Partition Data In S3 . It seems to be a good idea to have files partitioned by three values: Store your data as a partition in amazon simple storage service. In this post, we show you how to efficiently process partitioned datasets using aws glue. This allows you to easily retrieve all rows. There are a few factors to consider when deciding the columns on which to partition. In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. Partitions are data organized hierarchically, defining the location where the data for a particular partition resides. Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and reducing cost. Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. To create a partitioned athena table, complete the following steps: First, we cover how to set up a crawler to automatically scan your.
from www.tableau.com
First, we cover how to set up a crawler to automatically scan your. Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. There are a few factors to consider when deciding the columns on which to partition. Partitions are data organized hierarchically, defining the location where the data for a particular partition resides. In this post, we show you how to efficiently process partitioned datasets using aws glue. Store your data as a partition in amazon simple storage service. This allows you to easily retrieve all rows. In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. It seems to be a good idea to have files partitioned by three values: Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and reducing cost.
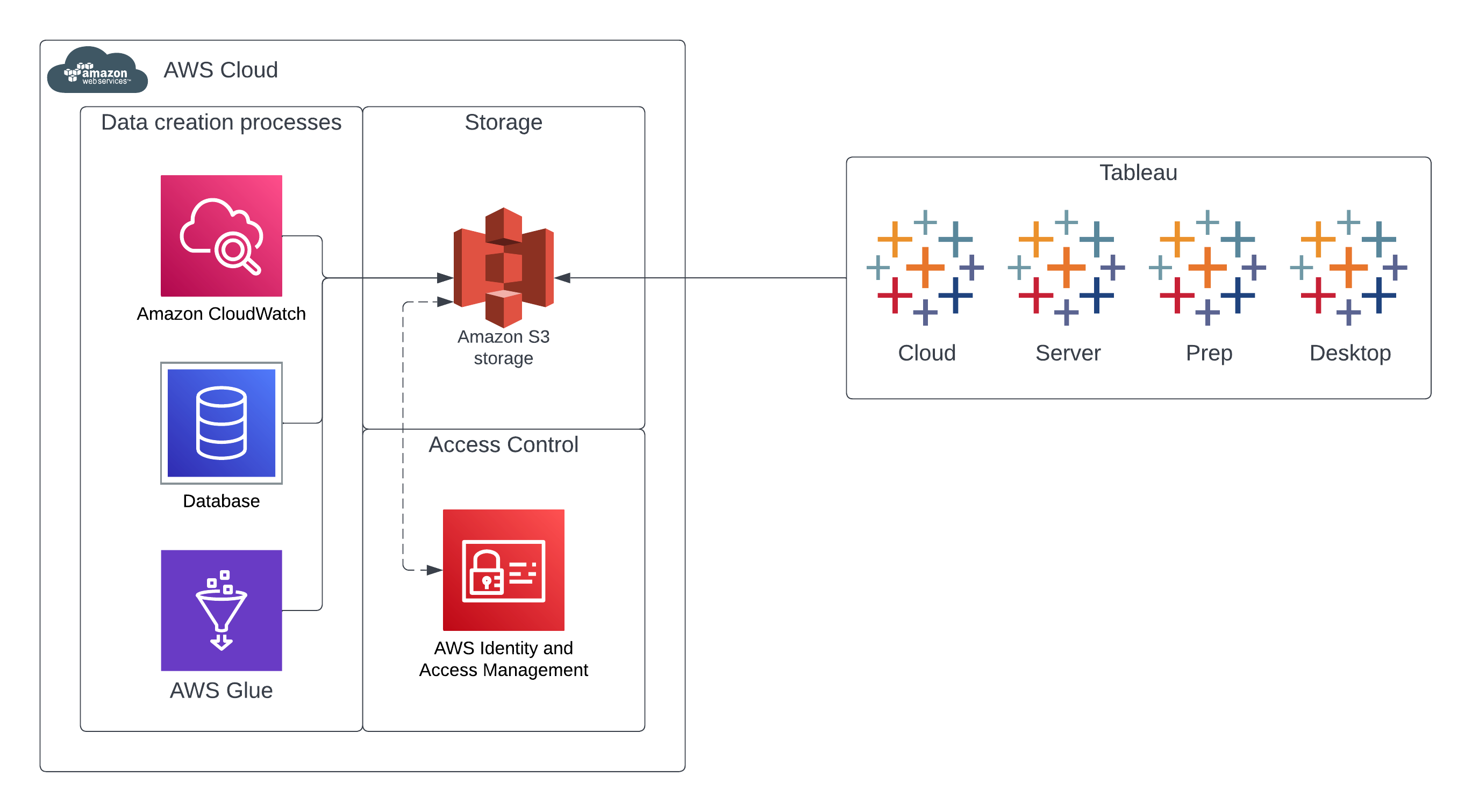
How to Get Access to Amazon S3 Data Directly from Tableau
Partition Data In S3 In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and reducing cost. Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. In this post, we show you how to efficiently process partitioned datasets using aws glue. To create a partitioned athena table, complete the following steps: This allows you to easily retrieve all rows. First, we cover how to set up a crawler to automatically scan your. It seems to be a good idea to have files partitioned by three values: Partitions are data organized hierarchically, defining the location where the data for a particular partition resides. There are a few factors to consider when deciding the columns on which to partition. Store your data as a partition in amazon simple storage service.
From docs.streamsets.com
Amazon S3 Partition Data In S3 It seems to be a good idea to have files partitioned by three values: Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. In this post, we show you how to efficiently process partitioned datasets using aws glue. There are a few factors to consider when deciding the columns. Partition Data In S3.
From docs.aws.amazon.com
Naming S3 buckets in your data layers AWS Prescriptive Guidance Partition Data In S3 Partitions are data organized hierarchically, defining the location where the data for a particular partition resides. Store your data as a partition in amazon simple storage service. It seems to be a good idea to have files partitioned by three values: Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and. Partition Data In S3.
From rockset.com
RealTime Analytics On DynamoDB With Lambda & More Rockset Partition Data In S3 Store your data as a partition in amazon simple storage service. First, we cover how to set up a crawler to automatically scan your. This allows you to easily retrieve all rows. Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. Partitions are data organized hierarchically, defining the location. Partition Data In S3.
From logicalread.com
Partition Tables Can Improve SQL Server Performance Partition Data In S3 In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. Partitions are data organized hierarchically, defining the location where the data for a particular partition resides. Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. It. Partition Data In S3.
From kb.synology.com
What are drive partitions? Synology Knowledge Center Partition Data In S3 Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. First, we cover how to set up a crawler to automatically scan your. Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and reducing cost. In this post, we show you. Partition Data In S3.
From dyfanjones.github.io
AWS S3 Backend • RAthena Partition Data In S3 Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and reducing cost. In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. Partitioning and bucketing are two ways to reduce the amount of data athena must scan when. Partition Data In S3.
From www.youtube.com
How to query data via S3 Select S3 Bucket SQL YouTube Partition Data In S3 It seems to be a good idea to have files partitioned by three values: In this post, we show you how to efficiently process partitioned datasets using aws glue. Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. Store your data as a partition in amazon simple storage service.. Partition Data In S3.
From www.datasunrise.com
What is Partitioning? Partition Data In S3 This allows you to easily retrieve all rows. In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. There are a few factors to consider when deciding the columns on which to partition. It seems to be a good idea to have files partitioned by three values:. Partition Data In S3.
From stackoverflow.com
amazon s3 Athena Date Partition Without Extra Bits Stack Overflow Partition Data In S3 Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. Store your data as a partition in amazon simple storage service. Partitions are data organized hierarchically, defining. Partition Data In S3.
From stackoverflow.com
amazon s3 How to partition amplify S3 storage by prefixing bucket Partition Data In S3 In this post, we show you how to efficiently process partitioned datasets using aws glue. It seems to be a good idea to have files partitioned by three values: In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. Partitioning your data allows you to limit the. Partition Data In S3.
From tech.connehito.com
AWS Glueを用いてETL環境を構築したお話(RDS for MySQL → S3) コネヒト開発者ブログ Partition Data In S3 In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. It seems to be a good idea to have files partitioned by three values: This allows you. Partition Data In S3.
From questdb.io
What Is Database Partitioning? Partition Data In S3 Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and reducing cost. Store your data as a partition in amazon simple storage service. In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. First, we cover how to. Partition Data In S3.
From www.cockroachlabs.com
What is data partitioning, and how to do it right Partition Data In S3 There are a few factors to consider when deciding the columns on which to partition. First, we cover how to set up a crawler to automatically scan your. This allows you to easily retrieve all rows. To create a partitioned athena table, complete the following steps: In this post, we show you how to efficiently process partitioned datasets using aws. Partition Data In S3.
From thedataguy.in
RedShift Unload to S3 With Partitions Stored Procedure Way Partition Data In S3 There are a few factors to consider when deciding the columns on which to partition. Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and reducing cost. Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. In an aws s3. Partition Data In S3.
From github.com
add partition option to s3.merge_upsert_table so it can upsert to Partition Data In S3 To create a partitioned athena table, complete the following steps: There are a few factors to consider when deciding the columns on which to partition. Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and reducing cost. Partitioning and bucketing are two ways to reduce the amount of data athena must. Partition Data In S3.
From www.youtube.com
10 AWS Data Analytics Partition / Shard / Scaling / AWS Storage S3 Partition Data In S3 To create a partitioned athena table, complete the following steps: First, we cover how to set up a crawler to automatically scan your. Partitions are data organized hierarchically, defining the location where the data for a particular partition resides. This allows you to easily retrieve all rows. In an aws s3 data lake architecture, partitioning plays a crucial role when. Partition Data In S3.
From www.sqlshack.com
SQL Partition overview Partition Data In S3 Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and reducing cost. In this post, we show you how to efficiently process partitioned datasets using aws glue. To create a partitioned athena table, complete the following steps: There are a few factors to consider when deciding the columns on which to. Partition Data In S3.
From community.dataiku.com
Activate Partition for S3 Dataiku Community Partition Data In S3 First, we cover how to set up a crawler to automatically scan your. Store your data as a partition in amazon simple storage service. Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby. Partition Data In S3.
From baluvyamajala.medium.com
Publish Streaming data into Aws S3 Data Lake and Query it by Balu Partition Data In S3 This allows you to easily retrieve all rows. In this post, we show you how to efficiently process partitioned datasets using aws glue. Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and reducing cost. In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in. Partition Data In S3.
From arpitbhayani.me
Data Partitioning Partition Data In S3 It seems to be a good idea to have files partitioned by three values: To create a partitioned athena table, complete the following steps: In this post, we show you how to efficiently process partitioned datasets using aws glue. There are a few factors to consider when deciding the columns on which to partition. In an aws s3 data lake. Partition Data In S3.
From recoverit.wondershare.com
What Is Basic Data Partition & Its Difference From Primary Partition Partition Data In S3 Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and reducing cost. Store your data as a partition in amazon simple storage service. Partitions are data organized hierarchically, defining the location where the data for a particular partition resides. In this post, we show you how to efficiently process partitioned datasets. Partition Data In S3.
From www.tinybird.co
How to set up eventbased ingestion of files in S3 for free Partition Data In S3 In this post, we show you how to efficiently process partitioned datasets using aws glue. It seems to be a good idea to have files partitioned by three values: In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. To create a partitioned athena table, complete the. Partition Data In S3.
From www.tableau.com
How to Get Access to Amazon S3 Data Directly from Tableau Partition Data In S3 Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. Partitions are data organized hierarchically, defining the location where the data for a particular partition resides. In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. This. Partition Data In S3.
From subscription.packtpub.com
Partitioning Introducing Microsoft SQL Server 2019 Partition Data In S3 First, we cover how to set up a crawler to automatically scan your. There are a few factors to consider when deciding the columns on which to partition. Partitions are data organized hierarchically, defining the location where the data for a particular partition resides. In this post, we show you how to efficiently process partitioned datasets using aws glue. Store. Partition Data In S3.
From www.youtube.com
ESP32 Partition Table and NVS data storage YouTube Partition Data In S3 To create a partitioned athena table, complete the following steps: This allows you to easily retrieve all rows. First, we cover how to set up a crawler to automatically scan your. It seems to be a good idea to have files partitioned by three values: In this post, we show you how to efficiently process partitioned datasets using aws glue.. Partition Data In S3.
From aws.amazon.com
Get started managing partitions for Amazon S3 tables backed by the AWS Partition Data In S3 In this post, we show you how to efficiently process partitioned datasets using aws glue. First, we cover how to set up a crawler to automatically scan your. In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. Partitioning and bucketing are two ways to reduce the. Partition Data In S3.
From docs.aws.amazon.com
Tutorial Mengubah data untuk aplikasi Anda dengan S3 Object Lambda Partition Data In S3 To create a partitioned athena table, complete the following steps: First, we cover how to set up a crawler to automatically scan your. Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving. Partition Data In S3.
From learn.microsoft.com
Data partitioning strategies Azure Architecture Center Microsoft Learn Partition Data In S3 It seems to be a good idea to have files partitioned by three values: First, we cover how to set up a crawler to automatically scan your. Store your data as a partition in amazon simple storage service. In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since. Partition Data In S3.
From www.youtube.com
Why should we partition the data in spark? YouTube Partition Data In S3 It seems to be a good idea to have files partitioned by three values: Store your data as a partition in amazon simple storage service. Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and reducing cost. This allows you to easily retrieve all rows. There are a few factors to. Partition Data In S3.
From mainvehicle.weebly.com
Basic data partition vs primary partition mainvehicle Partition Data In S3 Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. This allows you to easily retrieve all rows. Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and reducing cost. There are a few factors to consider when deciding the columns. Partition Data In S3.
From play.whizlabs.com
Querying Data in S3 with Amazon Athena Partition Data In S3 First, we cover how to set up a crawler to automatically scan your. In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. It seems to be a good idea to have files partitioned by three values: There are a few factors to consider when deciding the. Partition Data In S3.
From thecodinginterface.com
Managing S3 Data Store Partitions with AWS Glue Crawlers and Glue Partition Data In S3 Store your data as a partition in amazon simple storage service. Partitioning your data allows you to limit the amount of data scanned by s3 select, thereby improving performance and reducing cost. In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. To create a partitioned athena. Partition Data In S3.
From www.tenforums.com
nstall windows 10 what to do with partition and where to load Windows Partition Data In S3 First, we cover how to set up a crawler to automatically scan your. Store your data as a partition in amazon simple storage service. Partitioning and bucketing are two ways to reduce the amount of data athena must scan when you run a query. It seems to be a good idea to have files partitioned by three values: In this. Partition Data In S3.
From stackoverflow.com
python awswrangler.s3.read_parquet ignores partition_filter argument Partition Data In S3 To create a partitioned athena table, complete the following steps: First, we cover how to set up a crawler to automatically scan your. Partitions are data organized hierarchically, defining the location where the data for a particular partition resides. It seems to be a good idea to have files partitioned by three values: This allows you to easily retrieve all. Partition Data In S3.
From ujjwalbhardwaj.me
Partition Data in S3 by Date from the Input File Name using AWS Glue Partition Data In S3 First, we cover how to set up a crawler to automatically scan your. There are a few factors to consider when deciding the columns on which to partition. In an aws s3 data lake architecture, partitioning plays a crucial role when querying data in amazon athena or redshift spectrum since it. Partitioning and bucketing are two ways to reduce the. Partition Data In S3.