Number Of Partitions In Spark . Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. If it is a column, it will be used as the first partitioning. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Read the input data with the number of partitions, that matches your core count. Returns the number of partitions in rdd. Methods to get the current number of partitions of a dataframe. Numpartitions can be an int to specify the target number of partitions or a column.
from www.turing.com
If it is a column, it will be used as the first partitioning. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Methods to get the current number of partitions of a dataframe. >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Read the input data with the number of partitions, that matches your core count. Returns the number of partitions in rdd. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. Numpartitions can be an int to specify the target number of partitions or a column.
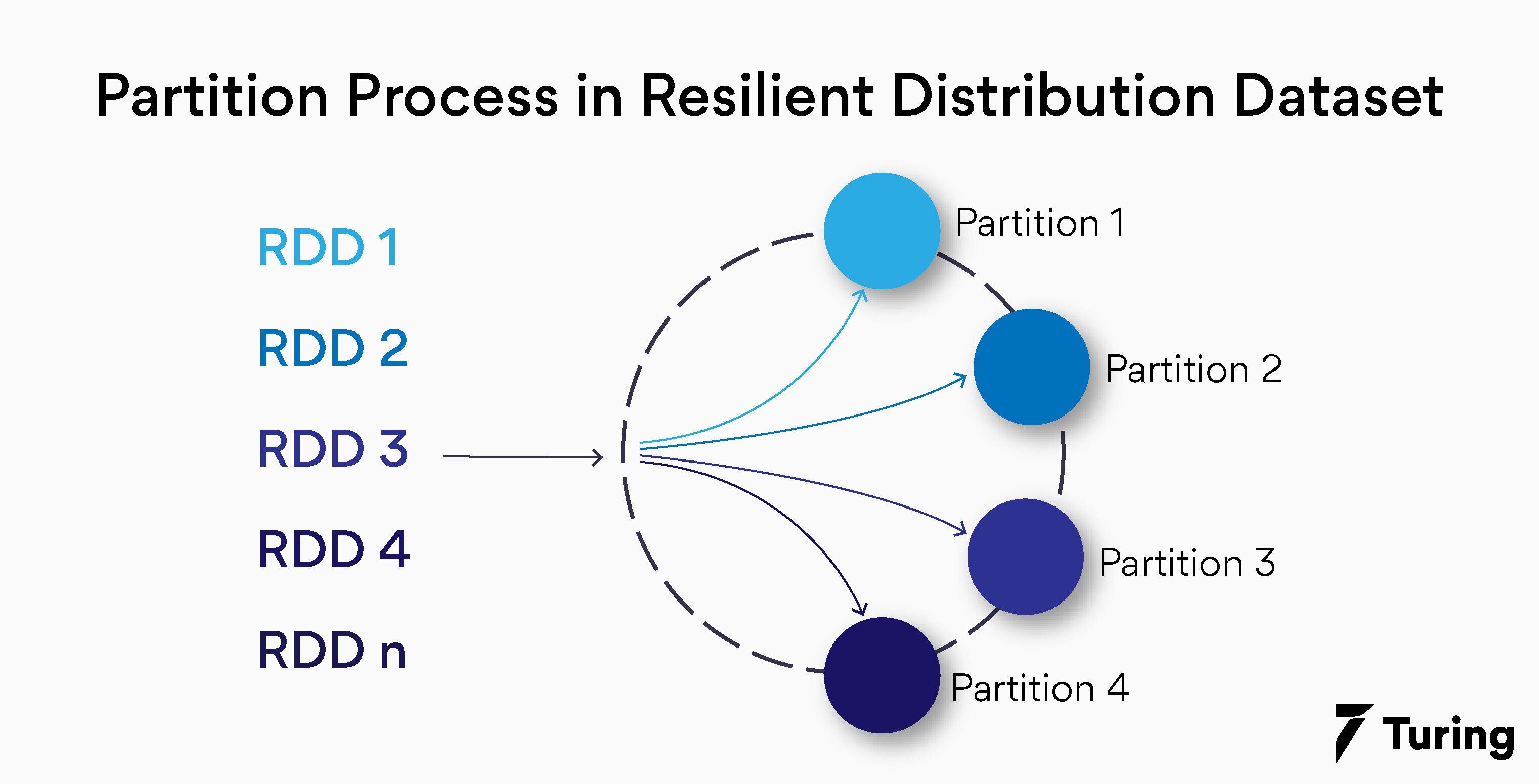
Resilient Distribution Dataset Immutability in Apache Spark
Number Of Partitions In Spark Returns the number of partitions in rdd. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. If it is a column, it will be used as the first partitioning. Read the input data with the number of partitions, that matches your core count. Numpartitions can be an int to specify the target number of partitions or a column. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Returns the number of partitions in rdd. >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Methods to get the current number of partitions of a dataframe.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Number Of Partitions In Spark Numpartitions can be an int to specify the target number of partitions or a column. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Read the input data with the number of partitions, that matches your core count. Pyspark.sql.dataframe.repartition() method. Number Of Partitions In Spark.
From fyodyfjso.blob.core.windows.net
Num Of Partitions In Spark at Minh Moore blog Number Of Partitions In Spark By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Read the input data with the number of partitions, that matches your core count. Numpartitions can be an int to specify the target number of partitions or a column. >>> rdd. Number Of Partitions In Spark.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Number Of Partitions In Spark By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Returns the number of partitions in rdd. Numpartitions can be an int to specify the target number of partitions or a column. Methods. Number Of Partitions In Spark.
From fyojprmwb.blob.core.windows.net
Partition By Key Pyspark at Marjorie Lamontagne blog Number Of Partitions In Spark Read the input data with the number of partitions, that matches your core count. Returns the number of partitions in rdd. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. If it is a column, it will be used as the first partitioning. By default, spark creates one. Number Of Partitions In Spark.
From www.youtube.com
Number of Partitions in Dataframe Spark Tutorial Interview Question Number Of Partitions In Spark By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Returns the number of partitions in rdd. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. Number Of Partitions In Spark.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Number Of Partitions In Spark By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. Read the input data with the number of partitions, that. Number Of Partitions In Spark.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient Number Of Partitions In Spark Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. If it is a column, it will be used as the first partitioning. Methods to get the current number of partitions of a dataframe. By default, spark creates one partition for each block of the file (blocks being 128mb. Number Of Partitions In Spark.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Number Of Partitions In Spark By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Returns the number of partitions in rdd. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. Number Of Partitions In Spark.
From stackoverflow.com
scala Apache spark Number of tasks less than the number of Number Of Partitions In Spark Returns the number of partitions in rdd. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Numpartitions can be an int to specify the target number of partitions or a column. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the. Number Of Partitions In Spark.
From klaojgfcx.blob.core.windows.net
How To Determine Number Of Partitions In Spark at Troy Powell blog Number Of Partitions In Spark Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. Numpartitions can be an int to specify the target number of partitions or a column. Methods to get the current number of partitions of a dataframe. By default, spark creates one partition for each block of the file (blocks. Number Of Partitions In Spark.
From giojwhwzh.blob.core.windows.net
How To Determine The Number Of Partitions In Spark at Alison Kraft blog Number Of Partitions In Spark >>> rdd = sc.parallelize([1, 2, 3, 4], 2). If it is a column, it will be used as the first partitioning. Returns the number of partitions in rdd. Numpartitions can be an int to specify the target number of partitions or a column. By default, spark creates one partition for each block of the file (blocks being 128mb by default. Number Of Partitions In Spark.
From exokeufcv.blob.core.windows.net
Max Number Of Partitions In Spark at Manda Salazar blog Number Of Partitions In Spark If it is a column, it will be used as the first partitioning. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. Methods to get the current number of partitions of a dataframe. Numpartitions can be an int to specify the target number of partitions or a column.. Number Of Partitions In Spark.
From best-practice-and-impact.github.io
Managing Partitions — Spark at the ONS Number Of Partitions In Spark >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Methods to get the current number of partitions of a dataframe. Numpartitions can be an int to specify the target number of partitions or a column. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a. Number Of Partitions In Spark.
From cloud-fundis.co.za
Dynamically Calculating Spark Partitions at Runtime Cloud Fundis Number Of Partitions In Spark Numpartitions can be an int to specify the target number of partitions or a column. If it is a column, it will be used as the first partitioning. >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Read the input data with the number of partitions, that matches your core count. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe. Number Of Partitions In Spark.
From www.researchgate.net
Processing time of PSLIConSpark as the number of partitions is varied Number Of Partitions In Spark Methods to get the current number of partitions of a dataframe. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Numpartitions can be an int to specify the target number of partitions or a column. Pyspark.sql.dataframe.repartition() method is used to. Number Of Partitions In Spark.
From www.projectpro.io
DataFrames number of partitions in spark scala in Databricks Number Of Partitions In Spark Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. Numpartitions can be an int to specify the target number of partitions or a column. Read the input data with the number of partitions, that matches your core count. By default, spark creates one partition for each block of. Number Of Partitions In Spark.
From study.sf.163.com
Spark FAQ number of dynamic partitions created is xxxx 《有数中台FAQ》 Number Of Partitions In Spark By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Read the input data with the number of partitions, that matches your core count. Returns the number of partitions in rdd. >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Numpartitions can. Number Of Partitions In Spark.
From 0x0fff.com
Spark Architecture Shuffle Distributed Systems Architecture Number Of Partitions In Spark >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Read the input data with the number of partitions, that matches your core count. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. Numpartitions can be an int to specify the target number of partitions or a column. Methods to. Number Of Partitions In Spark.
From klaojgfcx.blob.core.windows.net
How To Determine Number Of Partitions In Spark at Troy Powell blog Number Of Partitions In Spark Read the input data with the number of partitions, that matches your core count. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. Returns the number of partitions in rdd. Methods to get the current number of partitions of a dataframe. Numpartitions can be an int to specify. Number Of Partitions In Spark.
From toien.github.io
Spark 分区数量 Kwritin Number Of Partitions In Spark Numpartitions can be an int to specify the target number of partitions or a column. Returns the number of partitions in rdd. If it is a column, it will be used as the first partitioning. >>> rdd = sc.parallelize([1, 2, 3, 4], 2). By default, spark creates one partition for each block of the file (blocks being 128mb by default. Number Of Partitions In Spark.
From toien.github.io
Spark 分区数量 Kwritin Number Of Partitions In Spark Returns the number of partitions in rdd. If it is a column, it will be used as the first partitioning. >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Numpartitions can be an int to specify the target number of partitions or a column. Read the input data with the number of partitions, that matches your core count. Methods to get. Number Of Partitions In Spark.
From giojwhwzh.blob.core.windows.net
How To Determine The Number Of Partitions In Spark at Alison Kraft blog Number Of Partitions In Spark Methods to get the current number of partitions of a dataframe. Read the input data with the number of partitions, that matches your core count. If it is a column, it will be used as the first partitioning. >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of. Number Of Partitions In Spark.
From sparkbyexamples.com
Spark Get Current Number of Partitions of DataFrame Spark By {Examples} Number Of Partitions In Spark Returns the number of partitions in rdd. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. Methods to get the current number of partitions of a dataframe. >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Numpartitions can be an int to specify the target number of partitions or. Number Of Partitions In Spark.
From laptrinhx.com
Determining Number of Partitions in Apache Spark— Part I LaptrinhX Number Of Partitions In Spark By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Returns the number of partitions in rdd. Numpartitions can be an int to specify the target number of partitions or a column. Methods to get the current number of partitions of. Number Of Partitions In Spark.
From giojwhwzh.blob.core.windows.net
How To Determine The Number Of Partitions In Spark at Alison Kraft blog Number Of Partitions In Spark Returns the number of partitions in rdd. Methods to get the current number of partitions of a dataframe. Read the input data with the number of partitions, that matches your core count. If it is a column, it will be used as the first partitioning. Numpartitions can be an int to specify the target number of partitions or a column.. Number Of Partitions In Spark.
From www.turing.com
Resilient Distribution Dataset Immutability in Apache Spark Number Of Partitions In Spark Read the input data with the number of partitions, that matches your core count. Methods to get the current number of partitions of a dataframe. Returns the number of partitions in rdd. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number. Number Of Partitions In Spark.
From medium.com
Managing Partitions with Spark. If you ever wonder why everyone moved Number Of Partitions In Spark Methods to get the current number of partitions of a dataframe. Returns the number of partitions in rdd. >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. By default, spark creates one partition for each block of the file (blocks. Number Of Partitions In Spark.
From stackoverflow.com
optimization Spark AQE drastically reduces number of partitions Number Of Partitions In Spark Numpartitions can be an int to specify the target number of partitions or a column. Read the input data with the number of partitions, that matches your core count. Returns the number of partitions in rdd. Methods to get the current number of partitions of a dataframe. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number. Number Of Partitions In Spark.
From giojwhwzh.blob.core.windows.net
How To Determine The Number Of Partitions In Spark at Alison Kraft blog Number Of Partitions In Spark Read the input data with the number of partitions, that matches your core count. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for. Number Of Partitions In Spark.
From stackoverflow.com
Why is the number of spark streaming tasks different from the Kafka Number Of Partitions In Spark Read the input data with the number of partitions, that matches your core count. Methods to get the current number of partitions of a dataframe. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Numpartitions can be an int to. Number Of Partitions In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Number Of Partitions In Spark >>> rdd = sc.parallelize([1, 2, 3, 4], 2). Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Methods to. Number Of Partitions In Spark.
From klaojgfcx.blob.core.windows.net
How To Determine Number Of Partitions In Spark at Troy Powell blog Number Of Partitions In Spark Read the input data with the number of partitions, that matches your core count. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by. Number Of Partitions In Spark.
From medium.com
Guide to Selection of Number of Partitions while reading Data Files in Number Of Partitions In Spark By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. Methods to get the current number of partitions of a dataframe. Read the input data with the number of partitions, that matches your core count. >>> rdd = sc.parallelize([1, 2, 3,. Number Of Partitions In Spark.
From medium.com
Simple Method to choose Number of Partitions in Spark by Tharun Kumar Number Of Partitions In Spark Read the input data with the number of partitions, that matches your core count. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. Numpartitions can be an int to specify the target number of partitions or a column. Returns the number of partitions in rdd. Methods to get. Number Of Partitions In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Number Of Partitions In Spark Read the input data with the number of partitions, that matches your core count. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name or. Methods to get the current number of partitions of a dataframe. If it is a column, it will be used as the first partitioning. By. Number Of Partitions In Spark.