Partitions Spark Default . by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. we use spark's ui to monitor task times and shuffle read/write times. partitions in spark won’t span across nodes though one node can contains more than one partitions. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. This will give you insights into whether you need to repartition your data. It works by applying a hash function to the keys and then. hash partitioning is the default partitioning strategy in spark.
from leecy.me
by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. hash partitioning is the default partitioning strategy in spark. we use spark's ui to monitor task times and shuffle read/write times. partitions in spark won’t span across nodes though one node can contains more than one partitions. It works by applying a hash function to the keys and then. This will give you insights into whether you need to repartition your data. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,.
Spark partitions A review
Partitions Spark Default spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. hash partitioning is the default partitioning strategy in spark. It works by applying a hash function to the keys and then. partitions in spark won’t span across nodes though one node can contains more than one partitions. This will give you insights into whether you need to repartition your data. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. we use spark's ui to monitor task times and shuffle read/write times. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,.
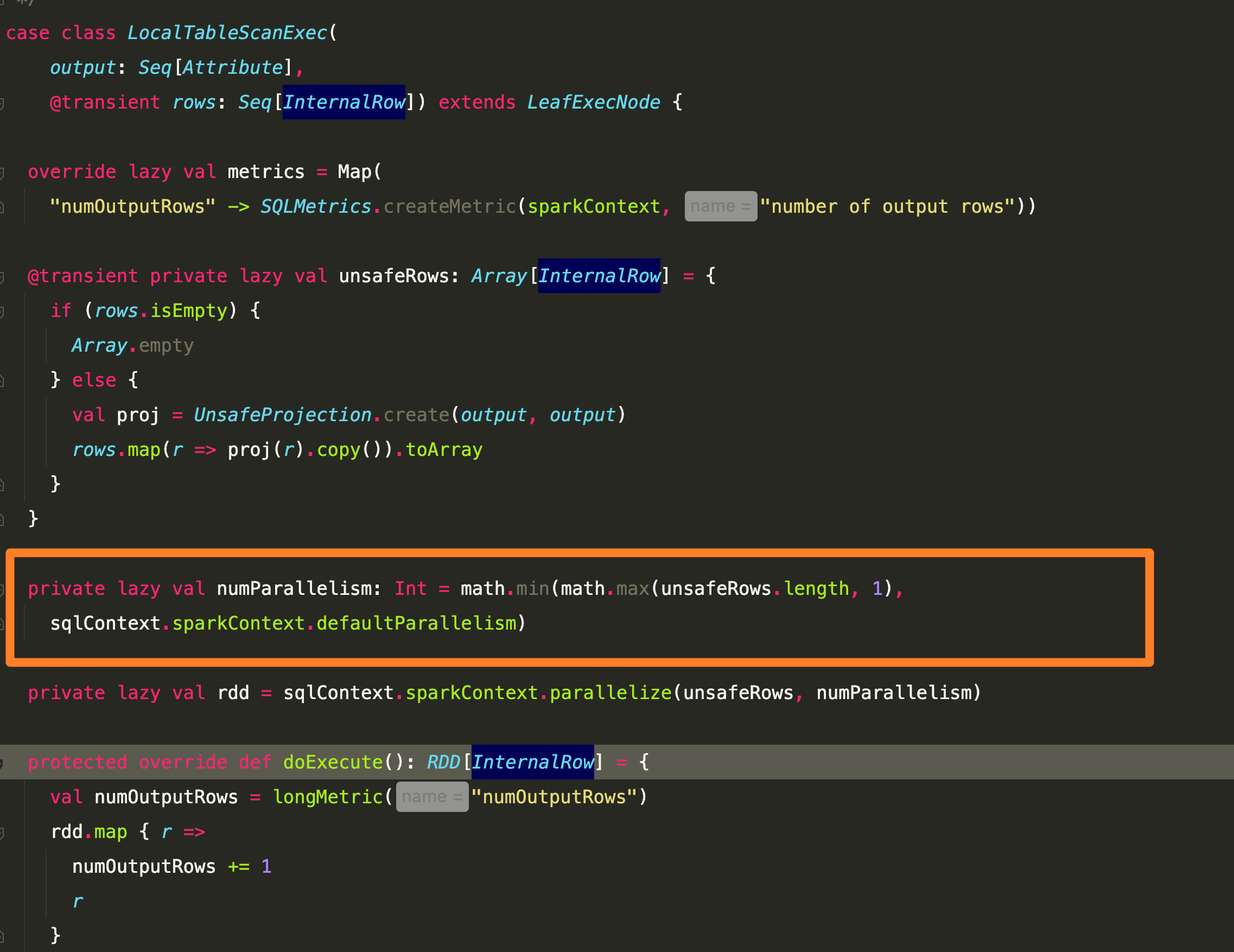
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Partitions Spark Default partitions in spark won’t span across nodes though one node can contains more than one partitions. This will give you insights into whether you need to repartition your data. It works by applying a hash function to the keys and then. by default, spark creates one partition for each block of a file and can be configured with. Partitions Spark Default.
From spaziocodice.com
Spark SQL Partitions and Sizes SpazioCodice Partitions Spark Default It works by applying a hash function to the keys and then. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. partitions in spark won’t span across nodes though one node can contains more than one partitions. by default, spark creates one partition for each block of a file and can. Partitions Spark Default.
From medium.com
Managing Spark Partitions. How data is partitioned and when do you Partitions Spark Default It works by applying a hash function to the keys and then. hash partitioning is the default partitioning strategy in spark. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. we use spark's ui to monitor task times and shuffle read/write times. partitions in spark won’t span across nodes though. Partitions Spark Default.
From leecy.me
Spark partitions A review Partitions Spark Default we use spark's ui to monitor task times and shuffle read/write times. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. partitions in spark won’t span across nodes though one node can contains more than one partitions. by default, spark creates one partition for each block of a file and. Partitions Spark Default.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders Partitions Spark Default It works by applying a hash function to the keys and then. hash partitioning is the default partitioning strategy in spark. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. partitions in spark won’t span across nodes though one node can contains more than one partitions. by default, spark creates. Partitions Spark Default.
From www.youtube.com
Spark Application Partition By in Spark Chapter 2 LearntoSpark Partitions Spark Default by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. partitions in spark won’t span across nodes though one node can contains more than one partitions. It works by applying a hash function to the keys and then. This will give you insights into whether you need. Partitions Spark Default.
From www.simplilearn.com
Spark Parallelize The Essential Element of Spark Partitions Spark Default partitions in spark won’t span across nodes though one node can contains more than one partitions. hash partitioning is the default partitioning strategy in spark. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. This will give you insights into whether you need to repartition. Partitions Spark Default.
From dzone.com
Dynamic Partition Pruning in Spark 3.0 DZone Partitions Spark Default we use spark's ui to monitor task times and shuffle read/write times. It works by applying a hash function to the keys and then. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. spark.default.parallelism is the default number of partitions in rdd s returned by. Partitions Spark Default.
From www.youtube.com
How to create partitions with parquet using spark YouTube Partitions Spark Default by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. It works by applying a hash function to the keys and then. This will give you insights into whether you need to. Partitions Spark Default.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Partitions Spark Default partitions in spark won’t span across nodes though one node can contains more than one partitions. hash partitioning is the default partitioning strategy in spark. It works by applying a hash function to the keys and then. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions. Partitions Spark Default.
From cookinglove.com
Spark partition size limit Partitions Spark Default hash partitioning is the default partitioning strategy in spark. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. It works by applying a hash function to the keys and then. This will give you insights into whether you need to repartition your data. partitions in. Partitions Spark Default.
From sparkbyexamples.com
Difference between spark.sql.shuffle.partitions vs spark.default Partitions Spark Default spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. partitions in spark won’t span across nodes though one node can contains more than one partitions. hash partitioning is the default partitioning strategy in spark. It works by applying a hash function to the keys and then. we use spark's ui. Partitions Spark Default.
From cloud-fundis.co.za
Dynamically Calculating Spark Partitions at Runtime Cloud Fundis Partitions Spark Default partitions in spark won’t span across nodes though one node can contains more than one partitions. we use spark's ui to monitor task times and shuffle read/write times. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. It works by applying a hash function to. Partitions Spark Default.
From exokeufcv.blob.core.windows.net
Max Number Of Partitions In Spark at Manda Salazar blog Partitions Spark Default partitions in spark won’t span across nodes though one node can contains more than one partitions. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. This will give you insights into whether you need to repartition your data. spark.default.parallelism is the default number of partitions. Partitions Spark Default.
From medium.com
Managing Spark Partitions. How data is partitioned and when do you Partitions Spark Default partitions in spark won’t span across nodes though one node can contains more than one partitions. hash partitioning is the default partitioning strategy in spark. It works by applying a hash function to the keys and then. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions. Partitions Spark Default.
From andr83.io
How to work with Hive tables with a lot of partitions from Spark Partitions Spark Default partitions in spark won’t span across nodes though one node can contains more than one partitions. It works by applying a hash function to the keys and then. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. spark.default.parallelism is the default number of partitions in. Partitions Spark Default.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Partitions Spark Default partitions in spark won’t span across nodes though one node can contains more than one partitions. This will give you insights into whether you need to repartition your data. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. we use spark's ui to monitor task. Partitions Spark Default.
From www.youtube.com
Spark Partitioning YouTube Partitions Spark Default It works by applying a hash function to the keys and then. partitions in spark won’t span across nodes though one node can contains more than one partitions. hash partitioning is the default partitioning strategy in spark. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions. Partitions Spark Default.
From sparkbyexamples.com
Spark Partitioning & Partition Understanding Spark By {Examples} Partitions Spark Default spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. It works by applying a hash function to the keys and then. we use spark's ui to monitor task times and shuffle read/write times. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism. Partitions Spark Default.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient Partitions Spark Default hash partitioning is the default partitioning strategy in spark. partitions in spark won’t span across nodes though one node can contains more than one partitions. It works by applying a hash function to the keys and then. we use spark's ui to monitor task times and shuffle read/write times. This will give you insights into whether you. Partitions Spark Default.
From www.youtube.com
How to partition and write DataFrame in Spark without deleting Partitions Spark Default spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. we use spark's ui to monitor task times and shuffle read/write times. hash partitioning is the default partitioning strategy in spark. This will give you insights into whether you need to repartition your data. by default, spark creates one partition for. Partitions Spark Default.
From discover.qubole.com
Introducing Dynamic Partition Pruning Optimization for Spark Partitions Spark Default partitions in spark won’t span across nodes though one node can contains more than one partitions. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. we use spark's ui to monitor task times and shuffle read/write times. This will give you insights into whether you need to repartition your data. It. Partitions Spark Default.
From www.youtube.com
How to find Data skewness in spark / How to get count of rows from each Partitions Spark Default It works by applying a hash function to the keys and then. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. hash partitioning is the default partitioning strategy in spark. partitions in spark won’t span across nodes though one node can contains more than one partitions. This will give you insights. Partitions Spark Default.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Partitions Spark Default partitions in spark won’t span across nodes though one node can contains more than one partitions. we use spark's ui to monitor task times and shuffle read/write times. hash partitioning is the default partitioning strategy in spark. This will give you insights into whether you need to repartition your data. It works by applying a hash function. Partitions Spark Default.
From www.youtube.com
Apache Spark Dynamic Partition Pruning Spark Tutorial Part 11 YouTube Partitions Spark Default by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. partitions in spark won’t span across nodes though one node can contains more than one partitions. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. It works by applying a. Partitions Spark Default.
From laptrinhx.com
Managing Partitions Using Spark Dataframe Methods LaptrinhX / News Partitions Spark Default partitions in spark won’t span across nodes though one node can contains more than one partitions. This will give you insights into whether you need to repartition your data. we use spark's ui to monitor task times and shuffle read/write times. by default, spark creates one partition for each block of a file and can be configured. Partitions Spark Default.
From www.youtube.com
Apache Spark Data Partitioning Example YouTube Partitions Spark Default This will give you insights into whether you need to repartition your data. hash partitioning is the default partitioning strategy in spark. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. It works by applying a hash function to the keys and then. by default, spark creates one partition for each. Partitions Spark Default.
From stackoverflow.com
understanding spark.default.parallelism Stack Overflow Partitions Spark Default spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. hash partitioning is the default partitioning strategy in spark. partitions in spark won’t span across nodes though one node can contains more than one partitions. we use spark's ui to monitor task times and shuffle read/write times. by default, spark. Partitions Spark Default.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Partitions Spark Default we use spark's ui to monitor task times and shuffle read/write times. This will give you insights into whether you need to repartition your data. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. partitions in spark won’t span across nodes though one node can contains more than one partitions. . Partitions Spark Default.
From izhangzhihao.github.io
Spark The Definitive Guide In Short — MyNotes Partitions Spark Default This will give you insights into whether you need to repartition your data. we use spark's ui to monitor task times and shuffle read/write times. hash partitioning is the default partitioning strategy in spark. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. partitions. Partitions Spark Default.
From www.youtube.com
Why should we partition the data in spark? YouTube Partitions Spark Default It works by applying a hash function to the keys and then. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. hash partitioning is the default partitioning strategy in spark. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,.. Partitions Spark Default.
From cookinglove.com
Spark partition size limit Partitions Spark Default we use spark's ui to monitor task times and shuffle read/write times. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. It works by applying a hash function to the keys and then. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism. Partitions Spark Default.
From nebash.com
What's new in Apache Spark 3.0 dynamic partition pruning (2023) Partitions Spark Default we use spark's ui to monitor task times and shuffle read/write times. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. partitions in spark won’t span across nodes though one node can contains more than one partitions. This will give you insights into whether you need to repartition your data. . Partitions Spark Default.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Partitions Spark Default This will give you insights into whether you need to repartition your data. by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. we use spark's ui to monitor task times and shuffle read/write times. It works by applying a hash function to the keys and then.. Partitions Spark Default.
From 0x0fff.com
Spark Architecture Shuffle Distributed Systems Architecture Partitions Spark Default by default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. spark.default.parallelism is the default number of partitions in rdd s returned by transformations like join,. This will give you insights into whether you need to repartition your data. partitions in spark won’t span across nodes though. Partitions Spark Default.