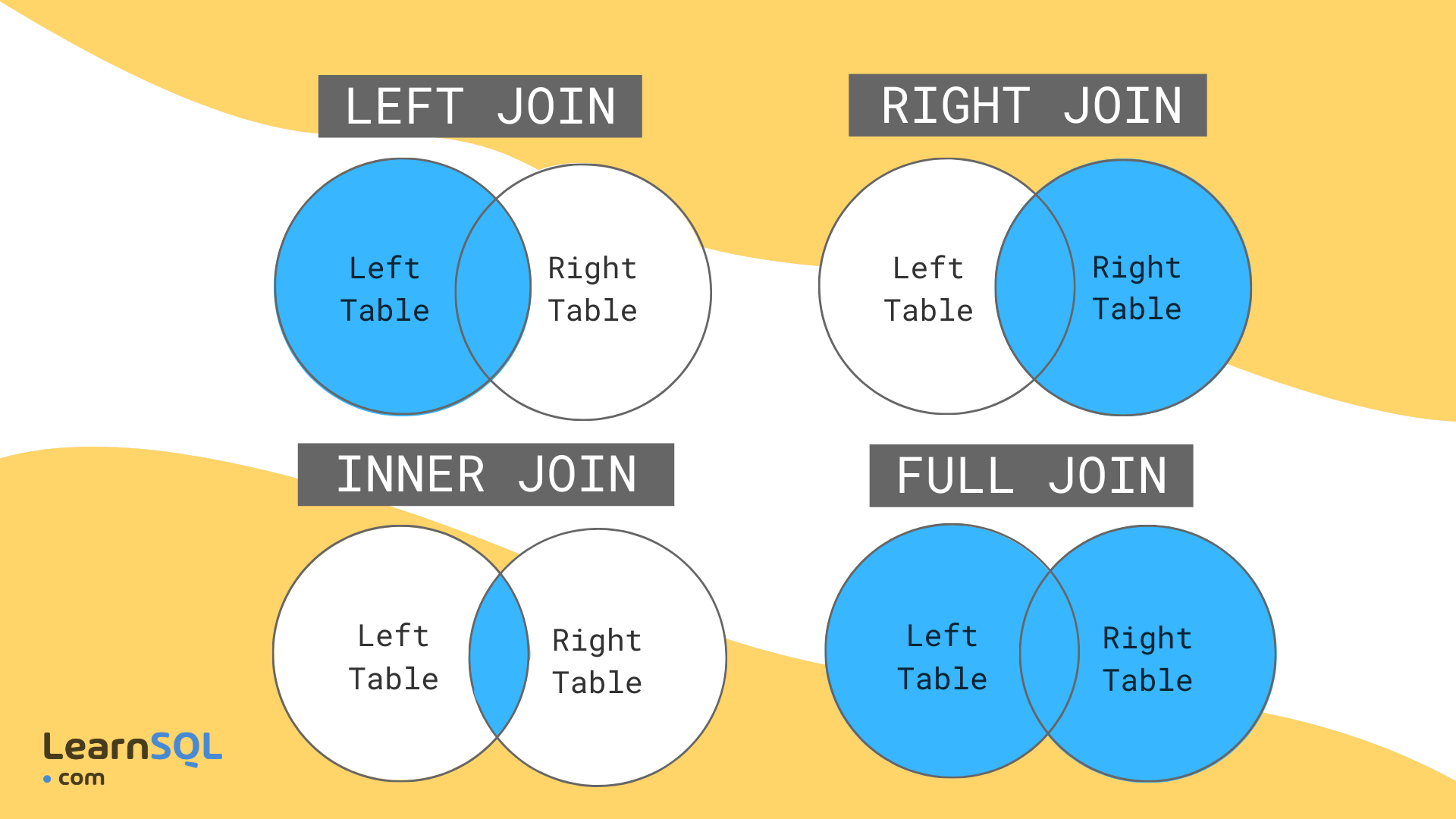
Big Table Small Table Join Strategy . Shuffle hash join encompasses the following sequential steps: This should make the planner seek out. Looking at what tables we usually join with spark, we can identify two situations: We may be joining a big table with a. Both datasets (tables) will be shuffled among the executors based on the key column. We basically had to convert: Armed with the knowledge, we thought that if we could just remove the join from the query, it should return faster. Let's say i have a large table l and a small table s (100k rows vs. First scan the small table b to make the hash buckets, then scan the big table a to find the matching rows from b via the hash. Teradata uses different strategies to perform join between two tables. The smaller shuffled dataset (table) will be hashed in. Data distribution and columns selected for joins heavily influence the execution. Oversimplifying how spark joins tables. The only reasonable plan is thus to seq scan the small table and to nest loop the mess with the huge one. Try adding a clustered index on hugetable(added, fk).
from learnsql.es
Would there be any difference in terms of speed between the. We basically had to convert: Let's say i have a large table l and a small table s (100k rows vs. Both datasets (tables) will be shuffled among the executors based on the key column. Data distribution and columns selected for joins heavily influence the execution. Teradata uses different strategies to perform join between two tables. Try adding a clustered index on hugetable(added, fk). Armed with the knowledge, we thought that if we could just remove the join from the query, it should return faster. Looking at what tables we usually join with spark, we can identify two situations: We may be joining a big table with a.
Cómo aprender a hacer JOINs en SQL LearnSQL.es
Big Table Small Table Join Strategy Try adding a clustered index on hugetable(added, fk). First scan the small table b to make the hash buckets, then scan the big table a to find the matching rows from b via the hash. The smaller shuffled dataset (table) will be hashed in. Would there be any difference in terms of speed between the. Oversimplifying how spark joins tables. We may be joining a big table with a. Shuffle hash join encompasses the following sequential steps: We basically had to convert: Data distribution and columns selected for joins heavily influence the execution. Teradata uses different strategies to perform join between two tables. Let's say i have a large table l and a small table s (100k rows vs. Looking at what tables we usually join with spark, we can identify two situations: The only reasonable plan is thus to seq scan the small table and to nest loop the mess with the huge one. Try adding a clustered index on hugetable(added, fk). Armed with the knowledge, we thought that if we could just remove the join from the query, it should return faster. Both datasets (tables) will be shuffled among the executors based on the key column.
From towardsdatascience.com
Spark Join Strategies — How & What? by Jyoti Dhiman Towards Data Big Table Small Table Join Strategy The only reasonable plan is thus to seq scan the small table and to nest loop the mess with the huge one. Try adding a clustered index on hugetable(added, fk). We may be joining a big table with a. First scan the small table b to make the hash buckets, then scan the big table a to find the matching. Big Table Small Table Join Strategy.
From www.pinterest.com
Visual Explanation of Joins. This card explains how to perform tables Big Table Small Table Join Strategy Oversimplifying how spark joins tables. Let's say i have a large table l and a small table s (100k rows vs. We basically had to convert: Shuffle hash join encompasses the following sequential steps: Both datasets (tables) will be shuffled among the executors based on the key column. We may be joining a big table with a. Looking at what. Big Table Small Table Join Strategy.
From www.youtube.com
Table Joins Part 1 Table Join Introduction SSMS TSQL Tutorial Big Table Small Table Join Strategy Try adding a clustered index on hugetable(added, fk). Shuffle hash join encompasses the following sequential steps: The only reasonable plan is thus to seq scan the small table and to nest loop the mess with the huge one. Both datasets (tables) will be shuffled among the executors based on the key column. Armed with the knowledge, we thought that if. Big Table Small Table Join Strategy.
From www.scaler.com
SQL JOINS (INNER, LEFT, RIGHT, and FULL Join) Scaler Topics Big Table Small Table Join Strategy Teradata uses different strategies to perform join between two tables. First scan the small table b to make the hash buckets, then scan the big table a to find the matching rows from b via the hash. We basically had to convert: Oversimplifying how spark joins tables. Armed with the knowledge, we thought that if we could just remove the. Big Table Small Table Join Strategy.
From www.goskills.com
Solving ManyToMany Joins with Bridge Tables Theory Microsoft Big Table Small Table Join Strategy Would there be any difference in terms of speed between the. Oversimplifying how spark joins tables. The only reasonable plan is thus to seq scan the small table and to nest loop the mess with the huge one. This should make the planner seek out. Armed with the knowledge, we thought that if we could just remove the join from. Big Table Small Table Join Strategy.
From mindmajix.com
SQL Server Joins Different Types Of Joins In SQL Server Big Table Small Table Join Strategy Shuffle hash join encompasses the following sequential steps: Looking at what tables we usually join with spark, we can identify two situations: Would there be any difference in terms of speed between the. The smaller shuffled dataset (table) will be hashed in. We basically had to convert: The only reasonable plan is thus to seq scan the small table and. Big Table Small Table Join Strategy.
From elchoroukhost.net
Sql Join Multiple Tables With Conditions Elcho Table Big Table Small Table Join Strategy This should make the planner seek out. Shuffle hash join encompasses the following sequential steps: The smaller shuffled dataset (table) will be hashed in. First scan the small table b to make the hash buckets, then scan the big table a to find the matching rows from b via the hash. Both datasets (tables) will be shuffled among the executors. Big Table Small Table Join Strategy.
From teradatainterviewquestion.blogspot.com
Teradata Interview Questions Teradata Joining Strategies Big Table Small Table Join Strategy Let's say i have a large table l and a small table s (100k rows vs. Oversimplifying how spark joins tables. Would there be any difference in terms of speed between the. The only reasonable plan is thus to seq scan the small table and to nest loop the mess with the huge one. Armed with the knowledge, we thought. Big Table Small Table Join Strategy.
From tsqlcirclelive.blogspot.com
Teach TSQL with Circle Live SQL Basics for Beginner Big Table Small Table Join Strategy Both datasets (tables) will be shuffled among the executors based on the key column. Teradata uses different strategies to perform join between two tables. The smaller shuffled dataset (table) will be hashed in. Data distribution and columns selected for joins heavily influence the execution. Would there be any difference in terms of speed between the. Oversimplifying how spark joins tables.. Big Table Small Table Join Strategy.
From www.youtube.com
How To Break Out Large Tables Into Multiple Tables And Build A Model Big Table Small Table Join Strategy The smaller shuffled dataset (table) will be hashed in. Both datasets (tables) will be shuffled among the executors based on the key column. Let's say i have a large table l and a small table s (100k rows vs. Armed with the knowledge, we thought that if we could just remove the join from the query, it should return faster.. Big Table Small Table Join Strategy.
From teradatainterviewquestion.blogspot.com
Teradata Interview Questions Teradata Joining Strategies Big Table Small Table Join Strategy First scan the small table b to make the hash buckets, then scan the big table a to find the matching rows from b via the hash. Looking at what tables we usually join with spark, we can identify two situations: Teradata uses different strategies to perform join between two tables. Armed with the knowledge, we thought that if we. Big Table Small Table Join Strategy.
From dokumen.tips
(PDF) Greenplum SQL Class Outline · Greenplum Join Big Table Small Table Join Strategy The smaller shuffled dataset (table) will be hashed in. Armed with the knowledge, we thought that if we could just remove the join from the query, it should return faster. Let's say i have a large table l and a small table s (100k rows vs. This should make the planner seek out. Oversimplifying how spark joins tables. Both datasets. Big Table Small Table Join Strategy.
From brokeasshome.com
How To Join 3 Tables Using Inner In Sql Server Management Studio Big Table Small Table Join Strategy Teradata uses different strategies to perform join between two tables. Data distribution and columns selected for joins heavily influence the execution. First scan the small table b to make the hash buckets, then scan the big table a to find the matching rows from b via the hash. We may be joining a big table with a. The only reasonable. Big Table Small Table Join Strategy.
From hevodata.com
Working with BigQuery List Tables Made Easy 101 Learn Hevo Big Table Small Table Join Strategy Let's say i have a large table l and a small table s (100k rows vs. We basically had to convert: The smaller shuffled dataset (table) will be hashed in. Both datasets (tables) will be shuffled among the executors based on the key column. Teradata uses different strategies to perform join between two tables. Looking at what tables we usually. Big Table Small Table Join Strategy.
From fyotmipgw.blob.core.windows.net
Joining Tables Across Databases Sql Server at Steven Jenkins blog Big Table Small Table Join Strategy Shuffle hash join encompasses the following sequential steps: Would there be any difference in terms of speed between the. We basically had to convert: The only reasonable plan is thus to seq scan the small table and to nest loop the mess with the huge one. Try adding a clustered index on hugetable(added, fk). The smaller shuffled dataset (table) will. Big Table Small Table Join Strategy.
From www.geeksforgeeks.org
Joining three or more tables in SQL Big Table Small Table Join Strategy Both datasets (tables) will be shuffled among the executors based on the key column. First scan the small table b to make the hash buckets, then scan the big table a to find the matching rows from b via the hash. We may be joining a big table with a. Would there be any difference in terms of speed between. Big Table Small Table Join Strategy.
From cloud.google.com
How to perform joins and data denormalization with nested and repeated Big Table Small Table Join Strategy Let's say i have a large table l and a small table s (100k rows vs. First scan the small table b to make the hash buckets, then scan the big table a to find the matching rows from b via the hash. We may be joining a big table with a. Would there be any difference in terms of. Big Table Small Table Join Strategy.
From learnsql.es
Cómo aprender a hacer JOINs en SQL LearnSQL.es Big Table Small Table Join Strategy The smaller shuffled dataset (table) will be hashed in. We basically had to convert: Would there be any difference in terms of speed between the. Shuffle hash join encompasses the following sequential steps: Armed with the knowledge, we thought that if we could just remove the join from the query, it should return faster. First scan the small table b. Big Table Small Table Join Strategy.
From www.youtube.com
How to Join Three Tables in SQL using Inner Joins By SYED I.T Big Table Small Table Join Strategy Looking at what tables we usually join with spark, we can identify two situations: Data distribution and columns selected for joins heavily influence the execution. Shuffle hash join encompasses the following sequential steps: Teradata uses different strategies to perform join between two tables. Try adding a clustered index on hugetable(added, fk). First scan the small table b to make the. Big Table Small Table Join Strategy.
From exybhshln.blob.core.windows.net
Create Table Join Sql at Tiffany Lin blog Big Table Small Table Join Strategy Try adding a clustered index on hugetable(added, fk). Would there be any difference in terms of speed between the. We may be joining a big table with a. Armed with the knowledge, we thought that if we could just remove the join from the query, it should return faster. We basically had to convert: Both datasets (tables) will be shuffled. Big Table Small Table Join Strategy.
From data-lessons.github.io
Software Carpentry R for reproducible scientific analysis Big Table Small Table Join Strategy Shuffle hash join encompasses the following sequential steps: Oversimplifying how spark joins tables. The smaller shuffled dataset (table) will be hashed in. Would there be any difference in terms of speed between the. Armed with the knowledge, we thought that if we could just remove the join from the query, it should return faster. We basically had to convert: Teradata. Big Table Small Table Join Strategy.
From www.youtube.com
How to Join two or more than two Tables using multiple columns How to Big Table Small Table Join Strategy Try adding a clustered index on hugetable(added, fk). Data distribution and columns selected for joins heavily influence the execution. Both datasets (tables) will be shuffled among the executors based on the key column. Armed with the knowledge, we thought that if we could just remove the join from the query, it should return faster. First scan the small table b. Big Table Small Table Join Strategy.
From www.programiz.com
SQL JOIN (With Examples) Big Table Small Table Join Strategy This should make the planner seek out. Let's say i have a large table l and a small table s (100k rows vs. Shuffle hash join encompasses the following sequential steps: Looking at what tables we usually join with spark, we can identify two situations: Data distribution and columns selected for joins heavily influence the execution. Both datasets (tables) will. Big Table Small Table Join Strategy.
From www.youtube.com
Joining tables in BigQuery SQL YouTube Big Table Small Table Join Strategy Looking at what tables we usually join with spark, we can identify two situations: Both datasets (tables) will be shuffled among the executors based on the key column. Teradata uses different strategies to perform join between two tables. First scan the small table b to make the hash buckets, then scan the big table a to find the matching rows. Big Table Small Table Join Strategy.
From acuto.io
How to Write BigQuery LEFT JOIN Functions in Standard SQL Big Table Small Table Join Strategy The smaller shuffled dataset (table) will be hashed in. Armed with the knowledge, we thought that if we could just remove the join from the query, it should return faster. Teradata uses different strategies to perform join between two tables. Would there be any difference in terms of speed between the. Data distribution and columns selected for joins heavily influence. Big Table Small Table Join Strategy.
From stackoverflow.com
Basic SQL Joining Tables Stack Overflow Big Table Small Table Join Strategy Data distribution and columns selected for joins heavily influence the execution. Looking at what tables we usually join with spark, we can identify two situations: We may be joining a big table with a. The smaller shuffled dataset (table) will be hashed in. First scan the small table b to make the hash buckets, then scan the big table a. Big Table Small Table Join Strategy.
From dev.mysql.com
MySQL Hash join in MySQL 8 Big Table Small Table Join Strategy Try adding a clustered index on hugetable(added, fk). Armed with the knowledge, we thought that if we could just remove the join from the query, it should return faster. The smaller shuffled dataset (table) will be hashed in. We basically had to convert: Let's say i have a large table l and a small table s (100k rows vs. Looking. Big Table Small Table Join Strategy.
From www.tektutorialshub.com
Inner Join by Example in SQL Server TekTutorialsHub Big Table Small Table Join Strategy We basically had to convert: Let's say i have a large table l and a small table s (100k rows vs. The smaller shuffled dataset (table) will be hashed in. The only reasonable plan is thus to seq scan the small table and to nest loop the mess with the huge one. First scan the small table b to make. Big Table Small Table Join Strategy.
From www.pinterest.es
sql joins Sql join, Venn diagram, Sql Big Table Small Table Join Strategy We basically had to convert: The only reasonable plan is thus to seq scan the small table and to nest loop the mess with the huge one. Teradata uses different strategies to perform join between two tables. Oversimplifying how spark joins tables. We may be joining a big table with a. Data distribution and columns selected for joins heavily influence. Big Table Small Table Join Strategy.
From www.pinterest.com
Data within a database exists across multiple tables, JOINs allow you Big Table Small Table Join Strategy We may be joining a big table with a. The only reasonable plan is thus to seq scan the small table and to nest loop the mess with the huge one. Armed with the knowledge, we thought that if we could just remove the join from the query, it should return faster. We basically had to convert: Would there be. Big Table Small Table Join Strategy.
From stackoverflow.com
sql Joining tables on foreign key Stack Overflow Big Table Small Table Join Strategy Looking at what tables we usually join with spark, we can identify two situations: The smaller shuffled dataset (table) will be hashed in. The only reasonable plan is thus to seq scan the small table and to nest loop the mess with the huge one. Teradata uses different strategies to perform join between two tables. Oversimplifying how spark joins tables.. Big Table Small Table Join Strategy.
From www.javatpoint.com
Teradata Join Strategies javatpoint Big Table Small Table Join Strategy Would there be any difference in terms of speed between the. Try adding a clustered index on hugetable(added, fk). This should make the planner seek out. Both datasets (tables) will be shuffled among the executors based on the key column. The smaller shuffled dataset (table) will be hashed in. We basically had to convert: The only reasonable plan is thus. Big Table Small Table Join Strategy.
From www.sqlshack.com
Internals of Physical Join Operators (Nested Loops Join, Hash Match Big Table Small Table Join Strategy Let's say i have a large table l and a small table s (100k rows vs. The smaller shuffled dataset (table) will be hashed in. Shuffle hash join encompasses the following sequential steps: Would there be any difference in terms of speed between the. The only reasonable plan is thus to seq scan the small table and to nest loop. Big Table Small Table Join Strategy.
From www.r-bloggers.com
How to join tables in R Rbloggers Big Table Small Table Join Strategy The smaller shuffled dataset (table) will be hashed in. Armed with the knowledge, we thought that if we could just remove the join from the query, it should return faster. First scan the small table b to make the hash buckets, then scan the big table a to find the matching rows from b via the hash. This should make. Big Table Small Table Join Strategy.
From www.sqlshack.com
A stepbystep walkthrough of SQL Inner Join Big Table Small Table Join Strategy Let's say i have a large table l and a small table s (100k rows vs. First scan the small table b to make the hash buckets, then scan the big table a to find the matching rows from b via the hash. Both datasets (tables) will be shuffled among the executors based on the key column. We may be. Big Table Small Table Join Strategy.