Partition The Data In Spark . Simply put, partitions in spark are the smaller, manageable chunks of your big data. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In spark, data is distributed across. In this post, we’ll learn how to explicitly control partitioning in spark, deciding exactly where each row should go. It is an important tool for achieving optimal s3 storage or effectively… In pyspark, the partitionby() transformation is used to partition data in an rdd or dataframe based on the specified partitioner. Methods of data partitioning in pyspark. It is typically applied after certain. In this article, we will see different methods to perform data partition. In the context of apache spark, it can be defined as a. Choosing the right partitioning method is crucial and depends on factors such as numeric. Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data.
from blog.csdn.net
In this article, we will see different methods to perform data partition. Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. Methods of data partitioning in pyspark. It is an important tool for achieving optimal s3 storage or effectively… In pyspark, the partitionby() transformation is used to partition data in an rdd or dataframe based on the specified partitioner. Simply put, partitions in spark are the smaller, manageable chunks of your big data. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In spark, data is distributed across. In the context of apache spark, it can be defined as a. In this post, we’ll learn how to explicitly control partitioning in spark, deciding exactly where each row should go.
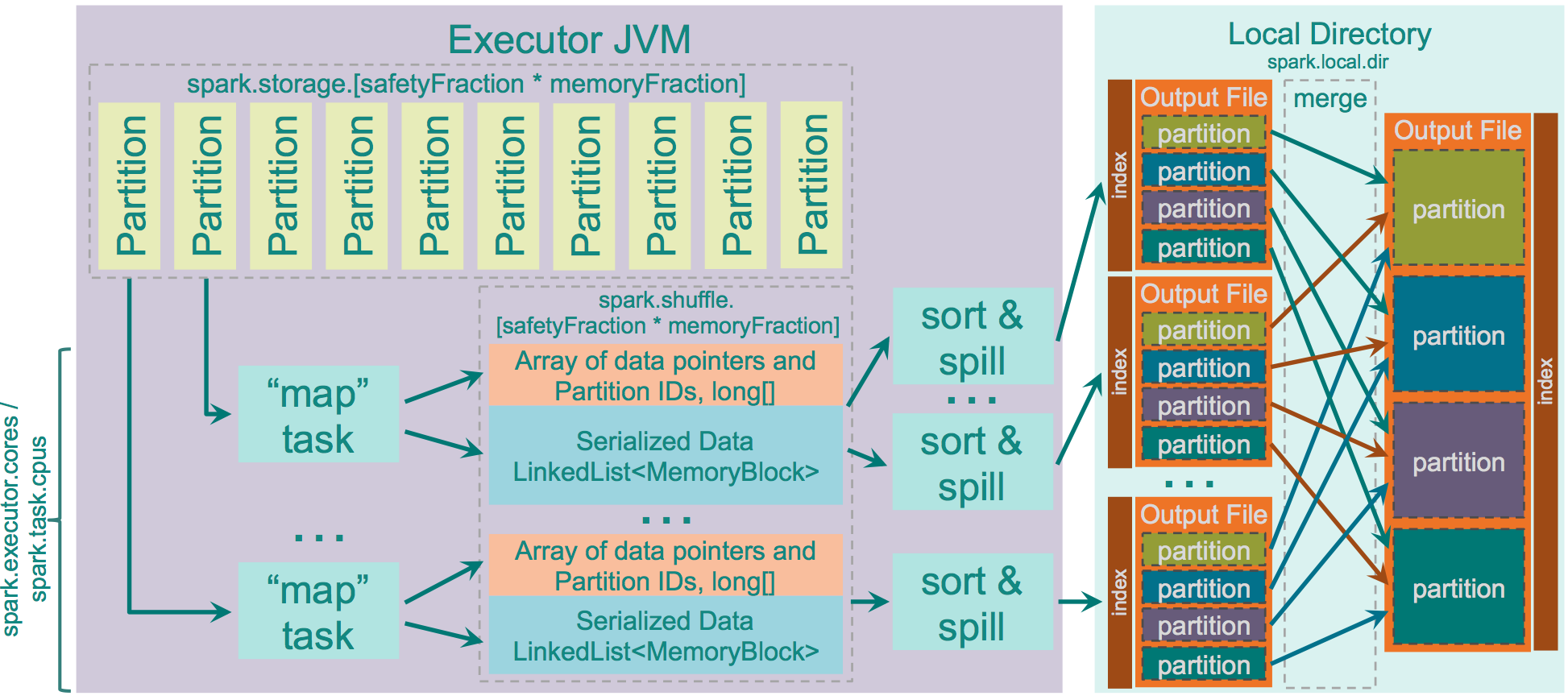
spark基本知识点之Shuffle_separate file for each media typeCSDN博客
Partition The Data In Spark Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. In this article, we will see different methods to perform data partition. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. In pyspark, the partitionby() transformation is used to partition data in an rdd or dataframe based on the specified partitioner. Methods of data partitioning in pyspark. In the context of apache spark, it can be defined as a. In spark, data is distributed across. Choosing the right partitioning method is crucial and depends on factors such as numeric. It is an important tool for achieving optimal s3 storage or effectively… Simply put, partitions in spark are the smaller, manageable chunks of your big data. It is typically applied after certain. In this post, we’ll learn how to explicitly control partitioning in spark, deciding exactly where each row should go.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Partition The Data In Spark It is an important tool for achieving optimal s3 storage or effectively… In pyspark, the partitionby() transformation is used to partition data in an rdd or dataframe based on the specified partitioner. In the context of apache spark, it can be defined as a. Methods of data partitioning in pyspark. Partitioning is the process of dividing a dataset into smaller,. Partition The Data In Spark.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Partition The Data In Spark It is an important tool for achieving optimal s3 storage or effectively… Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. In pyspark, the partitionby() transformation is used to partition data in an rdd or dataframe based on the specified partitioner. Methods of data partitioning in pyspark. Simply put, partitions in spark are the. Partition The Data In Spark.
From spaziocodice.com
Spark SQL Partitions and Sizes SpazioCodice Partition The Data In Spark It is typically applied after certain. In this article, we will see different methods to perform data partition. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Choosing the right partitioning method is. Partition The Data In Spark.
From www.youtube.com
How to find Data skewness in spark / How to get count of rows from each Partition The Data In Spark It is typically applied after certain. In spark, data is distributed across. Methods of data partitioning in pyspark. It is an important tool for achieving optimal s3 storage or effectively… In this article, we will see different methods to perform data partition. In this post, we’ll learn how to explicitly control partitioning in spark, deciding exactly where each row should. Partition The Data In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Partition The Data In Spark In the context of apache spark, it can be defined as a. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Simply put, partitions in spark are the smaller, manageable chunks of your big data. Partitioning is the process of dividing a dataset into smaller, more manageable chunks. Partition The Data In Spark.
From horicky.blogspot.com
Pragmatic Programming Techniques Big Data Processing in Spark Partition The Data In Spark It is an important tool for achieving optimal s3 storage or effectively… In pyspark, the partitionby() transformation is used to partition data in an rdd or dataframe based on the specified partitioner. Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. Simply put, partitions in spark are the smaller, manageable chunks of your big. Partition The Data In Spark.
From medium.com
Apache Spark — RDD…….A data structure of Spark by Berselin C R May Partition The Data In Spark In pyspark, the partitionby() transformation is used to partition data in an rdd or dataframe based on the specified partitioner. Simply put, partitions in spark are the smaller, manageable chunks of your big data. Methods of data partitioning in pyspark. It is an important tool for achieving optimal s3 storage or effectively… In this article, we will see different methods. Partition The Data In Spark.
From andr83.io
How to work with Hive tables with a lot of partitions from Spark Partition The Data In Spark In spark, data is distributed across. In pyspark, the partitionby() transformation is used to partition data in an rdd or dataframe based on the specified partitioner. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Simply put, partitions in spark are the smaller, manageable chunks of your big data. In this post, we’ll learn. Partition The Data In Spark.
From sparkbyexamples.com
Get the Size of Each Spark Partition Spark By {Examples} Partition The Data In Spark In spark, data is distributed across. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. In this article, we will see different methods to perform data partition. In a simple manner, partitioning in data engineering means splitting your data. Partition The Data In Spark.
From www.youtube.com
Why should we partition the data in spark? YouTube Partition The Data In Spark It is typically applied after certain. In this article, we will see different methods to perform data partition. In pyspark, the partitionby() transformation is used to partition data in an rdd or dataframe based on the specified partitioner. Methods of data partitioning in pyspark. In spark, data is distributed across. In this post, we’ll learn how to explicitly control partitioning. Partition The Data In Spark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Partition The Data In Spark It is typically applied after certain. Simply put, partitions in spark are the smaller, manageable chunks of your big data. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. Partitioning in spark improves. Partition The Data In Spark.
From dzone.com
Dynamic Partition Pruning in Spark 3.0 DZone Partition The Data In Spark Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Simply put, partitions in spark are the smaller, manageable chunks of your big data. In spark, data is distributed across. In pyspark, the partitionby(). Partition The Data In Spark.
From www.researchgate.net
(PDF) Spark as Data Supplier for MPI Deep Learning Processes Partition The Data In Spark Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. In this post, we’ll learn how to explicitly control partitioning in spark, deciding exactly where each row should go. In this article, we will see different methods to perform data partition. Choosing the right partitioning method is crucial and depends on factors such as numeric.. Partition The Data In Spark.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders Partition The Data In Spark It is an important tool for achieving optimal s3 storage or effectively… It is typically applied after certain. Simply put, partitions in spark are the smaller, manageable chunks of your big data. In the context of apache spark, it can be defined as a. Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. In. Partition The Data In Spark.
From www.projectpro.io
How Data Partitioning in Spark helps achieve more parallelism? Partition The Data In Spark In pyspark, the partitionby() transformation is used to partition data in an rdd or dataframe based on the specified partitioner. Simply put, partitions in spark are the smaller, manageable chunks of your big data. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Choosing the right partitioning method. Partition The Data In Spark.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Partition The Data In Spark In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In spark, data is distributed across. In the context of apache spark, it can be defined as a. In pyspark, the partitionby() transformation is used to partition data in an rdd or dataframe based on the specified partitioner. In. Partition The Data In Spark.
From www.youtube.com
How to partition and write DataFrame in Spark without deleting Partition The Data In Spark Simply put, partitions in spark are the smaller, manageable chunks of your big data. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. In the context of apache spark, it can be defined. Partition The Data In Spark.
From blog.csdn.net
spark基本知识点之Shuffle_separate file for each media typeCSDN博客 Partition The Data In Spark Choosing the right partitioning method is crucial and depends on factors such as numeric. In pyspark, the partitionby() transformation is used to partition data in an rdd or dataframe based on the specified partitioner. It is an important tool for achieving optimal s3 storage or effectively… In this article, we will see different methods to perform data partition. In this. Partition The Data In Spark.
From blog.knoldus.com
PartitionAware Data Loading in Spark SQL Knoldus Blogs Partition The Data In Spark It is an important tool for achieving optimal s3 storage or effectively… In the context of apache spark, it can be defined as a. Simply put, partitions in spark are the smaller, manageable chunks of your big data. In this article, we will see different methods to perform data partition. It is typically applied after certain. In spark, data is. Partition The Data In Spark.
From morioh.com
Data Partition on Spark in too The Download Data On Columnstore Item Partition The Data In Spark Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In spark, data is distributed across. It is an important tool for achieving optimal s3 storage or effectively… In this post, we’ll learn how. Partition The Data In Spark.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient Partition The Data In Spark In this article, we will see different methods to perform data partition. In spark, data is distributed across. In this post, we’ll learn how to explicitly control partitioning in spark, deciding exactly where each row should go. It is typically applied after certain. Simply put, partitions in spark are the smaller, manageable chunks of your big data. Methods of data. Partition The Data In Spark.
From towardsdatascience.com
The art of joining in Spark. Practical tips to speedup joins in… by Partition The Data In Spark Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. It is an important tool for achieving optimal s3 storage or effectively… Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Choosing the right partitioning method is crucial and depends on factors such as numeric. In a simple manner,. Partition The Data In Spark.
From www.youtube.com
Spark Application Partition By in Spark Chapter 2 LearntoSpark Partition The Data In Spark It is typically applied after certain. It is an important tool for achieving optimal s3 storage or effectively… Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. In pyspark, the partitionby() transformation is used to partition data in an rdd or dataframe based on the specified partitioner. In spark, data is distributed across. Choosing. Partition The Data In Spark.
From medium.com
Managing Spark Partitions. How data is partitioned and when do you Partition The Data In Spark In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In this article, we will see different methods to perform data partition. Simply put, partitions in spark are the smaller, manageable chunks of your big data. It is an important tool for achieving optimal s3 storage or effectively… Methods. Partition The Data In Spark.
From www.ishandeshpande.com
Understanding Partitions in Apache Spark Partition The Data In Spark It is an important tool for achieving optimal s3 storage or effectively… In spark, data is distributed across. Choosing the right partitioning method is crucial and depends on factors such as numeric. In this post, we’ll learn how to explicitly control partitioning in spark, deciding exactly where each row should go. Partitioning is the process of dividing a dataset into. Partition The Data In Spark.
From www.jowanza.com
Partitions in Apache Spark — Jowanza Joseph Partition The Data In Spark It is typically applied after certain. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. It is an important tool for achieving optimal s3 storage or effectively… Choosing the right partitioning method is crucial and depends on factors such as numeric. Partitioning in spark improves performance by reducing. Partition The Data In Spark.
From www.simplilearn.com
Spark Parallel Processing Tutorial Simplilearn Partition The Data In Spark Choosing the right partitioning method is crucial and depends on factors such as numeric. Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. In the context of apache spark, it can be defined as a. Methods of data partitioning in pyspark. In this article, we will see different methods to perform data partition. In. Partition The Data In Spark.
From discover.qubole.com
Introducing Dynamic Partition Pruning Optimization for Spark Partition The Data In Spark Simply put, partitions in spark are the smaller, manageable chunks of your big data. It is an important tool for achieving optimal s3 storage or effectively… Methods of data partitioning in pyspark. Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. In spark, data is distributed across. Partitioning in spark improves performance by reducing. Partition The Data In Spark.
From medium.com
Dynamic Partition Pruning. Query performance optimization in Spark Partition The Data In Spark In this article, we will see different methods to perform data partition. In the context of apache spark, it can be defined as a. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. It is typically applied after certain.. Partition The Data In Spark.
From medium.com
Managing Spark Partitions. How data is partitioned and when do you Partition The Data In Spark Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Choosing the right partitioning method is crucial and depends on factors such as numeric. In the context of apache spark, it can be defined as a. Methods of data partitioning in pyspark. In pyspark, the partitionby() transformation is used to partition data in an rdd. Partition The Data In Spark.
From sparkbyexamples.com
Spark Partitioning & Partition Understanding Spark By {Examples} Partition The Data In Spark It is an important tool for achieving optimal s3 storage or effectively… Partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. In a simple manner, partitioning in data engineering means splitting your data in smaller chunks based on a well defined criteria. In spark, data is distributed across. In this post, we’ll learn how. Partition The Data In Spark.
From www.researchgate.net
Spark partition an LMDB Database Download Scientific Diagram Partition The Data In Spark Simply put, partitions in spark are the smaller, manageable chunks of your big data. It is an important tool for achieving optimal s3 storage or effectively… It is typically applied after certain. Choosing the right partitioning method is crucial and depends on factors such as numeric. Methods of data partitioning in pyspark. In the context of apache spark, it can. Partition The Data In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Partition The Data In Spark In this post, we’ll learn how to explicitly control partitioning in spark, deciding exactly where each row should go. In the context of apache spark, it can be defined as a. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. In a simple manner, partitioning in data engineering means splitting your data in smaller. Partition The Data In Spark.
From www.cloudduggu.com
Apache Spark Transformations & Actions Tutorial CloudDuggu Partition The Data In Spark Methods of data partitioning in pyspark. It is typically applied after certain. In spark, data is distributed across. Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. Simply put, partitions in spark are the smaller, manageable chunks of your big data. In the context of apache spark, it can be defined as a. Choosing. Partition The Data In Spark.
From www.youtube.com
Apache Spark Data Partitioning Example YouTube Partition The Data In Spark Partitioning in spark improves performance by reducing data shuffle and providing fast access to data. In the context of apache spark, it can be defined as a. It is typically applied after certain. In this article, we will see different methods to perform data partition. In spark, data is distributed across. In a simple manner, partitioning in data engineering means. Partition The Data In Spark.