are insufficient. Spill is what happens when spark runs low on memory. It starts to move data from memory to disk, and this can be quite expensive. If you don’t. What Is Spill In Spark.
From gyuhoonk.github.io
Partition, Spill in Spark What Is Spill In Spark Spill is represented by two values: What is spill in apache spark: Is the size of the data as it. It is most common during data shuffling. Spill is what happens when spark runs low on memory. It starts to move data from memory to disk, and this can be quite expensive. At its core, data spill in apache spark. What Is Spill In Spark.
From www.icecleaning.co.uk
How To Carry Out A Chemical Spill Risk Assessment What Is Spill In Spark Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. Spill is what happens when spark runs low on memory. At its core, data spill in apache spark signifies the situation wherein the system resorts to writing intermediate data to disk when memory resources are insufficient. Is the size of the data. What Is Spill In Spark.
From bigdataschool.ru
Из памяти на диск и обратно spillэффект в Apache Spark What Is Spill In Spark This occurs when a given partition is simply too large. It is most common during data shuffling. At its core, data spill in apache spark signifies the situation wherein the system resorts to writing intermediate data to disk when memory resources are insufficient. It starts to move data from memory to disk, and this can be quite expensive. Spill is. What Is Spill In Spark.
From stackoverflow.com
out of memory Why does spark shuffling not spill to disk ? Stack What Is Spill In Spark It starts to move data from memory to disk, and this can be quite expensive. Is the size of the data as it. Spill is the term used to refer to the act of moving an rdd from ram to disk, and later back into ram again. Spill is represented by two values: It is most common during data shuffling.. What Is Spill In Spark.
From exofwvuyf.blob.core.windows.net
Spill Kit Procedure In Hindi at Katherine Wyant blog What Is Spill In Spark Spill is the term used to refer to the act of moving an rdd from ram to disk, and later back into ram again. What is spill in apache spark: Spill is a critical concept in apache spark that significantly impacts the performance and. Disk spill in spark is a complex issue that can significantly impact the performance, cost, and. What Is Spill In Spark.
From stratex.com.au
3 Spill Kit Types Which to Choose? Stratex What Is Spill In Spark Spill is what happens when spark runs low on memory. It is most common during data shuffling. Spill is what happens when spark runs low on memory. At its core, data spill in apache spark signifies the situation wherein the system resorts to writing intermediate data to disk when memory resources are insufficient. Is the size of the data as. What Is Spill In Spark.
From www.bbc.com
Nigeria oil spills 'spark environmental genocide' What Is Spill In Spark Spill is what happens when spark runs low on memory. Spill is represented by two values: Spill is what happens when spark runs low on memory. Spill is a critical concept in apache spark that significantly impacts the performance and. It starts to move data from memory to disk, and this can be quite expensive. This occurs when a given. What Is Spill In Spark.
From intellipaat.com
How to optimize shuffle spill in Apache Spark application Intellipaat What Is Spill In Spark It starts to move data from memory to disk, and this can be quite expensive. (these two values are always presented together.) spill (memory): What is spill in apache spark: Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. This occurs when a given partition is simply too large. Spill is. What Is Spill In Spark.
From www.reddit.com
Spare a spill of spark in Kansas City? r/UplandMe What Is Spill In Spark (these two values are always presented together.) spill (memory): Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. Spill is the term used to refer to the act of moving an rdd from ram to disk, and later back into ram again. This occurs when a given partition is simply too. What Is Spill In Spark.
From stackoverflow.com
pyspark Why shuffle Spill (Memory) is more than spark driver/executor What Is Spill In Spark Spill is what happens when spark runs low on memory. Spill is what happens when spark runs low on memory. What is spill in apache spark: Spill is the term used to refer to the act of moving an rdd from ram to disk, and later back into ram again. It is most common during data shuffling. It starts to. What Is Spill In Spark.
From cefgsmep.blob.core.windows.net
What Is Spill Prevention at Sarah Klass blog What Is Spill In Spark Spill is what happens when spark runs low on memory. Spill problem happens when the moving of an rdd (resilient distributed dataset, aka fundamental data structure in spark) moves from ram to disk and then back to ram again. It starts to move data from memory to disk, and this can be quite expensive. Spill is the term used to. What Is Spill In Spark.
From splitseason.bandcamp.com
Split Season Volume Tahi (featuring spark ill / Spill Kit) Split Season What Is Spill In Spark What is spill in apache spark: At its core, data spill in apache spark signifies the situation wherein the system resorts to writing intermediate data to disk when memory resources are insufficient. Spill is what happens when spark runs low on memory. Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity.. What Is Spill In Spark.
From xuechendi.github.io
Difference between Spark Shuffle vs. Spill Chendi Xue's blog What Is Spill In Spark This occurs when a given partition is simply too large. Spill is what happens when spark runs low on memory. Spill problem happens when the moving of an rdd (resilient distributed dataset, aka fundamental data structure in spark) moves from ram to disk and then back to ram again. It is most common during data shuffling. It is most common. What Is Spill In Spark.
From royaldutchshellplc.com
BBC News Nigeria oil spills ‘spark environmental genocide’ Royal What Is Spill In Spark It starts to move data from memory to disk, and this can be quite expensive. At its core, data spill in apache spark signifies the situation wherein the system resorts to writing intermediate data to disk when memory resources are insufficient. Spill is a critical concept in apache spark that significantly impacts the performance and. Spill is what happens when. What Is Spill In Spark.
From michaelheil.medium.com
Understanding common Performance Issues in Apache Spark Deep Dive What Is Spill In Spark It starts to move data from memory to disk, and this can be quite expensive. It is most common during data shuffling. At its core, data spill in apache spark signifies the situation wherein the system resorts to writing intermediate data to disk when memory resources are insufficient. Spill is what happens when spark runs low on memory. What is. What Is Spill In Spark.
From www.crazygames.no
Spark Chess 🕹️ Spill Spark Chess på CrazyGames What Is Spill In Spark This occurs when a given partition is simply too large. Spill problem happens when the moving of an rdd (resilient distributed dataset, aka fundamental data structure in spark) moves from ram to disk and then back to ram again. It is most common during data shuffling. It is most common during data shuffling. Spill is the term used to refer. What Is Spill In Spark.
From www.databricks.training
Spark UI Simulator Databricks Academy What Is Spill In Spark It is most common during data shuffling. Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. This occurs when a given partition is simply too large. It starts to move data from memory to disk, and this can be quite expensive. Spill is what happens when spark runs low on memory.. What Is Spill In Spark.
From mavink.com
Chemical Spill Photos What Is Spill In Spark Spill is represented by two values: Spill is what happens when spark runs low on memory. It starts to move data from memory to disk, and this can be quite expensive. Spill problem happens when the moving of an rdd (resilient distributed dataset, aka fundamental data structure in spark) moves from ram to disk and then back to ram again.. What Is Spill In Spark.
From cefgsmep.blob.core.windows.net
What Is Spill Prevention at Sarah Klass blog What Is Spill In Spark Is the size of the data as it. If you don’t see any. Spill is represented by two values: What is spill in apache spark: (these two values are always presented together.) spill (memory): This occurs when a given partition is simply too large. Spill is a critical concept in apache spark that significantly impacts the performance and. Spill problem. What Is Spill In Spark.
From www.slideserve.com
PPT Spill Response, CleanUp, and Emergency Response PowerPoint What Is Spill In Spark At its core, data spill in apache spark signifies the situation wherein the system resorts to writing intermediate data to disk when memory resources are insufficient. This occurs when a given partition is simply too large. Spill problem happens when the moving of an rdd (resilient distributed dataset, aka fundamental data structure in spark) moves from ram to disk and. What Is Spill In Spark.
From www.youtube.com
Otimizações no Apache Spark Spill, Skew e Shuffle Live 76 YouTube What Is Spill In Spark It starts to move data from memory to disk, and this can be quite expensive. At its core, data spill in apache spark signifies the situation wherein the system resorts to writing intermediate data to disk when memory resources are insufficient. Spill problem happens when the moving of an rdd (resilient distributed dataset, aka fundamental data structure in spark) moves. What Is Spill In Spark.
From www.nedtinc.com
Emergency Spill Response for Oil & Chemical Accidents NEDT, Inc. What Is Spill In Spark This occurs when a given partition is simply too large. Spill is represented by two values: Is the size of the data as it. It is most common during data shuffling. Spill is what happens when spark runs low on memory. (these two values are always presented together.) spill (memory): At its core, data spill in apache spark signifies the. What Is Spill In Spark.
From medium.com
How to check Tables relationship ER diagram (Data Model) Snowflake data What Is Spill In Spark It starts to move data from memory to disk, and this can be quite expensive. Spill problem happens when the moving of an rdd (resilient distributed dataset, aka fundamental data structure in spark) moves from ram to disk and then back to ram again. Spill is what happens when spark runs low on memory. Spill is what happens when spark. What Is Spill In Spark.
From stackoverflow.com
scala spark shuffle spill to disk always happen even there is enough What Is Spill In Spark This occurs when a given partition is simply too large. (these two values are always presented together.) spill (memory): It starts to move data from memory to disk, and this can be quite expensive. Spill is represented by two values: Spill is a critical concept in apache spark that significantly impacts the performance and. What is spill in apache spark:. What Is Spill In Spark.