Job-Bookmark-From . This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. It also shows how to scale aws glue etl jobs by reading. By default it will bookmark on the pk, so it won't detect updates but if you always update the updated_at column with a timestamp when. It has a feature called job bookmarks to process incremental data when rerunning a job on a scheduled interval. For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. Using job bookmarks in aws glue jobs. Aws glue is a fully managed etl service to load large amounts of datasets from various sources for analytics and data processing with apache. Aws glue uses job bookmark to track processing of the data to ensure data processed in the previous job run does not get processed again.
from www.youtube.com
It also shows how to scale aws glue etl jobs by reading. Aws glue uses job bookmark to track processing of the data to ensure data processed in the previous job run does not get processed again. For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. By default it will bookmark on the pk, so it won't detect updates but if you always update the updated_at column with a timestamp when. This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. It has a feature called job bookmarks to process incremental data when rerunning a job on a scheduled interval. Using job bookmarks in aws glue jobs. Aws glue is a fully managed etl service to load large amounts of datasets from various sources for analytics and data processing with apache.
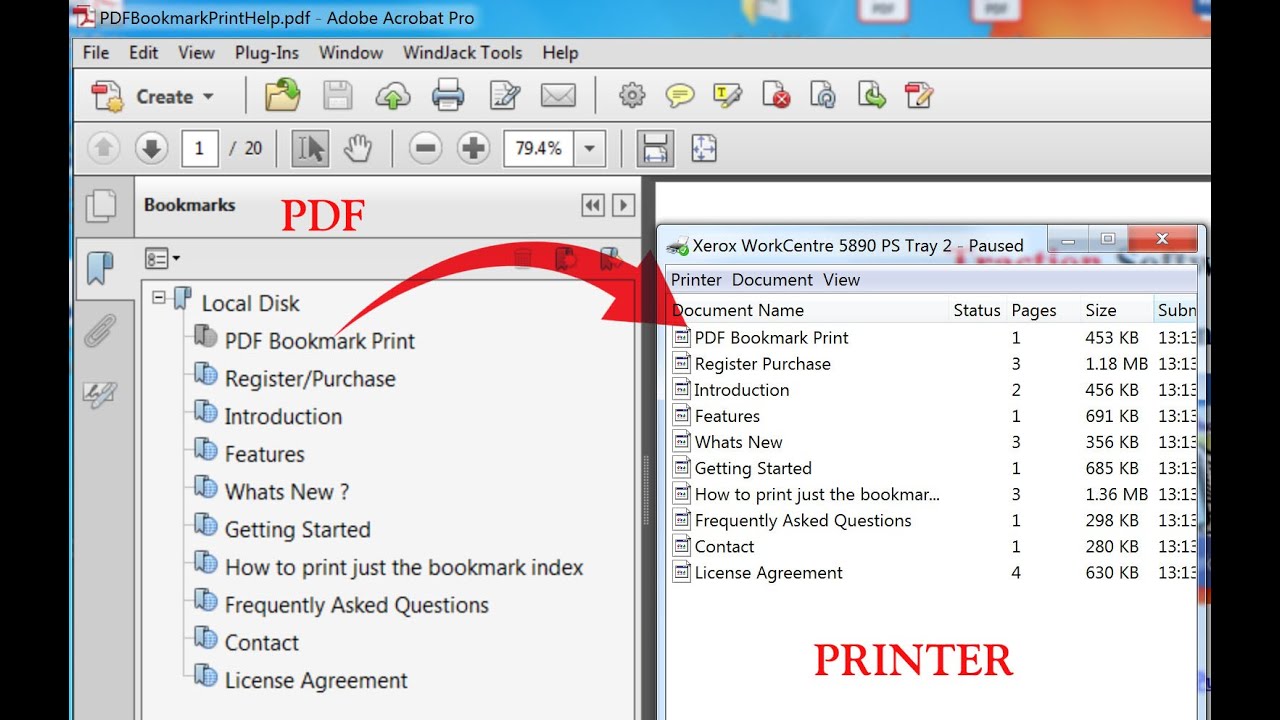
How to print pdf bookmarks with the bookmark as the print job name
Job-Bookmark-From This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. It has a feature called job bookmarks to process incremental data when rerunning a job on a scheduled interval. Using job bookmarks in aws glue jobs. By default it will bookmark on the pk, so it won't detect updates but if you always update the updated_at column with a timestamp when. It also shows how to scale aws glue etl jobs by reading. Aws glue is a fully managed etl service to load large amounts of datasets from various sources for analytics and data processing with apache. Aws glue uses job bookmark to track processing of the data to ensure data processed in the previous job run does not get processed again. This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks.
From jobs-redefined.co
Bank of Ireland Jobs/Redefined Job-Bookmark-From By default it will bookmark on the pk, so it won't detect updates but if you always update the updated_at column with a timestamp when. It also shows how to scale aws glue etl jobs by reading. It has a feature called job bookmarks to process incremental data when rerunning a job on a scheduled interval. Using job bookmarks in. Job-Bookmark-From.
From www.diys.com
30 Best DIY Bookmark Ideas for Crafty Bookworms Job-Bookmark-From By default it will bookmark on the pk, so it won't detect updates but if you always update the updated_at column with a timestamp when. Using job bookmarks in aws glue jobs. Aws glue is a fully managed etl service to load large amounts of datasets from various sources for analytics and data processing with apache. It also shows how. Job-Bookmark-From.
From www.energyjobline.com
ULTEUM Energy Jobline Job-Bookmark-From For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. It has a feature called job bookmarks to process incremental data when rerunning a job on a scheduled interval. It also shows how to scale aws glue etl jobs by reading. Aws glue is a fully managed etl service to load. Job-Bookmark-From.
From iret.media
AWS GlueのJob Bookmarkの使い方 iret.media Job-Bookmark-From This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. Aws glue uses job bookmark to track processing of the data to ensure data processed in the previous job run does not get processed again. Aws glue is a fully managed etl service to load large amounts of datasets. Job-Bookmark-From.
From myexceltemplates.com
Promotional Bookmarks Promotional Bookmark Template Job-Bookmark-From By default it will bookmark on the pk, so it won't detect updates but if you always update the updated_at column with a timestamp when. For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. This post shows how to incrementally load data from data sources in an amazon s3 data. Job-Bookmark-From.
From www.pinterest.com
'A New Chapter Begins…' Bookmark Metal stamped jewelry, Bookmarks Job-Bookmark-From Aws glue uses job bookmark to track processing of the data to ensure data processed in the previous job run does not get processed again. For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. It has a feature called job bookmarks to process incremental data when rerunning a job on. Job-Bookmark-From.
From www.okuling.com
Jobs Bookmark Meslekler Kitap Ayracı Job-Bookmark-From Using job bookmarks in aws glue jobs. It has a feature called job bookmarks to process incremental data when rerunning a job on a scheduled interval. By default it will bookmark on the pk, so it won't detect updates but if you always update the updated_at column with a timestamp when. Aws glue is a fully managed etl service to. Job-Bookmark-From.
From getmythemes.com
Download WP Job Manager Bookmarks 1.5.0 GetMyThemes Job-Bookmark-From For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. Aws glue uses job bookmark to track processing of the data to ensure data processed in the previous job run does not get processed again. It also shows how to scale aws glue etl jobs by reading. By default it will. Job-Bookmark-From.
From medium.com
Implementing Glue ETL job with Job Bookmarks by Anand Prakash Job-Bookmark-From It also shows how to scale aws glue etl jobs by reading. Aws glue is a fully managed etl service to load large amounts of datasets from various sources for analytics and data processing with apache. For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. By default it will bookmark. Job-Bookmark-From.
From www.etsy.com
Book of Job Christian Bookmarks Set of 6 // Job 19 25 Etsy Job-Bookmark-From This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. Using job bookmarks in aws glue jobs. It also shows how to scale aws glue etl jobs by reading. By. Job-Bookmark-From.
From www.gplvault.com
WP Job Manager Bookmarks v1.5.0 GPL Vault Job-Bookmark-From Using job bookmarks in aws glue jobs. This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. It has a feature called job bookmarks to process incremental data when rerunning a job on a scheduled interval. For a summary of the job bookmarks feature and what it supports, see. Job-Bookmark-From.
From www.inspiringyoungminds.ca
You Did a Grape Job Scented Bookmark Inspiring Young Minds to Learn Job-Bookmark-From This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. Using job bookmarks in aws glue jobs. Aws glue is a fully managed etl service to load large amounts of datasets from various sources for analytics and data processing with apache. It also shows how to scale aws glue. Job-Bookmark-From.
From www.desertdomicile.com
30 DIY Bookmark Ideas To Liven Up Your Reading Job-Bookmark-From By default it will bookmark on the pk, so it won't detect updates but if you always update the updated_at column with a timestamp when. For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. Using job bookmarks in aws glue jobs. This post shows how to incrementally load data from. Job-Bookmark-From.
From www.electrogeekshop.com
WP Job Manager Bookmarks Plugin para Wordpress Electrogeek Job-Bookmark-From It also shows how to scale aws glue etl jobs by reading. By default it will bookmark on the pk, so it won't detect updates but if you always update the updated_at column with a timestamp when. This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. It has. Job-Bookmark-From.
From www.youtube.com
How to print pdf bookmarks with the bookmark as the print job name Job-Bookmark-From Using job bookmarks in aws glue jobs. It also shows how to scale aws glue etl jobs by reading. For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. By default it will bookmark on the pk, so it won't detect updates but if you always update the updated_at column with. Job-Bookmark-From.
From www.etsy.com
Book of Job Christian Bookmarks Set of 6 // Job 19 25 Etsy Job-Bookmark-From Using job bookmarks in aws glue jobs. By default it will bookmark on the pk, so it won't detect updates but if you always update the updated_at column with a timestamp when. Aws glue uses job bookmark to track processing of the data to ensure data processed in the previous job run does not get processed again. It also shows. Job-Bookmark-From.
From www.etsy.com
Book of Job Christian Bookmarks Set of 6 // Job 19 25 Etsy Job-Bookmark-From Using job bookmarks in aws glue jobs. Aws glue is a fully managed etl service to load large amounts of datasets from various sources for analytics and data processing with apache. This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. It has a feature called job bookmarks to. Job-Bookmark-From.
From tealnotes.com
DIY Bookmark With Book List Pocket +10 Extra Design Ideas Job-Bookmark-From Aws glue is a fully managed etl service to load large amounts of datasets from various sources for analytics and data processing with apache. This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. By default it will bookmark on the pk, so it won't detect updates but if. Job-Bookmark-From.
From gplclubbd.com
WP Job Manager Bookmarks Addon 1.4.2 latest version download GPL Club BD Job-Bookmark-From For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. It has a feature called job bookmarks to process incremental data when rerunning a job on a scheduled interval. Using. Job-Bookmark-From.
From cheapwoocommerce.com
WP Job Manager Bookmarks Addon 1.4.1 ·9.99 + Free Updates Job-Bookmark-From It has a feature called job bookmarks to process incremental data when rerunning a job on a scheduled interval. For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. By default it will bookmark on the pk, so it won't detect updates but if you always update the updated_at column with. Job-Bookmark-From.
From www.pinterest.com
Beads bookmark Handmade Bookmarks, Beaded Bookmarks, Book Of Job, First Job-Bookmark-From Aws glue is a fully managed etl service to load large amounts of datasets from various sources for analytics and data processing with apache. Using job bookmarks in aws glue jobs. It also shows how to scale aws glue etl jobs by reading. For a summary of the job bookmarks feature and what it supports, see tracking processed data using. Job-Bookmark-From.
From aura-print.com
Bookmarks Designed to Match Your Current Read AP UK Job-Bookmark-From It also shows how to scale aws glue etl jobs by reading. This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. Aws glue uses job bookmark to track processing of the data to ensure data processed in the previous job run does not get processed again. Aws glue. Job-Bookmark-From.
From www.etsy.com
Book of Job Christian Bookmarks Set of 6 // Job 19 25 Etsy Job-Bookmark-From Using job bookmarks in aws glue jobs. It has a feature called job bookmarks to process incremental data when rerunning a job on a scheduled interval. Aws glue is a fully managed etl service to load large amounts of datasets from various sources for analytics and data processing with apache. By default it will bookmark on the pk, so it. Job-Bookmark-From.
From mymetalbusinesscard.com
Quick Metal Bookmarks My Metal Business Card Job-Bookmark-From It has a feature called job bookmarks to process incremental data when rerunning a job on a scheduled interval. It also shows how to scale aws glue etl jobs by reading. Using job bookmarks in aws glue jobs. For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. This post shows. Job-Bookmark-From.
From medialibrary.cloversites.com
The Story of Job Bible Bookmarks Clover Media Job-Bookmark-From By default it will bookmark on the pk, so it won't detect updates but if you always update the updated_at column with a timestamp when. This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. It has a feature called job bookmarks to process incremental data when rerunning a. Job-Bookmark-From.
From pngtree.com
Good Job For Today Bookmark Template With Red Leaves Template Download Job-Bookmark-From Using job bookmarks in aws glue jobs. By default it will bookmark on the pk, so it won't detect updates but if you always update the updated_at column with a timestamp when. It has a feature called job bookmarks to process incremental data when rerunning a job on a scheduled interval. Aws glue is a fully managed etl service to. Job-Bookmark-From.
From www.walmart.com
Never Give Up on Your Dreams New Job Graduation Glossy Laminated Job-Bookmark-From Using job bookmarks in aws glue jobs. It also shows how to scale aws glue etl jobs by reading. Aws glue uses job bookmark to track processing of the data to ensure data processed in the previous job run does not get processed again. By default it will bookmark on the pk, so it won't detect updates but if you. Job-Bookmark-From.
From jthemes.com
JobboxDocumentation Job-Bookmark-From Aws glue is a fully managed etl service to load large amounts of datasets from various sources for analytics and data processing with apache. For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. Aws glue uses job bookmark to track processing of the data to ensure data processed in the. Job-Bookmark-From.
From www.diys.com
25 Different Ways To Make and Create Your Own BookMarks Job-Bookmark-From This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. Aws glue uses job bookmark to track processing of the data to ensure data processed in the previous job run does not get processed again. For a summary of the job bookmarks feature and what it supports, see tracking. Job-Bookmark-From.
From geeklink.io
Saving Bookmarks for Job Vacancies Job-Bookmark-From It also shows how to scale aws glue etl jobs by reading. Using job bookmarks in aws glue jobs. It has a feature called job bookmarks to process incremental data when rerunning a job on a scheduled interval. Aws glue is a fully managed etl service to load large amounts of datasets from various sources for analytics and data processing. Job-Bookmark-From.
From www.etsy.com
Book of Job Christian Bookmarks Set of 6 // Job 19 25 Etsy Job-Bookmark-From This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. Using job bookmarks in aws glue jobs. Aws glue is a fully managed etl service to load large amounts of datasets from various sources for analytics and data processing with apache. For a summary of the job bookmarks feature. Job-Bookmark-From.
From www.behance.net
Free Bookmark Mockup Behance Job-Bookmark-From Using job bookmarks in aws glue jobs. It also shows how to scale aws glue etl jobs by reading. Aws glue uses job bookmark to track processing of the data to ensure data processed in the previous job run does not get processed again. By default it will bookmark on the pk, so it won't detect updates but if you. Job-Bookmark-From.
From www.wework4days.com
Job Board WeWork4Days Job-Bookmark-From Aws glue is a fully managed etl service to load large amounts of datasets from various sources for analytics and data processing with apache. This post shows how to incrementally load data from data sources in an amazon s3 data lake and databases using jdbc. It has a feature called job bookmarks to process incremental data when rerunning a job. Job-Bookmark-From.
From www.rewardcharts4kids.com
Free Good Job sticker printables Print on paper and adhere with glue Job-Bookmark-From For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. It also shows how to scale aws glue etl jobs by reading. It has a feature called job bookmarks to process incremental data when rerunning a job on a scheduled interval. Using job bookmarks in aws glue jobs. By default it. Job-Bookmark-From.
From aworkstation.com
3D Bookmarks Come to Life When Pressed Between the Pages of Your Job-Bookmark-From Using job bookmarks in aws glue jobs. For a summary of the job bookmarks feature and what it supports, see tracking processed data using job bookmarks. Aws glue uses job bookmark to track processing of the data to ensure data processed in the previous job run does not get processed again. It has a feature called job bookmarks to process. Job-Bookmark-From.