What Is Disk Spill In Spark . It starts to move data from memory to disk, and this can be quite expensive. Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. Shuffle spill is controlled by the spark.shuffle.spill and spark.shuffle.memoryfraction configuration parameters. If you don’t see any. Spill is represented by two values: Is the size of the data as it exists in memory before it is spilled. Is the size of the data as it. Ever wondered how does spark manages its memory allocation? Is size of the data that gets spilled, serialized and, written into disk and gets. If spill is enabled (it is by default). When you specify 8gb memory (for example), what part of it is used for execution and what part is used for caching? It is most common during data shuffling. (these two values are always presented together.) spill (memory): Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. Spill is what happens when spark runs low on memory.
from data-flair.training
If spill is enabled (it is by default). It starts to move data from memory to disk, and this can be quite expensive. Is the size of the data as it. Is the size of the data as it exists in memory before it is spilled. When you specify 8gb memory (for example), what part of it is used for execution and what part is used for caching? It is most common during data shuffling. If you don’t see any. Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. Spill is represented by two values: Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity.
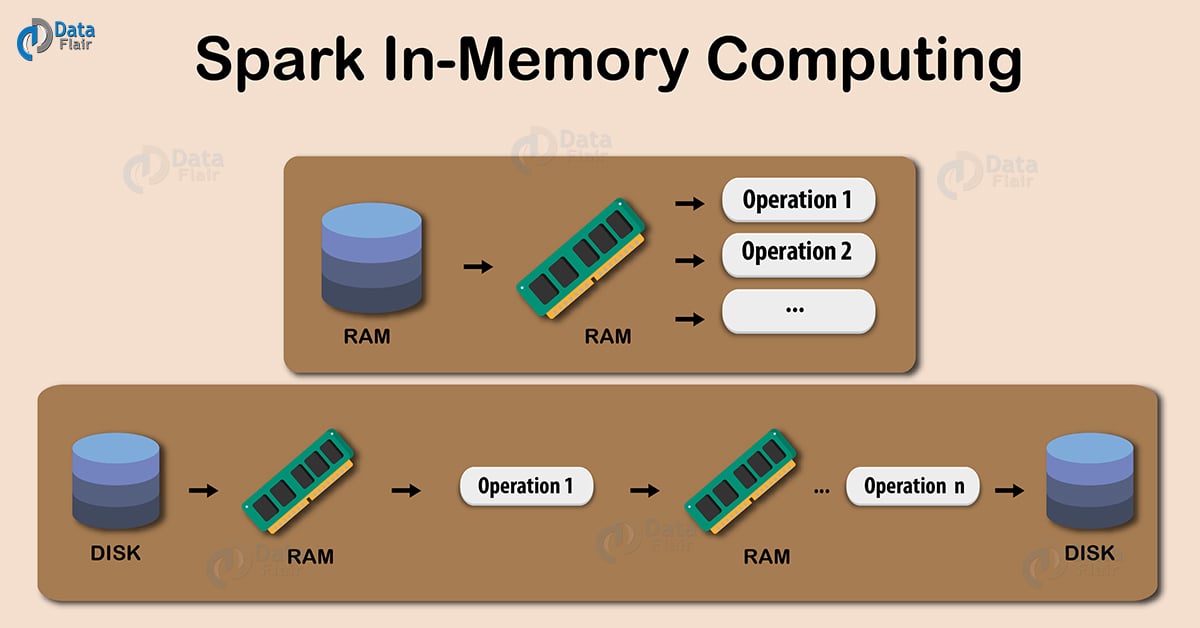
Spark InMemory Computing A Beginners Guide DataFlair
What Is Disk Spill In Spark Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. Is the size of the data as it exists in memory before it is spilled. If you don’t see any. (these two values are always presented together.) spill (memory): Spill is represented by two values: It is most common during data shuffling. If spill is enabled (it is by default). Shuffle spill is controlled by the spark.shuffle.spill and spark.shuffle.memoryfraction configuration parameters. Is the size of the data as it. Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. Ever wondered how does spark manages its memory allocation? Is size of the data that gets spilled, serialized and, written into disk and gets. When you specify 8gb memory (for example), what part of it is used for execution and what part is used for caching? Spill is what happens when spark runs low on memory. Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. It starts to move data from memory to disk, and this can be quite expensive.
From 0x0fff.com
Spark Architecture Shuffle Distributed Systems Architecture What Is Disk Spill In Spark It is most common during data shuffling. Is the size of the data as it. When you specify 8gb memory (for example), what part of it is used for execution and what part is used for caching? Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. If you don’t see any.. What Is Disk Spill In Spark.
From aifuturevisions.com
Memory Management in Apache Spark Disk Spill by Tom Corbin Sep What Is Disk Spill In Spark Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. It starts to move data from memory to disk, and this can be quite expensive. When you specify 8gb memory (for example), what part of it is used for execution and what part is used for caching? Disk. What Is Disk Spill In Spark.
From slideplayer.com
DataIntensive Distributed Computing ppt download What Is Disk Spill In Spark Is the size of the data as it exists in memory before it is spilled. If you don’t see any. Spill is what happens when spark runs low on memory. (these two values are always presented together.) spill (memory): Is size of the data that gets spilled, serialized and, written into disk and gets. If spill is enabled (it is. What Is Disk Spill In Spark.
From www.slideserve.com
PPT Deploying and Administering Spark PowerPoint Presentation, free What Is Disk Spill In Spark If you don’t see any. It starts to move data from memory to disk, and this can be quite expensive. (these two values are always presented together.) spill (memory): Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. Disk spill in spark is a complex issue that. What Is Disk Spill In Spark.
From medium.com
REPOST Apache Spark’s Resiliency to Local Disk Failures — Working What Is Disk Spill In Spark When you specify 8gb memory (for example), what part of it is used for execution and what part is used for caching? Shuffle spill is controlled by the spark.shuffle.spill and spark.shuffle.memoryfraction configuration parameters. Is the size of the data as it exists in memory before it is spilled. Disk spill in spark is a complex issue that can significantly impact. What Is Disk Spill In Spark.
From gyuhoonk.github.io
Partition, Spill in Spark What Is Disk Spill In Spark Spill is what happens when spark runs low on memory. If you don’t see any. Shuffle spill is controlled by the spark.shuffle.spill and spark.shuffle.memoryfraction configuration parameters. It is most common during data shuffling. (these two values are always presented together.) spill (memory): Disk spill is what happens when spark can now not fit its data in memory, and wishes to. What Is Disk Spill In Spark.
From developer.nvidia.com
Accelerating Apache Spark 3.0 with GPUs and RAPIDS NVIDIA Developer Blog What Is Disk Spill In Spark Is the size of the data as it exists in memory before it is spilled. When you specify 8gb memory (for example), what part of it is used for execution and what part is used for caching? If you don’t see any. It starts to move data from memory to disk, and this can be quite expensive. Is the size. What Is Disk Spill In Spark.
From manushgupta.github.io
SPARK vs Hadoop MapReduce Manush Gupta What Is Disk Spill In Spark If you don’t see any. Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. Spill is represented by two values: (these two values are always presented together.) spill (memory): Is the size of the data as it exists in memory before it is spilled. Is size of the data that gets. What Is Disk Spill In Spark.
From helpjuice.com
Runbook vs Playbook Understanding the Key Differences What Is Disk Spill In Spark If you don’t see any. Spill is represented by two values: It starts to move data from memory to disk, and this can be quite expensive. Is the size of the data as it exists in memory before it is spilled. If spill is enabled (it is by default). When you specify 8gb memory (for example), what part of it. What Is Disk Spill In Spark.
From stackoverflow.com
scala Spark why does spark spill to disk? Stack Overflow What Is Disk Spill In Spark (these two values are always presented together.) spill (memory): Is the size of the data as it. Is the size of the data as it exists in memory before it is spilled. Spill is what happens when spark runs low on memory. If you don’t see any. Shuffle spill is controlled by the spark.shuffle.spill and spark.shuffle.memoryfraction configuration parameters. Disk spill. What Is Disk Spill In Spark.
From blog.csdn.net
spark基本知识点之Shuffle_separate file for each media typeCSDN博客 What Is Disk Spill In Spark It is most common during data shuffling. Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. If you don’t see any. Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. Shuffle spill is controlled by the spark.shuffle.spill and. What Is Disk Spill In Spark.
From arganzheng.life
Spark Executor内存管理 郑志彬的博客 Arganzheng's Blog What Is Disk Spill In Spark Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. Shuffle spill is controlled by the spark.shuffle.spill and spark.shuffle.memoryfraction configuration parameters. When you specify 8gb memory (for example), what part of it is used for execution and what part is used for caching? Ever wondered how does spark. What Is Disk Spill In Spark.
From vanducng.dev
Spark hierarchy vanducng What Is Disk Spill In Spark Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. When you specify 8gb memory (for example), what part of it is used for execution and what part is used for caching? (these two values are always presented together.) spill (memory): It starts to move data from memory to disk, and this. What Is Disk Spill In Spark.
From dagster.io
Spill to Disk Dagster Glossary What Is Disk Spill In Spark If you don’t see any. It is most common during data shuffling. Is the size of the data as it. Ever wondered how does spark manages its memory allocation? Spill is represented by two values: Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. Is the size of the data as. What Is Disk Spill In Spark.
From stackoverflow.com
scala Spark Shuffle Configuration Disk Spill evaluation Stack Overflow What Is Disk Spill In Spark If you don’t see any. When you specify 8gb memory (for example), what part of it is used for execution and what part is used for caching? Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. It is most common during data shuffling. Is the size of. What Is Disk Spill In Spark.
From xuechendi.github.io
Difference between Spark Shuffle vs. Spill Chendi Xue's blog What Is Disk Spill In Spark Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. Spill is what happens when spark runs low on memory. When you specify 8gb memory (for example), what part of it is used for execution and what part is used for caching? It starts to move data from. What Is Disk Spill In Spark.
From fossil-engineering.github.io
Spark on tại Fossil What Is Disk Spill In Spark Spill is what happens when spark runs low on memory. Ever wondered how does spark manages its memory allocation? Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. Is the size of the data as it. Is size of the data that gets spilled, serialized and, written. What Is Disk Spill In Spark.
From engenhariadedadosacademy.com
Advanced Spark Programing Engenharia de Dados Academy What Is Disk Spill In Spark Shuffle spill is controlled by the spark.shuffle.spill and spark.shuffle.memoryfraction configuration parameters. Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. Spill is represented by two values: Ever wondered how. What Is Disk Spill In Spark.
From stackoverflow.com
out of memory Why does spark shuffling not spill to disk ? Stack What Is Disk Spill In Spark Shuffle spill is controlled by the spark.shuffle.spill and spark.shuffle.memoryfraction configuration parameters. Is the size of the data as it. Spill is represented by two values: Is size of the data that gets spilled, serialized and, written into disk and gets. (these two values are always presented together.) spill (memory): Ever wondered how does spark manages its memory allocation? Disk spill. What Is Disk Spill In Spark.
From vanducng.dev
Spark hierarchy vanducng What Is Disk Spill In Spark Ever wondered how does spark manages its memory allocation? Is size of the data that gets spilled, serialized and, written into disk and gets. Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. It is most common during data shuffling. Spill is what happens when spark runs low on memory. Is. What Is Disk Spill In Spark.
From jelvix.com
Spark vs Hadoop What to Choose to Process Big Data What Is Disk Spill In Spark If spill is enabled (it is by default). Spill is represented by two values: Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. Shuffle spill is controlled by the spark.shuffle.spill and spark.shuffle.memoryfraction configuration parameters. (these two values are always presented together.) spill (memory): Disk spill in spark. What Is Disk Spill In Spark.
From stackoverflow.com
scala Spark why does spark spill to disk? Stack Overflow What Is Disk Spill In Spark Is the size of the data as it. Ever wondered how does spark manages its memory allocation? Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. Is size of the data that gets spilled, serialized and, written into disk and gets. If spill is enabled (it is. What Is Disk Spill In Spark.
From www.youtube.com
How to write dataframe to disk in spark Lec8 YouTube What Is Disk Spill In Spark Is the size of the data as it. If you don’t see any. Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. Ever wondered how does spark manages its memory allocation? Is the size of the data as it exists in memory before it is spilled. Is. What Is Disk Spill In Spark.
From stackoverflow.com
scala Spark why does spark spill to disk? Stack Overflow What Is Disk Spill In Spark Spill is what happens when spark runs low on memory. Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. Shuffle spill is controlled by the spark.shuffle.spill and spark.shuffle.memoryfraction configuration parameters. If spill is enabled (it is by default). When you specify 8gb memory (for example), what part of it is used. What Is Disk Spill In Spark.
From 9to5answer.com
[Solved] How to optimize shuffle spill in Apache Spark 9to5Answer What Is Disk Spill In Spark (these two values are always presented together.) spill (memory): Is size of the data that gets spilled, serialized and, written into disk and gets. If you don’t see any. It starts to move data from memory to disk, and this can be quite expensive. Disk spill is what happens when spark can now not fit its data in memory, and. What Is Disk Spill In Spark.
From manushgupta.github.io
SPARK vs Hadoop MapReduce Manush Gupta What Is Disk Spill In Spark Spill is represented by two values: Is the size of the data as it exists in memory before it is spilled. It is most common during data shuffling. If spill is enabled (it is by default). Ever wondered how does spark manages its memory allocation? Disk spill is what happens when spark can now not fit its data in memory,. What Is Disk Spill In Spark.
From multitechnewstoday.blogspot.com
Bacics of Apache spark in Big data Hadoop OnlineITGuru Multitechnews What Is Disk Spill In Spark It starts to move data from memory to disk, and this can be quite expensive. Spill is represented by two values: When you specify 8gb memory (for example), what part of it is used for execution and what part is used for caching? Is size of the data that gets spilled, serialized and, written into disk and gets. (these two. What Is Disk Spill In Spark.
From bigdataschool.ru
Из памяти на диск и обратно spillэффект в Apache Spark What Is Disk Spill In Spark Shuffle spill is controlled by the spark.shuffle.spill and spark.shuffle.memoryfraction configuration parameters. Spill is represented by two values: (these two values are always presented together.) spill (memory): If you don’t see any. Is size of the data that gets spilled, serialized and, written into disk and gets. Ever wondered how does spark manages its memory allocation? Is the size of the. What Is Disk Spill In Spark.
From xuechendi.github.io
Difference between Spark Shuffle vs. Spill Chendi Xue's blog What Is Disk Spill In Spark It is most common during data shuffling. Is the size of the data as it exists in memory before it is spilled. Spill is represented by two values: Is size of the data that gets spilled, serialized and, written into disk and gets. It starts to move data from memory to disk, and this can be quite expensive. Is the. What Is Disk Spill In Spark.
From data-flair.training
Spark InMemory Computing A Beginners Guide DataFlair What Is Disk Spill In Spark Shuffle spill is controlled by the spark.shuffle.spill and spark.shuffle.memoryfraction configuration parameters. (these two values are always presented together.) spill (memory): It is most common during data shuffling. It starts to move data from memory to disk, and this can be quite expensive. Spill is represented by two values: If spill is enabled (it is by default). Disk spill in spark. What Is Disk Spill In Spark.
From www.datasciencelearner.com
Apache Spark in Python Beginner's Guide What Is Disk Spill In Spark It is most common during data shuffling. Spill is what happens when spark runs low on memory. Is size of the data that gets spilled, serialized and, written into disk and gets. When you specify 8gb memory (for example), what part of it is used for execution and what part is used for caching? Is the size of the data. What Is Disk Spill In Spark.
From www.simplilearn.com
Spark Parallelize The Essential Element of Spark What Is Disk Spill In Spark Ever wondered how does spark manages its memory allocation? It is most common during data shuffling. Spill is represented by two values: Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it. What Is Disk Spill In Spark.
From www.altexsoft.com
Apache Hadoop vs Spark Main Big Data Tools Explained AltexSoft What Is Disk Spill In Spark If you don’t see any. Ever wondered how does spark manages its memory allocation? Is size of the data that gets spilled, serialized and, written into disk and gets. (these two values are always presented together.) spill (memory): Is the size of the data as it exists in memory before it is spilled. Is the size of the data as. What Is Disk Spill In Spark.
From stackoverflow.com
scala spark shuffle spill to disk always happen even there is enough What Is Disk Spill In Spark Shuffle spill is controlled by the spark.shuffle.spill and spark.shuffle.memoryfraction configuration parameters. If you don’t see any. (these two values are always presented together.) spill (memory): Disk spill is what happens when spark can now not fit its data in memory, and wishes to store it on disk. Ever wondered how does spark manages its memory allocation? Disk spill in spark. What Is Disk Spill In Spark.
From stackoverflow.com
java Apache Spark 1.6 spills to disk even when there is enough memory What Is Disk Spill In Spark Shuffle spill is controlled by the spark.shuffle.spill and spark.shuffle.memoryfraction configuration parameters. Is size of the data that gets spilled, serialized and, written into disk and gets. Disk spill in spark is a complex issue that can significantly impact the performance, cost, and operational complexity. If you don’t see any. If spill is enabled (it is by default). Spill is represented. What Is Disk Spill In Spark.