Redshift Sort Key Vs Distribution Key . Distkey is a column designation that determines how data is distributed across compute nodes in a redshift cluster. Create table activity ( id integer primary key, created_at_date distkey, device varchar(30) ) sortkey (created_at_date, device); When the table grows larger, amazon redshift might change the distribution style to key, choosing the primary key (or a column of the. Redshift stores data on disk in sorted order according to the sort key, which has an important effect on query performance. A compound sort key is more efficient when query predicates use a prefix, which is a. It helps optimize query performance by. Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement from the naive query! If the table participates in join operations and has appropriate distkey columns, then we need to decide between key or all distribution styles. The following example creates a sales table in the tickit database. Create a table with a distribution key, a compound sort key, and compression. You can specify either a compound or interleaved sort key.
from thedataguy.in
Distkey is a column designation that determines how data is distributed across compute nodes in a redshift cluster. Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement from the naive query! Redshift stores data on disk in sorted order according to the sort key, which has an important effect on query performance. Create a table with a distribution key, a compound sort key, and compression. You can specify either a compound or interleaved sort key. When the table grows larger, amazon redshift might change the distribution style to key, choosing the primary key (or a column of the. A compound sort key is more efficient when query predicates use a prefix, which is a. If the table participates in join operations and has appropriate distkey columns, then we need to decide between key or all distribution styles. Create table activity ( id integer primary key, created_at_date distkey, device varchar(30) ) sortkey (created_at_date, device); The following example creates a sales table in the tickit database.
Why You Should Not Compress RedShift Sort Key Column
Redshift Sort Key Vs Distribution Key It helps optimize query performance by. Create table activity ( id integer primary key, created_at_date distkey, device varchar(30) ) sortkey (created_at_date, device); Distkey is a column designation that determines how data is distributed across compute nodes in a redshift cluster. The following example creates a sales table in the tickit database. When the table grows larger, amazon redshift might change the distribution style to key, choosing the primary key (or a column of the. A compound sort key is more efficient when query predicates use a prefix, which is a. Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement from the naive query! It helps optimize query performance by. If the table participates in join operations and has appropriate distkey columns, then we need to decide between key or all distribution styles. You can specify either a compound or interleaved sort key. Redshift stores data on disk in sorted order according to the sort key, which has an important effect on query performance. Create a table with a distribution key, a compound sort key, and compression.
From fyokbdnrg.blob.core.windows.net
Redshift Get Sort Key Of Table at Bryan Walker blog Redshift Sort Key Vs Distribution Key When the table grows larger, amazon redshift might change the distribution style to key, choosing the primary key (or a column of the. The following example creates a sales table in the tickit database. Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement from the naive query! Distkey. Redshift Sort Key Vs Distribution Key.
From exomwaumb.blob.core.windows.net
Redshift Sort Key Best Practices at Frank Pass blog Redshift Sort Key Vs Distribution Key Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement from the naive query! A compound sort key is more efficient when query predicates use a prefix, which is a. When the table grows larger, amazon redshift might change the distribution style to key, choosing the primary key (or. Redshift Sort Key Vs Distribution Key.
From fyokbdnrg.blob.core.windows.net
Redshift Get Sort Key Of Table at Bryan Walker blog Redshift Sort Key Vs Distribution Key Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement from the naive query! The following example creates a sales table in the tickit database. It helps optimize query performance by. A compound sort key is more efficient when query predicates use a prefix, which is a. Distkey is. Redshift Sort Key Vs Distribution Key.
From exonyseru.blob.core.windows.net
Redshift Sort Key Auto at Emanuel Bundy blog Redshift Sort Key Vs Distribution Key It helps optimize query performance by. Redshift stores data on disk in sorted order according to the sort key, which has an important effect on query performance. Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement from the naive query! Create table activity ( id integer primary key,. Redshift Sort Key Vs Distribution Key.
From www.clickittech.com
Snowflake vs Redshift Key Differences Redshift Sort Key Vs Distribution Key The following example creates a sales table in the tickit database. Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement from the naive query! When the table grows larger, amazon redshift might change the distribution style to key, choosing the primary key (or a column of the. It. Redshift Sort Key Vs Distribution Key.
From fyokotyfe.blob.core.windows.net
Distribution Key Vs Sort Key at Candace Schaller blog Redshift Sort Key Vs Distribution Key A compound sort key is more efficient when query predicates use a prefix, which is a. It helps optimize query performance by. Distkey is a column designation that determines how data is distributed across compute nodes in a redshift cluster. If the table participates in join operations and has appropriate distkey columns, then we need to decide between key or. Redshift Sort Key Vs Distribution Key.
From exoiaqbto.blob.core.windows.net
Redshift Distribution Key And Sort Key Example at Marissa Johnson blog Redshift Sort Key Vs Distribution Key You can specify either a compound or interleaved sort key. The following example creates a sales table in the tickit database. If the table participates in join operations and has appropriate distkey columns, then we need to decide between key or all distribution styles. Create table activity ( id integer primary key, created_at_date distkey, device varchar(30) ) sortkey (created_at_date, device);. Redshift Sort Key Vs Distribution Key.
From fyokbdnrg.blob.core.windows.net
Redshift Get Sort Key Of Table at Bryan Walker blog Redshift Sort Key Vs Distribution Key It helps optimize query performance by. Create table activity ( id integer primary key, created_at_date distkey, device varchar(30) ) sortkey (created_at_date, device); Redshift stores data on disk in sorted order according to the sort key, which has an important effect on query performance. The following example creates a sales table in the tickit database. If the table participates in join. Redshift Sort Key Vs Distribution Key.
From www.youtube.com
23 Distribution styles in Redshift YouTube Redshift Sort Key Vs Distribution Key A compound sort key is more efficient when query predicates use a prefix, which is a. If the table participates in join operations and has appropriate distkey columns, then we need to decide between key or all distribution styles. Create a table with a distribution key, a compound sort key, and compression. You can specify either a compound or interleaved. Redshift Sort Key Vs Distribution Key.
From www.youtube.com
25 DB Views and Primary Key in Redshift YouTube Redshift Sort Key Vs Distribution Key A compound sort key is more efficient when query predicates use a prefix, which is a. When the table grows larger, amazon redshift might change the distribution style to key, choosing the primary key (or a column of the. Create a table with a distribution key, a compound sort key, and compression. Create table activity ( id integer primary key,. Redshift Sort Key Vs Distribution Key.
From dwgeek.com
How Redshift Distributes Table Data? Importance of right Distribution Redshift Sort Key Vs Distribution Key Create a table with a distribution key, a compound sort key, and compression. You can specify either a compound or interleaved sort key. Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement from the naive query! When the table grows larger, amazon redshift might change the distribution style. Redshift Sort Key Vs Distribution Key.
From exonyseru.blob.core.windows.net
Redshift Sort Key Auto at Emanuel Bundy blog Redshift Sort Key Vs Distribution Key Create a table with a distribution key, a compound sort key, and compression. You can specify either a compound or interleaved sort key. Create table activity ( id integer primary key, created_at_date distkey, device varchar(30) ) sortkey (created_at_date, device); Redshift stores data on disk in sorted order according to the sort key, which has an important effect on query performance.. Redshift Sort Key Vs Distribution Key.
From exonyseru.blob.core.windows.net
Redshift Sort Key Auto at Emanuel Bundy blog Redshift Sort Key Vs Distribution Key The following example creates a sales table in the tickit database. You can specify either a compound or interleaved sort key. It helps optimize query performance by. When the table grows larger, amazon redshift might change the distribution style to key, choosing the primary key (or a column of the. Redshift stores data on disk in sorted order according to. Redshift Sort Key Vs Distribution Key.
From thedataguy.in
Why You Should Not Compress RedShift Sort Key Column Redshift Sort Key Vs Distribution Key Create table activity ( id integer primary key, created_at_date distkey, device varchar(30) ) sortkey (created_at_date, device); The following example creates a sales table in the tickit database. A compound sort key is more efficient when query predicates use a prefix, which is a. You can specify either a compound or interleaved sort key. Create a table with a distribution key,. Redshift Sort Key Vs Distribution Key.
From community.alteryx.com
Redshift Distribution key and sort key Alteryx Community Redshift Sort Key Vs Distribution Key Create table activity ( id integer primary key, created_at_date distkey, device varchar(30) ) sortkey (created_at_date, device); The following example creates a sales table in the tickit database. A compound sort key is more efficient when query predicates use a prefix, which is a. When the table grows larger, amazon redshift might change the distribution style to key, choosing the primary. Redshift Sort Key Vs Distribution Key.
From b.hatena.ne.jp
[B!] Amazon Redshift Engineering’s Advanced Table Design Playbook Redshift Sort Key Vs Distribution Key You can specify either a compound or interleaved sort key. When the table grows larger, amazon redshift might change the distribution style to key, choosing the primary key (or a column of the. Create a table with a distribution key, a compound sort key, and compression. If the table participates in join operations and has appropriate distkey columns, then we. Redshift Sort Key Vs Distribution Key.
From community.microstrategy.com
Amazon Redshift Best Practices for Performance Redshift Sort Key Vs Distribution Key A compound sort key is more efficient when query predicates use a prefix, which is a. If the table participates in join operations and has appropriate distkey columns, then we need to decide between key or all distribution styles. Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement. Redshift Sort Key Vs Distribution Key.
From fyokotyfe.blob.core.windows.net
Distribution Key Vs Sort Key at Candace Schaller blog Redshift Sort Key Vs Distribution Key Create a table with a distribution key, a compound sort key, and compression. Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement from the naive query! A compound sort key is more efficient when query predicates use a prefix, which is a. If the table participates in join. Redshift Sort Key Vs Distribution Key.
From www.clickittech.com
Snowflake vs Redshift Key Differences Redshift Sort Key Vs Distribution Key The following example creates a sales table in the tickit database. Distkey is a column designation that determines how data is distributed across compute nodes in a redshift cluster. Create a table with a distribution key, a compound sort key, and compression. Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and. Redshift Sort Key Vs Distribution Key.
From exomwaumb.blob.core.windows.net
Redshift Sort Key Best Practices at Frank Pass blog Redshift Sort Key Vs Distribution Key The following example creates a sales table in the tickit database. When the table grows larger, amazon redshift might change the distribution style to key, choosing the primary key (or a column of the. It helps optimize query performance by. Create a table with a distribution key, a compound sort key, and compression. You can specify either a compound or. Redshift Sort Key Vs Distribution Key.
From docs.aws.amazon.com
Loading your data in sort key order Amazon Redshift Redshift Sort Key Vs Distribution Key You can specify either a compound or interleaved sort key. The following example creates a sales table in the tickit database. Create a table with a distribution key, a compound sort key, and compression. If the table participates in join operations and has appropriate distkey columns, then we need to decide between key or all distribution styles. When the table. Redshift Sort Key Vs Distribution Key.
From exoiaqbto.blob.core.windows.net
Redshift Distribution Key And Sort Key Example at Marissa Johnson blog Redshift Sort Key Vs Distribution Key It helps optimize query performance by. Create table activity ( id integer primary key, created_at_date distkey, device varchar(30) ) sortkey (created_at_date, device); Distkey is a column designation that determines how data is distributed across compute nodes in a redshift cluster. Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x. Redshift Sort Key Vs Distribution Key.
From dev.to
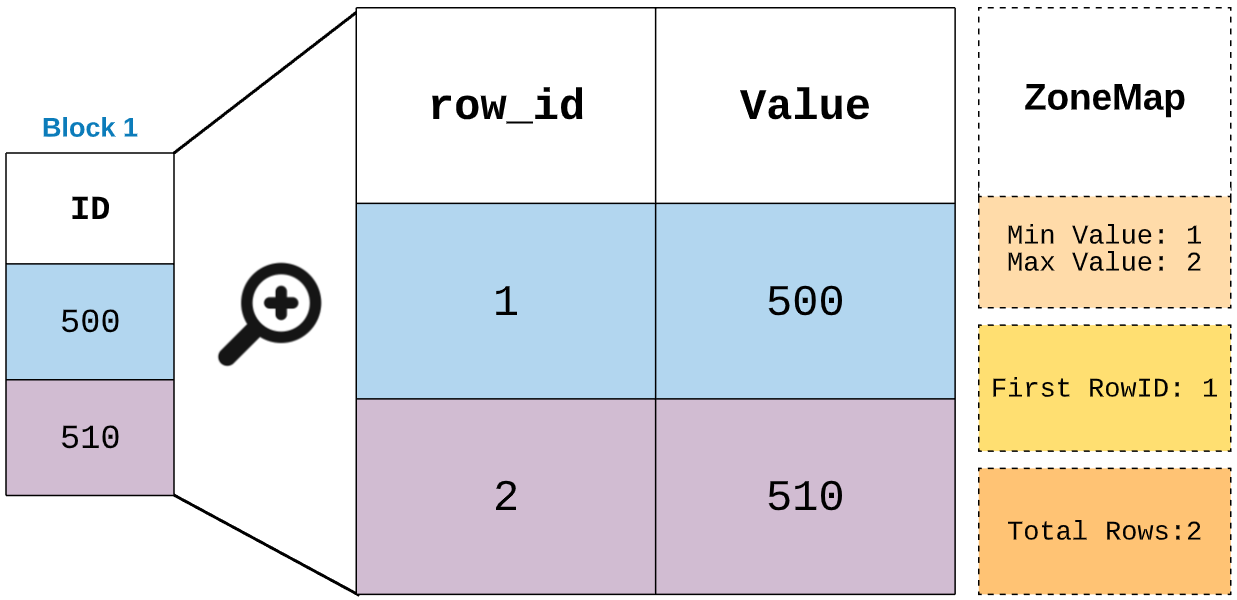
The R.A.G (Redshift Analyst Guide) Sorting & Zone Maps DEV Community Redshift Sort Key Vs Distribution Key A compound sort key is more efficient when query predicates use a prefix, which is a. When the table grows larger, amazon redshift might change the distribution style to key, choosing the primary key (or a column of the. Create table activity ( id integer primary key, created_at_date distkey, device varchar(30) ) sortkey (created_at_date, device); It helps optimize query performance. Redshift Sort Key Vs Distribution Key.
From www.boltic.io
AWS Redshift vs RDS Key Features, Comparison Redshift Sort Key Vs Distribution Key Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement from the naive query! If the table participates in join operations and has appropriate distkey columns, then we need to decide between key or all distribution styles. When the table grows larger, amazon redshift might change the distribution style. Redshift Sort Key Vs Distribution Key.
From thedataguy.in
Why You Should Not Compress RedShift Sort Key Column Redshift Sort Key Vs Distribution Key Redshift stores data on disk in sorted order according to the sort key, which has an important effect on query performance. You can specify either a compound or interleaved sort key. Distkey is a column designation that determines how data is distributed across compute nodes in a redshift cluster. If the table participates in join operations and has appropriate distkey. Redshift Sort Key Vs Distribution Key.
From cabinet.matttroy.net
Redshift Create Table If Not Exists Example Matttroy Redshift Sort Key Vs Distribution Key Redshift stores data on disk in sorted order according to the sort key, which has an important effect on query performance. Distkey is a column designation that determines how data is distributed across compute nodes in a redshift cluster. It helps optimize query performance by. Create table activity ( id integer primary key, created_at_date distkey, device varchar(30) ) sortkey (created_at_date,. Redshift Sort Key Vs Distribution Key.
From exoiaqbto.blob.core.windows.net
Redshift Distribution Key And Sort Key Example at Marissa Johnson blog Redshift Sort Key Vs Distribution Key Redshift stores data on disk in sorted order according to the sort key, which has an important effect on query performance. A compound sort key is more efficient when query predicates use a prefix, which is a. Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement from the. Redshift Sort Key Vs Distribution Key.
From www.youtube.com
Row skew and choosing the right distribution style in Redshift YouTube Redshift Sort Key Vs Distribution Key Create a table with a distribution key, a compound sort key, and compression. Distkey is a column designation that determines how data is distributed across compute nodes in a redshift cluster. When the table grows larger, amazon redshift might change the distribution style to key, choosing the primary key (or a column of the. It helps optimize query performance by.. Redshift Sort Key Vs Distribution Key.
From thedataguy.in
Why You Should Not Compress RedShift Sort Key Column Redshift Sort Key Vs Distribution Key Distkey is a column designation that determines how data is distributed across compute nodes in a redshift cluster. Create table activity ( id integer primary key, created_at_date distkey, device varchar(30) ) sortkey (created_at_date, device); A compound sort key is more efficient when query predicates use a prefix, which is a. If the table participates in join operations and has appropriate. Redshift Sort Key Vs Distribution Key.
From chartio.com
Interleaved Sort Keys in Amazon Redshift, Part 1 Chartio Blog Redshift Sort Key Vs Distribution Key Create table activity ( id integer primary key, created_at_date distkey, device varchar(30) ) sortkey (created_at_date, device); A compound sort key is more efficient when query predicates use a prefix, which is a. The following example creates a sales table in the tickit database. It helps optimize query performance by. Redshift stores data on disk in sorted order according to the. Redshift Sort Key Vs Distribution Key.
From exoiaqbto.blob.core.windows.net
Redshift Distribution Key And Sort Key Example at Marissa Johnson blog Redshift Sort Key Vs Distribution Key If the table participates in join operations and has appropriate distkey columns, then we need to decide between key or all distribution styles. It helps optimize query performance by. Distkey is a column designation that determines how data is distributed across compute nodes in a redshift cluster. The following example creates a sales table in the tickit database. Create a. Redshift Sort Key Vs Distribution Key.
From github.com
Redshift distribution and sort key default to auto or allow top level Redshift Sort Key Vs Distribution Key The following example creates a sales table in the tickit database. You can specify either a compound or interleaved sort key. A compound sort key is more efficient when query predicates use a prefix, which is a. When the table grows larger, amazon redshift might change the distribution style to key, choosing the primary key (or a column of the.. Redshift Sort Key Vs Distribution Key.
From www.chaosgenius.io
Snowflake vs Redshift Comparison 10 Key Differences (2024) Redshift Sort Key Vs Distribution Key The following example creates a sales table in the tickit database. A compound sort key is more efficient when query predicates use a prefix, which is a. It helps optimize query performance by. Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement from the naive query! You can. Redshift Sort Key Vs Distribution Key.
From coffingdw.com
Amazon Redshift Tutorial Learning Through Puzzles and Examples (Part Redshift Sort Key Vs Distribution Key If the table participates in join operations and has appropriate distkey columns, then we need to decide between key or all distribution styles. A compound sort key is more efficient when query predicates use a prefix, which is a. It helps optimize query performance by. Redshift stores data on disk in sorted order according to the sort key, which has. Redshift Sort Key Vs Distribution Key.
From velog.io
AWS Redshift 02 분산방식Diststyle (ALL, KEY, EVEN, AUTO) Redshift Sort Key Vs Distribution Key Create a table with a distribution key, a compound sort key, and compression. Our query runs on this table in 5 seconds , a 38% improvement over the previous table, and a 2x improvement from the naive query! You can specify either a compound or interleaved sort key. It helps optimize query performance by. Create table activity ( id integer. Redshift Sort Key Vs Distribution Key.