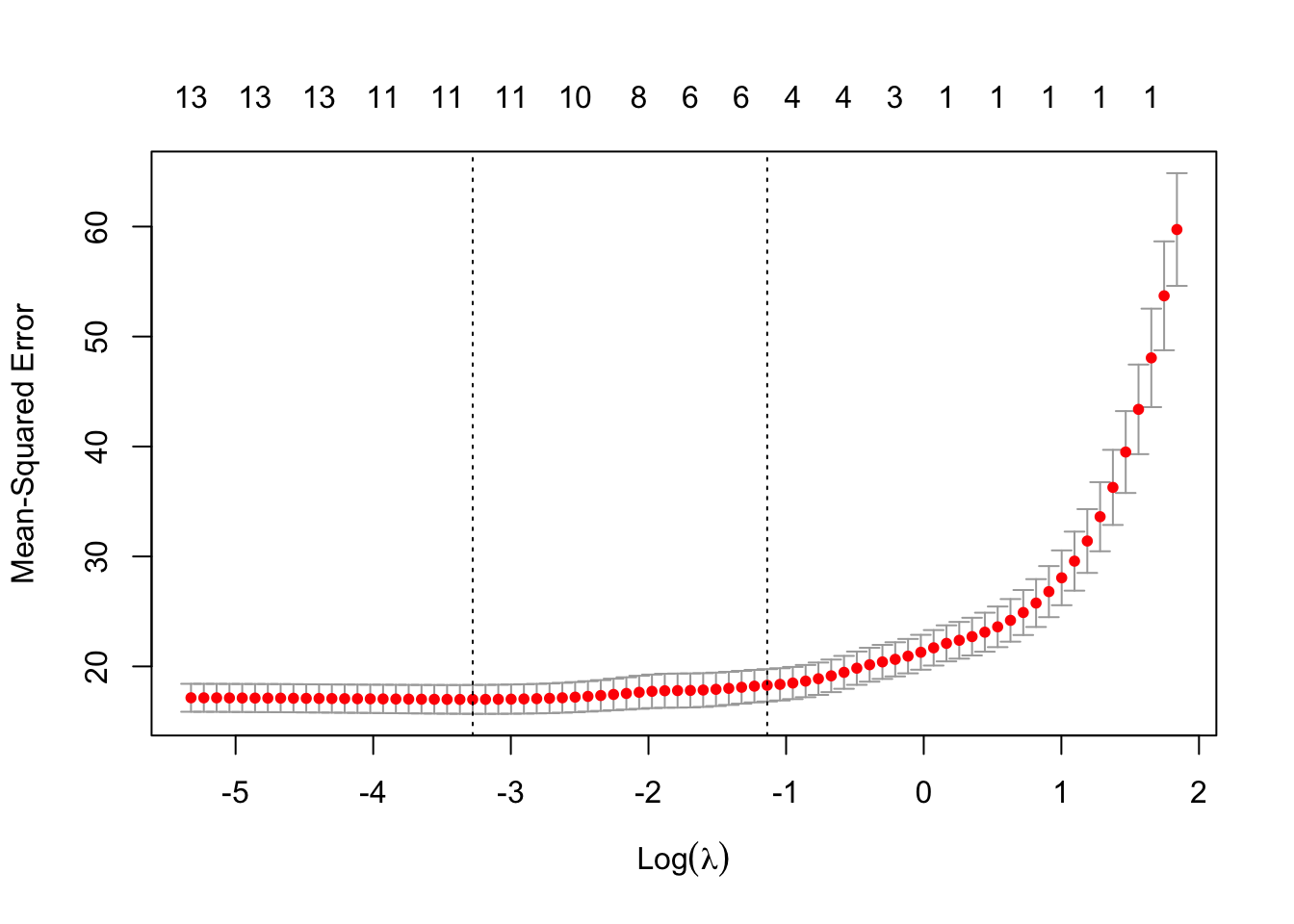
Lasso Regression Lambda Range . In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). This value is often chosen via cross. While both ridge regression and the lasso shrink the model parameters (b α, α = 1,., m) towards zero: The lm.ridge() function in the mass library can perform the ridge regression. To get the lasso estimates we have to minimise: The lambda (λ) value(s) must be. In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. Lasso parameters reach zero at different. Lasso (least absolute shrinkage and selection operator), similar to ridge.
from bookdown.org
The lambda (λ) value(s) must be. This value is often chosen via cross. In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). Lasso parameters reach zero at different. In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. Lasso (least absolute shrinkage and selection operator), similar to ridge. The lm.ridge() function in the mass library can perform the ridge regression. In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. To get the lasso estimates we have to minimise: While both ridge regression and the lasso shrink the model parameters (b α, α = 1,., m) towards zero:
4 Lasso Regression Machine Learning for Biostatistics
Lasso Regression Lambda Range Lasso parameters reach zero at different. The lm.ridge() function in the mass library can perform the ridge regression. In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. While both ridge regression and the lasso shrink the model parameters (b α, α = 1,., m) towards zero: Lasso (least absolute shrinkage and selection operator), similar to ridge. In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). Lasso parameters reach zero at different. In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. To get the lasso estimates we have to minimise: This value is often chosen via cross. The lambda (λ) value(s) must be.
From www.researchgate.net
Selection of the optimal lambda value for the enhanced LASSO model Lasso Regression Lambda Range The lambda (λ) value(s) must be. Lasso parameters reach zero at different. In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. In lasso regression, we select a. Lasso Regression Lambda Range.
From www.researchgate.net
Screening of clinical indicator variables using the LASSO regression Lasso Regression Lambda Range To get the lasso estimates we have to minimise: In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. The lm.ridge() function in the mass library can perform the ridge regression. The lambda (λ) value(s) must be. Lasso parameters reach zero at different. In lasso regression, we select a value for λ. Lasso Regression Lambda Range.
From dataaspirant.com
How Lasso Regression Works in Machine Learning Dataaspirant Lasso Regression Lambda Range Lasso (least absolute shrinkage and selection operator), similar to ridge. Lasso parameters reach zero at different. To get the lasso estimates we have to minimise: The lm.ridge() function in the mass library can perform the ridge regression. While both ridge regression and the lasso shrink the model parameters (b α, α = 1,., m) towards zero: In lasso regression, we. Lasso Regression Lambda Range.
From bookdown.org
Chapter 5 Choosing \(\lambda\) Machine Learning Lasso Regression Lambda Range This value is often chosen via cross. The lambda (λ) value(s) must be. To get the lasso estimates we have to minimise: The lm.ridge() function in the mass library can perform the ridge regression. In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). In lasso regression, the hyperparameter lambda (λ),. Lasso Regression Lambda Range.
From www.r-bloggers.com
lambda.min, lambda.1se and Cross Validation in Lasso Continuous Lasso Regression Lambda Range In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. While both ridge regression and the lasso shrink the model parameters (b α, α = 1,., m) towards zero: The lm.ridge() function in the mass library can perform the ridge regression. Lasso parameters reach zero at different. This value is often chosen. Lasso Regression Lambda Range.
From www.researchgate.net
Lasso regression, modeling results, and CV search for the best lambda Lasso Regression Lambda Range The lm.ridge() function in the mass library can perform the ridge regression. To get the lasso estimates we have to minimise: In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. While both ridge regression and the lasso shrink the model parameters (b α, α = 1,., m) towards zero: This value. Lasso Regression Lambda Range.
From rforhr.com
Chapter 54 Supervised Statistical Learning Using Lasso Regression R Lasso Regression Lambda Range The lambda (λ) value(s) must be. In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. This value is often chosen via cross. Lasso (least absolute shrinkage and selection operator), similar to ridge.. Lasso Regression Lambda Range.
From bookdown.org
4 Lasso Regression Machine Learning for Biostatistics Lasso Regression Lambda Range To get the lasso estimates we have to minimise: In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). Lasso (least absolute shrinkage and selection operator), similar to ridge. In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the. Lasso Regression Lambda Range.
From bradleyboehmke.github.io
Chapter 6 Regularized Regression HandsOn Machine Learning with R Lasso Regression Lambda Range Lasso (least absolute shrinkage and selection operator), similar to ridge. In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. The lm.ridge() function in the mass library can. Lasso Regression Lambda Range.
From www.researchgate.net
LASSO regression results. (A) When the lambda = 0.000394, the model Lasso Regression Lambda Range In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. Lasso parameters reach zero at different. The lambda (λ) value(s) must be. The lm.ridge() function in the mass library can perform the ridge regression. While both ridge regression and the lasso shrink the model parameters (b. Lasso Regression Lambda Range.
From medium.com
LASSO Regression In Detail (L1 Regularization) by Aarthi Kasirajan Lasso Regression Lambda Range This value is often chosen via cross. In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. While both ridge regression and the lasso shrink the model parameters (b α, α = 1,., m) towards zero: In lasso regression, we select a value for λ that. Lasso Regression Lambda Range.
From www.researchgate.net
Six genes identified by LASSO regression. (a) The path of the Lasso Regression Lambda Range To get the lasso estimates we have to minimise: In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. Lasso parameters reach zero at different. In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). The lambda (λ) value(s) must be. While both. Lasso Regression Lambda Range.
From www.researchgate.net
Predictor selection using LASSO regression analysis with 10fold Lasso Regression Lambda Range Lasso (least absolute shrinkage and selection operator), similar to ridge. The lambda (λ) value(s) must be. Lasso parameters reach zero at different. This value is often chosen via cross. The lm.ridge() function in the mass library can perform the ridge regression. In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and. Lasso Regression Lambda Range.
From www.researchgate.net
LASSOcox regression analysis. Coefficient distribution diagram (A Lasso Regression Lambda Range The lambda (λ) value(s) must be. Lasso (least absolute shrinkage and selection operator), similar to ridge. The lm.ridge() function in the mass library can perform the ridge regression. Lasso parameters reach zero at different. In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). In lasso or ridge regression, one has. Lasso Regression Lambda Range.
From www.researchgate.net
Clinical feature selection using the LASSO regression analysis with Lasso Regression Lambda Range While both ridge regression and the lasso shrink the model parameters (b α, α = 1,., m) towards zero: In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. This value is often chosen via cross. The lm.ridge() function in the mass library can perform the ridge regression. Lasso parameters reach zero. Lasso Regression Lambda Range.
From www.researchgate.net
Feature selection. (a) Parameter tuning of the lambda in the LASSO Lasso Regression Lambda Range In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. The lm.ridge() function in the mass library can perform the ridge regression. While both ridge regression and the. Lasso Regression Lambda Range.
From www.statology.org
Lasso Regression in R (StepbyStep) Lasso Regression Lambda Range To get the lasso estimates we have to minimise: In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. Lasso parameters reach zero at different. The lm.ridge() function. Lasso Regression Lambda Range.
From www.researchgate.net
Variable screening using the Lasso regression model. (A) Nine variables Lasso Regression Lambda Range This value is often chosen via cross. The lambda (λ) value(s) must be. In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. Lasso parameters reach zero at different. Lasso (least absolute shrinkage and selection operator), similar to ridge. In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty,. Lasso Regression Lambda Range.
From www.researchgate.net
LASSO regression model. (A) LASSO coefficient profiles of the 76 Lasso Regression Lambda Range In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). Lasso parameters reach zero at different. The lm.ridge() function in the mass library can perform the ridge regression. This value is often chosen. Lasso Regression Lambda Range.
From bradleyboehmke.github.io
Chapter 6 Regularized Regression HandsOn Machine Learning with R Lasso Regression Lambda Range In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). The lm.ridge() function in the mass library can perform the ridge regression. Lasso (least absolute shrinkage and selection operator), similar to ridge. Lasso parameters reach zero at different. To get the lasso estimates we have to minimise: While both ridge regression. Lasso Regression Lambda Range.
From www.researchgate.net
LASSO regression results. (A) When the lambda = 0.000394, the model Lasso Regression Lambda Range Lasso (least absolute shrinkage and selection operator), similar to ridge. This value is often chosen via cross. The lambda (λ) value(s) must be. To get the lasso estimates we have to minimise: The lm.ridge() function in the mass library can perform the ridge regression. While both ridge regression and the lasso shrink the model parameters (b α, α = 1,.,. Lasso Regression Lambda Range.
From www.researchgate.net
(A) Optimal lambda value was selected in the LASSO regression model Lasso Regression Lambda Range The lambda (λ) value(s) must be. The lm.ridge() function in the mass library can perform the ridge regression. Lasso (least absolute shrinkage and selection operator), similar to ridge. In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). While both ridge regression and the lasso shrink the model parameters (b α,. Lasso Regression Lambda Range.
From www.researchgate.net
LASSO regression analysis. (A) Coefficients of selected... Download Lasso Regression Lambda Range To get the lasso estimates we have to minimise: The lambda (λ) value(s) must be. Lasso parameters reach zero at different. In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). This value is often chosen via cross. The lm.ridge() function in the mass library can perform the ridge regression. Lasso. Lasso Regression Lambda Range.
From www.researchgate.net
LASSO regression coefficients and area under the receiver operating Lasso Regression Lambda Range In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. To get the lasso estimates we have to minimise: Lasso (least absolute shrinkage and selection operator), similar to ridge. The lm.ridge() function in the mass library can perform the ridge regression. In lasso regression, we select. Lasso Regression Lambda Range.
From ucanalytics.com
Graph 2 Regression with Regularization (Lasso and Guessed Lambda Lasso Regression Lambda Range The lm.ridge() function in the mass library can perform the ridge regression. While both ridge regression and the lasso shrink the model parameters (b α, α = 1,., m) towards zero: This value is often chosen via cross. Lasso parameters reach zero at different. In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff. Lasso Regression Lambda Range.
From www.researchgate.net
Lasso regression model select candidate EMTrelated prognosis genes Lasso Regression Lambda Range The lambda (λ) value(s) must be. While both ridge regression and the lasso shrink the model parameters (b α, α = 1,., m) towards zero: The lm.ridge() function in the mass library can perform the ridge regression. Lasso (least absolute shrinkage and selection operator), similar to ridge. This value is often chosen via cross. In lasso regression, the hyperparameter lambda. Lasso Regression Lambda Range.
From www.researchgate.net
Variables selection using the LASSO regression analysis with 10fold Lasso Regression Lambda Range This value is often chosen via cross. The lm.ridge() function in the mass library can perform the ridge regression. While both ridge regression and the lasso shrink the model parameters (b α, α = 1,., m) towards zero: In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. Lasso (least absolute shrinkage. Lasso Regression Lambda Range.
From www.youtube.com
Lasso regression explained YouTube Lasso Regression Lambda Range Lasso parameters reach zero at different. The lambda (λ) value(s) must be. To get the lasso estimates we have to minimise: In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). While both ridge regression and the lasso shrink the model parameters (b α, α = 1,., m) towards zero: The. Lasso Regression Lambda Range.
From www.researchgate.net
The Optimal Lambda for LASSO by Applying Cross Validation Plot Lasso Regression Lambda Range Lasso parameters reach zero at different. In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. The lambda (λ) value(s) must be. The lm.ridge() function in the mass library can perform the ridge regression. To get the lasso estimates we have to minimise: This value is. Lasso Regression Lambda Range.
From bookdown.org
4 Lasso Regression Machine Learning for Biostatistics Lasso Regression Lambda Range Lasso parameters reach zero at different. In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. The lambda (λ) value(s) must be. In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). Lasso (least absolute shrinkage and selection operator), similar to ridge. In. Lasso Regression Lambda Range.
From www.researchgate.net
Features selection by Lasso regression. The figure shows the Lasso Regression Lambda Range This value is often chosen via cross. The lambda (λ) value(s) must be. Lasso (least absolute shrinkage and selection operator), similar to ridge. In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. While both ridge regression and the lasso shrink the model parameters (b α,. Lasso Regression Lambda Range.
From www.researchgate.net
Texture feature selection using LASSO regression model. (A) Lambda Lasso Regression Lambda Range While both ridge regression and the lasso shrink the model parameters (b α, α = 1,., m) towards zero: In lasso regression, we select a value for λ that produces the lowest possible test mse (mean squared error). Lasso parameters reach zero at different. This value is often chosen via cross. The lm.ridge() function in the mass library can perform. Lasso Regression Lambda Range.
From www.statology.org
Introduction to Lasso Regression Lasso Regression Lambda Range In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. The lambda (λ) value(s) must be. Lasso (least absolute shrinkage and selection operator), similar to ridge. In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. The lm.ridge(). Lasso Regression Lambda Range.
From www.researchgate.net
Clinical feature selection using the LASSO regression analysis with Lasso Regression Lambda Range Lasso parameters reach zero at different. While both ridge regression and the lasso shrink the model parameters (b α, α = 1,., m) towards zero: In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. In lasso or ridge regression, one has to specify a shrinkage. Lasso Regression Lambda Range.
From www.researchgate.net
A plot of λ versus mean squared error for both Ridge and Lasso Lasso Regression Lambda Range In lasso regression, the hyperparameter lambda (λ), also known as the l1 penalty, balances the tradeoff between bias and variance in the resulting coefficients. Lasso (least absolute shrinkage and selection operator), similar to ridge. In lasso or ridge regression, one has to specify a shrinkage parameter, often called by $\lambda$ or $\alpha$. Lasso parameters reach zero at different. To get. Lasso Regression Lambda Range.