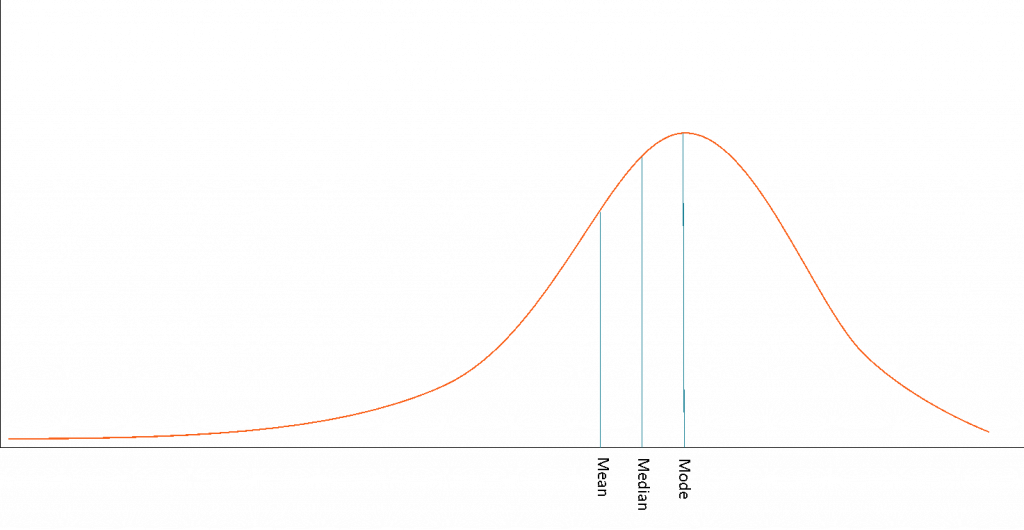
How To Bin Skewed Data . The regular techniques like equal width and equal frequency binning do not work. We usually do binning for numerical data, which means data that is made up of numbers. It can be easily done via numpy , just by calling the log() function on the desired column. Imagine trying to understand a big pile of legos without sorting them first. So the data is clearly quite heavily positively skewed. Binning simplifies the data by dividing it into a few meaningful categories. How would a skewed variable impact a classification problem (logistic regression, tree model)? Log transformation is most likely the first thing you should do to remove skewness from the predictor. In the world of data science, we call this process of sorting and grouping data into different “bins” or “buckets” as ‘binning’. Here are some types of binning with its explanation: If a bin has very few data points. You can then just as easily check for skew: We will discuss three basic types of binning:. Is it justified to bin the skewed variable. Why is binning important in data science?
from www.ztable.net
Close to 20% are either 0 or 1, with the maximum being nearly 18500. Why is binning important in data science? Imagine trying to understand a big pile of legos without sorting them first. You can then just as easily check for skew: Is it justified to bin the skewed variable. We will discuss three basic types of binning:. How would a skewed variable impact a classification problem (logistic regression, tree model)? In the world of data science, we call this process of sorting and grouping data into different “bins” or “buckets” as ‘binning’. Here are some types of binning with its explanation: Binning simplifies the data by dividing it into a few meaningful categories.
Skewed Distribution Z TABLE
How To Bin Skewed Data Imagine trying to understand a big pile of legos without sorting them first. Binning simplifies the data by dividing it into a few meaningful categories. You can then just as easily check for skew: In the world of data science, we call this process of sorting and grouping data into different “bins” or “buckets” as ‘binning’. We will discuss three basic types of binning:. Here are some types of binning with its explanation: If a bin has very few data points. Close to 20% are either 0 or 1, with the maximum being nearly 18500. Is it justified to bin the skewed variable. Why is binning important in data science? Data binning can create histograms and frequency distributions that reveal anomalies and outliers. Imagine trying to understand a big pile of legos without sorting them first. So the data is clearly quite heavily positively skewed. Log transformation is most likely the first thing you should do to remove skewness from the predictor. How would a skewed variable impact a classification problem (logistic regression, tree model)? It can be easily done via numpy , just by calling the log() function on the desired column.
From www.geeksforgeeks.org
Skewness in Statistics Formula, Examples, and FAQs How To Bin Skewed Data Close to 20% are either 0 or 1, with the maximum being nearly 18500. Binning simplifies the data by dividing it into a few meaningful categories. Is it justified to bin the skewed variable. Why is binning important in data science? Imagine trying to understand a big pile of legos without sorting them first. We will discuss three basic types. How To Bin Skewed Data.
From statacumen.com
8.3 Skewed Left Distributions Passion Driven Statistics How To Bin Skewed Data We will discuss three basic types of binning:. Close to 20% are either 0 or 1, with the maximum being nearly 18500. We usually do binning for numerical data, which means data that is made up of numbers. How would a skewed variable impact a classification problem (logistic regression, tree model)? Data binning can create histograms and frequency distributions that. How To Bin Skewed Data.
From www.youtube.com
Normal Probability Plots of Left and RightSkewed Data YouTube How To Bin Skewed Data It can be easily done via numpy , just by calling the log() function on the desired column. Log transformation is most likely the first thing you should do to remove skewness from the predictor. Why is binning important in data science? Close to 20% are either 0 or 1, with the maximum being nearly 18500. So the data is. How To Bin Skewed Data.
From www.ztable.net
Skewed Distribution Z TABLE How To Bin Skewed Data You can then just as easily check for skew: Data binning can create histograms and frequency distributions that reveal anomalies and outliers. We will discuss three basic types of binning:. Is it justified to bin the skewed variable. How would a skewed variable impact a classification problem (logistic regression, tree model)? It can be easily done via numpy , just. How To Bin Skewed Data.
From studiousguy.com
10 Skewed Distribution Examples in Real Life StudiousGuy How To Bin Skewed Data It can be easily done via numpy , just by calling the log() function on the desired column. Is it justified to bin the skewed variable. Close to 20% are either 0 or 1, with the maximum being nearly 18500. Log transformation is most likely the first thing you should do to remove skewness from the predictor. We will discuss. How To Bin Skewed Data.
From mavink.com
Skewed Bar Graph How To Bin Skewed Data The regular techniques like equal width and equal frequency binning do not work. How would a skewed variable impact a classification problem (logistic regression, tree model)? Binning simplifies the data by dividing it into a few meaningful categories. Here are some types of binning with its explanation: Is it justified to bin the skewed variable. You can then just as. How To Bin Skewed Data.
From anatomisebiostats.com
Transforming Skewed Data How to choose the right transformation for How To Bin Skewed Data Imagine trying to understand a big pile of legos without sorting them first. You can then just as easily check for skew: Binning simplifies the data by dividing it into a few meaningful categories. Data binning can create histograms and frequency distributions that reveal anomalies and outliers. Why is binning important in data science? So the data is clearly quite. How To Bin Skewed Data.
From www.scribbr.com
Skewness Definition, Examples & Formula How To Bin Skewed Data How would a skewed variable impact a classification problem (logistic regression, tree model)? Here are some types of binning with its explanation: If a bin has very few data points. Binning simplifies the data by dividing it into a few meaningful categories. Imagine trying to understand a big pile of legos without sorting them first. We will discuss three basic. How To Bin Skewed Data.
From mode.com
How to Demystify Skewed Data and Deliver Analysis Mode How To Bin Skewed Data Binning simplifies the data by dividing it into a few meaningful categories. You can then just as easily check for skew: Data binning can create histograms and frequency distributions that reveal anomalies and outliers. If a bin has very few data points. The regular techniques like equal width and equal frequency binning do not work. We usually do binning for. How To Bin Skewed Data.
From www.youtube.com
Example Skewed Histograms YouTube How To Bin Skewed Data In the world of data science, we call this process of sorting and grouping data into different “bins” or “buckets” as ‘binning’. If a bin has very few data points. So the data is clearly quite heavily positively skewed. Why is binning important in data science? Is it justified to bin the skewed variable. Log transformation is most likely the. How To Bin Skewed Data.
From runestone.academy
Outliers and Skew — Introduction to Google Sheets and SQL How To Bin Skewed Data Data binning can create histograms and frequency distributions that reveal anomalies and outliers. Here are some types of binning with its explanation: It can be easily done via numpy , just by calling the log() function on the desired column. Is it justified to bin the skewed variable. Why is binning important in data science? Close to 20% are either. How To Bin Skewed Data.
From www.geeksforgeeks.org
Skewness in Statistics Formula, Examples, and FAQs How To Bin Skewed Data You can then just as easily check for skew: In the world of data science, we call this process of sorting and grouping data into different “bins” or “buckets” as ‘binning’. How would a skewed variable impact a classification problem (logistic regression, tree model)? Data binning can create histograms and frequency distributions that reveal anomalies and outliers. So the data. How To Bin Skewed Data.
From marcosammon.com
Skewness and Expected Returns How To Bin Skewed Data Here are some types of binning with its explanation: We will discuss three basic types of binning:. So the data is clearly quite heavily positively skewed. We usually do binning for numerical data, which means data that is made up of numbers. In the world of data science, we call this process of sorting and grouping data into different “bins”. How To Bin Skewed Data.
From www.youtube.com
How to Deal with Skewed Data YouTube How To Bin Skewed Data Why is binning important in data science? Here are some types of binning with its explanation: You can then just as easily check for skew: Binning simplifies the data by dividing it into a few meaningful categories. If a bin has very few data points. How would a skewed variable impact a classification problem (logistic regression, tree model)? We will. How To Bin Skewed Data.
From www.sophia.org
Representing Skewed Data on a Graph Tutorial Sophia Learning How To Bin Skewed Data Close to 20% are either 0 or 1, with the maximum being nearly 18500. Is it justified to bin the skewed variable. The regular techniques like equal width and equal frequency binning do not work. Here are some types of binning with its explanation: We usually do binning for numerical data, which means data that is made up of numbers.. How To Bin Skewed Data.
From www.youtube.com
Symmetric vs Skewed Distribution YouTube How To Bin Skewed Data Imagine trying to understand a big pile of legos without sorting them first. Is it justified to bin the skewed variable. You can then just as easily check for skew: Here are some types of binning with its explanation: It can be easily done via numpy , just by calling the log() function on the desired column. We usually do. How To Bin Skewed Data.
From mathslinks.net
Skewed Data MathsLinks How To Bin Skewed Data Data binning can create histograms and frequency distributions that reveal anomalies and outliers. Here are some types of binning with its explanation: It can be easily done via numpy , just by calling the log() function on the desired column. Log transformation is most likely the first thing you should do to remove skewness from the predictor. In the world. How To Bin Skewed Data.
From www.youtube.com
Skewed Data & Outliers YouTube How To Bin Skewed Data We will discuss three basic types of binning:. So the data is clearly quite heavily positively skewed. How would a skewed variable impact a classification problem (logistic regression, tree model)? Close to 20% are either 0 or 1, with the maximum being nearly 18500. Imagine trying to understand a big pile of legos without sorting them first. We usually do. How To Bin Skewed Data.
From www.youtube.com
Transforming a left skewed distribution using natural log and square How To Bin Skewed Data Imagine trying to understand a big pile of legos without sorting them first. Log transformation is most likely the first thing you should do to remove skewness from the predictor. You can then just as easily check for skew: So the data is clearly quite heavily positively skewed. Binning simplifies the data by dividing it into a few meaningful categories.. How To Bin Skewed Data.
From www.ztable.net
Skewed Distribution Z TABLE How To Bin Skewed Data Here are some types of binning with its explanation: We usually do binning for numerical data, which means data that is made up of numbers. Log transformation is most likely the first thing you should do to remove skewness from the predictor. Data binning can create histograms and frequency distributions that reveal anomalies and outliers. You can then just as. How To Bin Skewed Data.
From www.statology.org
5 Examples of Positively Skewed Distributions How To Bin Skewed Data Imagine trying to understand a big pile of legos without sorting them first. You can then just as easily check for skew: It can be easily done via numpy , just by calling the log() function on the desired column. We usually do binning for numerical data, which means data that is made up of numbers. If a bin has. How To Bin Skewed Data.
From www.investopedia.com
Skewness Definition, Formula, & Calculation How To Bin Skewed Data So the data is clearly quite heavily positively skewed. If a bin has very few data points. We will discuss three basic types of binning:. Is it justified to bin the skewed variable. Log transformation is most likely the first thing you should do to remove skewness from the predictor. You can then just as easily check for skew: How. How To Bin Skewed Data.
From www.newtraderu.com
Skewed Distribution Explained New Trader U How To Bin Skewed Data It can be easily done via numpy , just by calling the log() function on the desired column. We will discuss three basic types of binning:. Why is binning important in data science? How would a skewed variable impact a classification problem (logistic regression, tree model)? Close to 20% are either 0 or 1, with the maximum being nearly 18500.. How To Bin Skewed Data.
From browns.norushcharge.com
How to Identify Skewness in Box Plots Statology How To Bin Skewed Data It can be easily done via numpy , just by calling the log() function on the desired column. Imagine trying to understand a big pile of legos without sorting them first. The regular techniques like equal width and equal frequency binning do not work. How would a skewed variable impact a classification problem (logistic regression, tree model)? Is it justified. How To Bin Skewed Data.
From www.youtube.com
Skewed Data & Outliers YouTube How To Bin Skewed Data Close to 20% are either 0 or 1, with the maximum being nearly 18500. Imagine trying to understand a big pile of legos without sorting them first. You can then just as easily check for skew: The regular techniques like equal width and equal frequency binning do not work. If a bin has very few data points. So the data. How To Bin Skewed Data.
From studiousguy.com
10 Skewed Distribution Examples in Real Life StudiousGuy How To Bin Skewed Data In the world of data science, we call this process of sorting and grouping data into different “bins” or “buckets” as ‘binning’. We will discuss three basic types of binning:. So the data is clearly quite heavily positively skewed. Is it justified to bin the skewed variable. It can be easily done via numpy , just by calling the log(). How To Bin Skewed Data.
From www.statology.org
Left Skewed Histogram Examples and Interpretation How To Bin Skewed Data So the data is clearly quite heavily positively skewed. Imagine trying to understand a big pile of legos without sorting them first. Why is binning important in data science? If a bin has very few data points. Data binning can create histograms and frequency distributions that reveal anomalies and outliers. You can then just as easily check for skew: The. How To Bin Skewed Data.
From mavink.com
Skewed Histogram How To Bin Skewed Data We usually do binning for numerical data, which means data that is made up of numbers. Here are some types of binning with its explanation: Imagine trying to understand a big pile of legos without sorting them first. Binning simplifies the data by dividing it into a few meaningful categories. Close to 20% are either 0 or 1, with the. How To Bin Skewed Data.
From www.vrogue.co
How To Identify Skewness In Box Plots Statology vrogue.co How To Bin Skewed Data If a bin has very few data points. So the data is clearly quite heavily positively skewed. Log transformation is most likely the first thing you should do to remove skewness from the predictor. How would a skewed variable impact a classification problem (logistic regression, tree model)? Why is binning important in data science? In the world of data science,. How To Bin Skewed Data.
From studiousguy.com
10 Skewed Distribution Examples in Real Life StudiousGuy How To Bin Skewed Data Is it justified to bin the skewed variable. If a bin has very few data points. You can then just as easily check for skew: The regular techniques like equal width and equal frequency binning do not work. Binning simplifies the data by dividing it into a few meaningful categories. In the world of data science, we call this process. How To Bin Skewed Data.
From www.youtube.com
How to calculate zscores and determine if a data set is skewed YouTube How To Bin Skewed Data So the data is clearly quite heavily positively skewed. It can be easily done via numpy , just by calling the log() function on the desired column. Imagine trying to understand a big pile of legos without sorting them first. Log transformation is most likely the first thing you should do to remove skewness from the predictor. In the world. How To Bin Skewed Data.
From ar.inspiredpencil.com
Examples Of Skewed Data How To Bin Skewed Data We will discuss three basic types of binning:. You can then just as easily check for skew: So the data is clearly quite heavily positively skewed. It can be easily done via numpy , just by calling the log() function on the desired column. If a bin has very few data points. Is it justified to bin the skewed variable.. How To Bin Skewed Data.
From www.amathsdictionaryforkids.com
skewed data A Maths Dictionary for Kids Quick Reference by Jenny Eather How To Bin Skewed Data We usually do binning for numerical data, which means data that is made up of numbers. Here are some types of binning with its explanation: How would a skewed variable impact a classification problem (logistic regression, tree model)? Why is binning important in data science? The regular techniques like equal width and equal frequency binning do not work. Close to. How To Bin Skewed Data.
From medium.com
Handling skewed data during your data analysis by Abhinay Ratakonda How To Bin Skewed Data Log transformation is most likely the first thing you should do to remove skewness from the predictor. If a bin has very few data points. Binning simplifies the data by dividing it into a few meaningful categories. In the world of data science, we call this process of sorting and grouping data into different “bins” or “buckets” as ‘binning’. Here. How To Bin Skewed Data.
From www.statology.org
Right Skewed Histogram Examples and Interpretation How To Bin Skewed Data Log transformation is most likely the first thing you should do to remove skewness from the predictor. Why is binning important in data science? Close to 20% are either 0 or 1, with the maximum being nearly 18500. So the data is clearly quite heavily positively skewed. Imagine trying to understand a big pile of legos without sorting them first.. How To Bin Skewed Data.