From www.slideserve.com
PPT Parallel Data Structures PowerPoint Presentation, free download Zero Data Parallel Deepspeed enables a flexible combination of three parallelism. Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From docs.aws.amazon.com
Introduction to the SageMaker distributed data parallelism library Zero Data Parallel Deepspeed enables a flexible combination of three parallelism. Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From bytewax.io
Data Parallel, Task Parallel, and Agent Actor Architectures bytewax Zero Data Parallel Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Deepspeed enables a flexible combination of three parallelism. Trillion parameter model training with 3d parallelism: Zero Data Parallel.
From www.slideserve.com
PPT Introduction to Parallel Computing PowerPoint Presentation, free Zero Data Parallel Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Deepspeed enables a flexible combination of three parallelism. Zero Data Parallel.
From ml-alchemy.medium.com
Part 1 A Brief Guide to the Data Parallel Algorithm by The Machine Zero Data Parallel Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Deepspeed enables a flexible combination of three parallelism. Trillion parameter model training with 3d parallelism: Zero Data Parallel.
From www.mishalaskin.com
Sharding Large Models with Tensor Parallelism Zero Data Parallel Deepspeed enables a flexible combination of three parallelism. Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Trillion parameter model training with 3d parallelism: Zero Data Parallel.
From www.slideserve.com
PPT Evaluation of DataParallel Splitting Approaches for H.264 Zero Data Parallel Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Trillion parameter model training with 3d parallelism: Deepspeed enables a flexible combination of three parallelism. Zero Data Parallel.
From www.slideserve.com
PPT Data Parallel Pattern PowerPoint Presentation, free download ID Zero Data Parallel Trillion parameter model training with 3d parallelism: Deepspeed enables a flexible combination of three parallelism. Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From studylib.net
Parallel Data Structures Zero Data Parallel Deepspeed enables a flexible combination of three parallelism. Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Trillion parameter model training with 3d parallelism: Zero Data Parallel.
From slideplayer.com
Data Parallel Algorithms ppt download Zero Data Parallel Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Deepspeed enables a flexible combination of three parallelism. Zero Data Parallel.
From www.linkedin.com
Revolutionizing Heterogeneous Computing with Data Parallel C++ and the Zero Data Parallel Trillion parameter model training with 3d parallelism: Deepspeed enables a flexible combination of three parallelism. Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From www.vrogue.co
Data Parallel Distributed Training Of Deep Learning M vrogue.co Zero Data Parallel Trillion parameter model training with 3d parallelism: Deepspeed enables a flexible combination of three parallelism. Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From www.codementor.io
Machine Learning How to Build Scalable Machine Learning Models Zero Data Parallel Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Deepspeed enables a flexible combination of three parallelism. Trillion parameter model training with 3d parallelism: Zero Data Parallel.
From www.deepspeed.ai
Pipeline Parallelism DeepSpeed Zero Data Parallel Trillion parameter model training with 3d parallelism: Deepspeed enables a flexible combination of three parallelism. Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From lightning.ai
How to Enable Native Fully Sharded Data Parallel in PyTorch Zero Data Parallel Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Deepspeed enables a flexible combination of three parallelism. Zero Data Parallel.
From paperswithcode.com
An Overview of Distributed Methods Papers With Code Zero Data Parallel Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Deepspeed enables a flexible combination of three parallelism. Zero Data Parallel.
From colossalai.org
Paradigms of Parallelism ColossalAI Zero Data Parallel Deepspeed enables a flexible combination of three parallelism. Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From paperswithcode.com
An Overview of Data Parallel Methods Papers With Code Zero Data Parallel Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Deepspeed enables a flexible combination of three parallelism. Zero Data Parallel.
From www.microsoft.com
DeepSpeed Extremescale model training for everyone Microsoft Research Zero Data Parallel Deepspeed enables a flexible combination of three parallelism. Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From siboehm.com
DataParallel Distributed Training of Deep Learning Models Zero Data Parallel Trillion parameter model training with 3d parallelism: Deepspeed enables a flexible combination of three parallelism. Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From docs.aws.amazon.com
How Tensor Parallelism Works Amazon SageMaker Zero Data Parallel Deepspeed enables a flexible combination of three parallelism. Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Trillion parameter model training with 3d parallelism: Zero Data Parallel.
From docs.chainer.org
Overview — Chainer 7.8.1 documentation Zero Data Parallel Trillion parameter model training with 3d parallelism: Deepspeed enables a flexible combination of three parallelism. Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From slideplayer.com
Data Parallel Algorithms ppt download Zero Data Parallel Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Deepspeed enables a flexible combination of three parallelism. Zero Data Parallel.
From czxttkl.com
Data Parallelism and Model Parallelism czxttkl Zero Data Parallel Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Trillion parameter model training with 3d parallelism: Deepspeed enables a flexible combination of three parallelism. Zero Data Parallel.
From www.xdat.org
XDAT A free parallel coordinates software tool Zero Data Parallel Deepspeed enables a flexible combination of three parallelism. Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From siboehm.com
DataParallel Distributed Training of Deep Learning Models Zero Data Parallel Trillion parameter model training with 3d parallelism: Deepspeed enables a flexible combination of three parallelism. Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From www.telesens.co
Distributed data parallel training using Pytorch on AWS Telesens Zero Data Parallel Deepspeed enables a flexible combination of three parallelism. Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
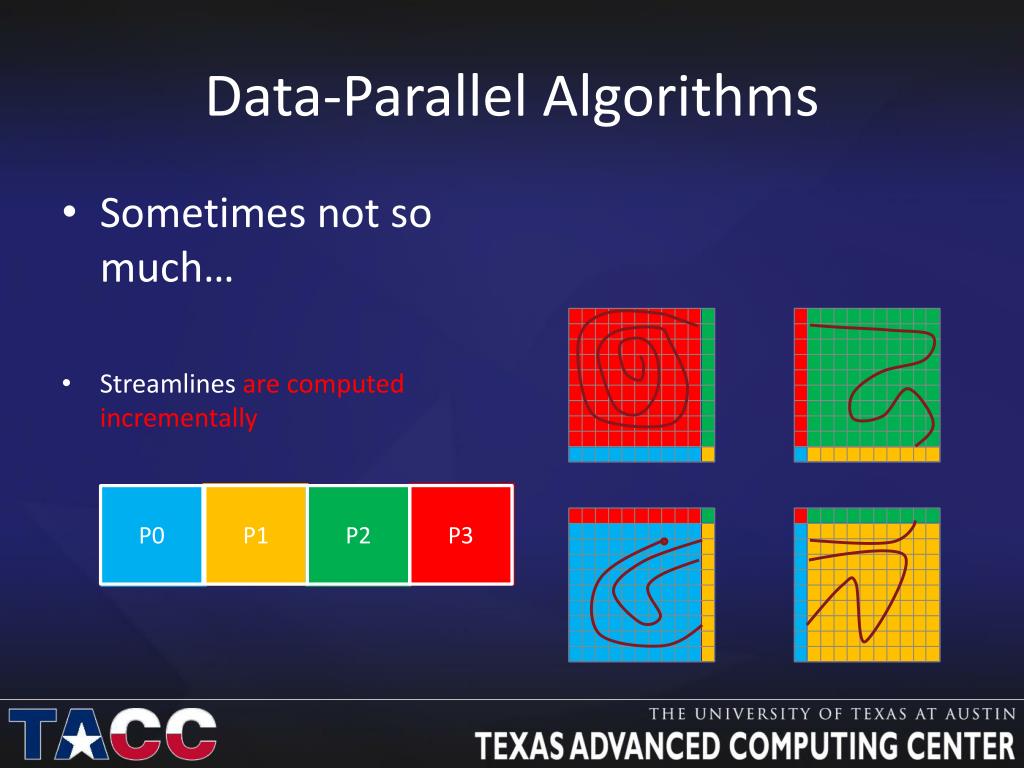
From www.slideserve.com
PPT Parallel Visualization At TACC PowerPoint Presentation, free Zero Data Parallel Deepspeed enables a flexible combination of three parallelism. Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From www.researchgate.net
Parallel Data Structure Download Scientific Diagram Zero Data Parallel Trillion parameter model training with 3d parallelism: Deepspeed enables a flexible combination of three parallelism. Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From github.com
Model, Data, Tensor, Pipeline Parallelism\n Zero Data Parallel Deepspeed enables a flexible combination of three parallelism. Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From ppt-online.org
Task and Data Parallelism RealWorld Examples презентация онлайн Zero Data Parallel Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Deepspeed enables a flexible combination of three parallelism. Trillion parameter model training with 3d parallelism: Zero Data Parallel.
From docs.aws.amazon.com
Introduction to Model Parallelism Amazon SageMaker Zero Data Parallel Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Trillion parameter model training with 3d parallelism: Deepspeed enables a flexible combination of three parallelism. Zero Data Parallel.
From www.researchgate.net
Example distributed training configuration with 3D parallelism, with 2 Zero Data Parallel Trillion parameter model training with 3d parallelism: Deepspeed enables a flexible combination of three parallelism. Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Zero Data Parallel.
From www.vrogue.co
Understanding Data Parallelism In Machine Learning Te vrogue.co Zero Data Parallel Trillion parameter model training with 3d parallelism: Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Deepspeed enables a flexible combination of three parallelism. Zero Data Parallel.
From www.scaleoutsoftware.com
DataParallel Computing Better than Parallel Query ScaleOut Software Zero Data Parallel Zero redundancy optimizer (zero) is a sharded data parallel method for distributed training. Trillion parameter model training with 3d parallelism: Deepspeed enables a flexible combination of three parallelism. Zero Data Parallel.