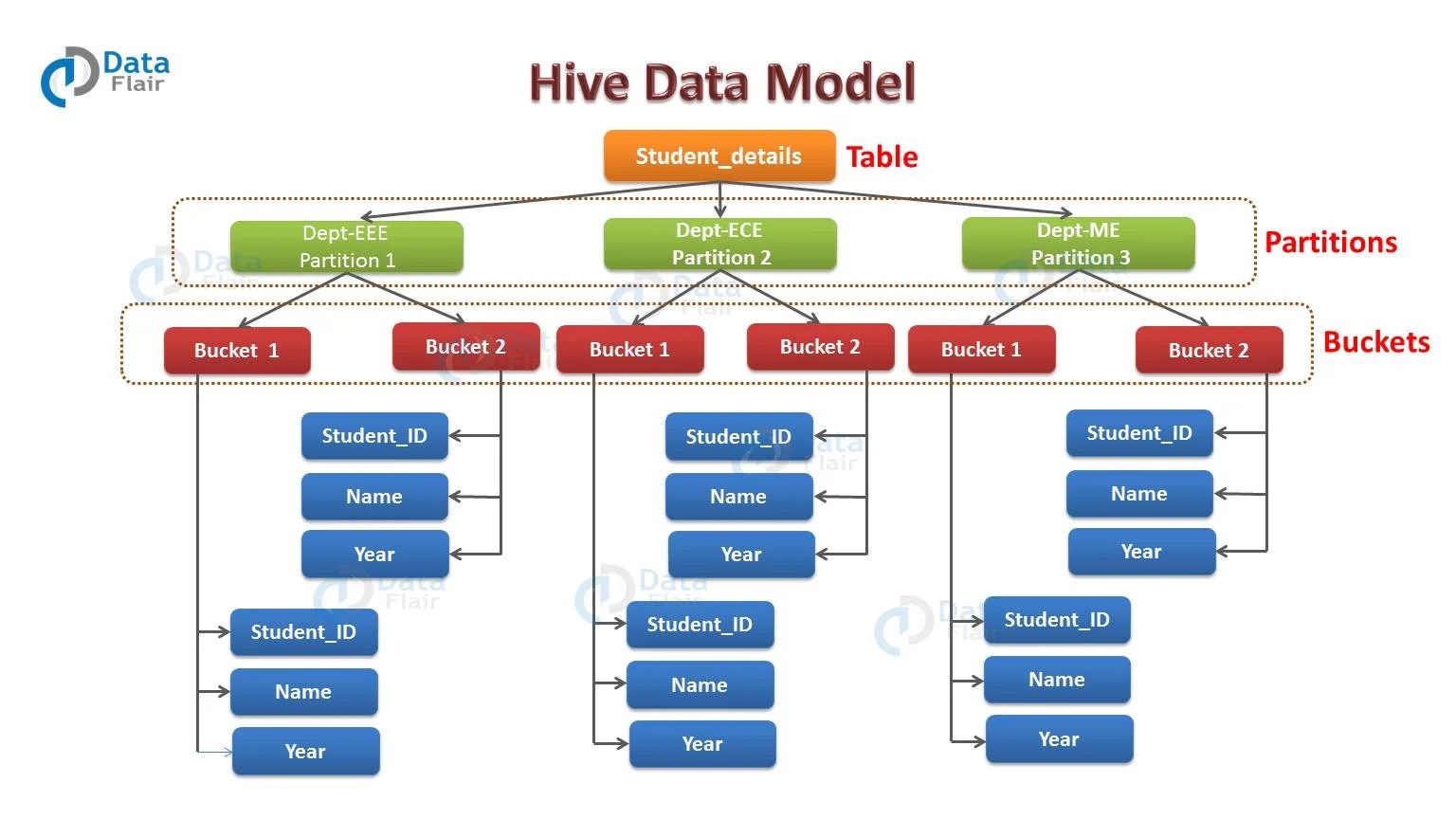
Difference Between Partitioning And Bucketing In Spark . Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Let’s delve into these concepts and see how they work with some. Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing.
from data-flair.training
Let’s delve into these concepts and see how they work with some. Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing. Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns.
Hive Partitioning vs Bucketing Advantages and Disadvantages DataFlair
Difference Between Partitioning And Bucketing In Spark Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing. Let’s delve into these concepts and see how they work with some. Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing. Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in.
From www.projectpro.io
How Data Partitioning in Spark helps achieve more parallelism? Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Let’s delve into these concepts and see how. Difference Between Partitioning And Bucketing In Spark.
From www.semanticscholar.org
Figure 1 from Partitioning and Bucketing Techniques to Speed up Query Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Partitioning and bucketing in pyspark refer to two different. Difference Between Partitioning And Bucketing In Spark.
From datamasterylab.com
Partitioning Vs. Bucketing Key Characteristics And Differences Data Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Let’s delve into these concepts and see how. Difference Between Partitioning And Bucketing In Spark.
From medium.com
Partitioning vs Bucketing — In Apache Spark by Siddharth Ghosh Medium Difference Between Partitioning And Bucketing In Spark Let’s delve into these concepts and see how they work with some. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Partitioning involves dividing your dataset into directories or subdirectories based on one. Difference Between Partitioning And Bucketing In Spark.
From python.plainenglish.io
What is Partitioning vs Bucketing in Apache Hive? (Partitioning vs Difference Between Partitioning And Bucketing In Spark Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Let’s delve into these concepts and see how they work with some. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the. Difference Between Partitioning And Bucketing In Spark.
From thepythoncoding.blogspot.com
Coding with python What is the difference between 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗶𝗻𝗴 𝗮𝗻𝗱 Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Let’s delve into these concepts and see how they work with some. Apache spark’s bucketby() is a method of the dataframewriter class which is used to. Difference Between Partitioning And Bucketing In Spark.
From newbedev.com
Why is Spark saveAsTable with bucketBy creating thousands of files? Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the. Difference Between Partitioning And Bucketing In Spark.
From exybatjil.blob.core.windows.net
Diff Between Bucketing And Partitioning at Sara Leath blog Difference Between Partitioning And Bucketing In Spark Let’s delve into these concepts and see how they work with some. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Partitioning and bucketing are two powerful techniques that can significantly improve query performance. Difference Between Partitioning And Bucketing In Spark.
From exoopiifn.blob.core.windows.net
Bucketing In Hive And Spark at Ethel Hanselman blog Difference Between Partitioning And Bucketing In Spark Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Apache spark’s bucketby() is a method of the dataframewriter class which is. Difference Between Partitioning And Bucketing In Spark.
From www.linkedin.com
Toni Beverin on LinkedIn Spark partitioning and bucketing are crucial Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Let’s delve into these concepts and see how they work with some. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing,. Difference Between Partitioning And Bucketing In Spark.
From medium.com
Partitioning vs Bucketing in Spark and Hive by Shivani Panchiwala Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Let’s delve into these concepts and see how they work with some. Apache spark’s bucketby() is a method of the dataframewriter class which is used to. Difference Between Partitioning And Bucketing In Spark.
From kontext.tech
Spark Bucketing and Bucket Pruning Explained Difference Between Partitioning And Bucketing In Spark Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on. Difference Between Partitioning And Bucketing In Spark.
From quadexcel.com
Partition vs bucketing Spark and Hive Interview Question Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on. Difference Between Partitioning And Bucketing In Spark.
From www.newsletter.swirlai.com
SAI 26 Partitioning and Bucketing in Spark (Part 1) Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing. Partitioning and bucketing are two different techniques in apache spark for optimizing. Difference Between Partitioning And Bucketing In Spark.
From www.newsletter.swirlai.com
SAI 26 Partitioning and Bucketing in Spark (Part 1) Difference Between Partitioning And Bucketing In Spark Let’s delve into these concepts and see how they work with some. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Partitioning involves dividing your dataset into directories or subdirectories based on one. Difference Between Partitioning And Bucketing In Spark.
From medium.com
Apache Spark SQL Partitioning & Bucketing by Sandhiya M Medium Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing. Difference Between Partitioning And Bucketing In Spark.
From www.youtube.com
Partitioning and bucketing in Spark Lec9 Practical video YouTube Difference Between Partitioning And Bucketing In Spark Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing. Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in. Difference Between Partitioning And Bucketing In Spark.
From www.newsletter.swirlai.com
SAI 26 Partitioning and Bucketing in Spark (Part 1) Difference Between Partitioning And Bucketing In Spark Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Let’s delve into these concepts and see how they work with some. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive.. Difference Between Partitioning And Bucketing In Spark.
From www.youtube.com
Ch.0234 Partitioning vs Bucketing Data Modeling YouTube Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Let’s delve into these concepts and see how they work with some. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition. Difference Between Partitioning And Bucketing In Spark.
From blog.det.life
Data Partitioning and Bucketing Examples and Best Practices by Difference Between Partitioning And Bucketing In Spark Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Let’s delve into these concepts and see how they work with some. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in. Difference Between Partitioning And Bucketing In Spark.
From medium.com
Apache Spark Bucketing and Partitioning. by Jay Nerd For Tech Medium Difference Between Partitioning And Bucketing In Spark Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Apache spark’s bucketby() is a method of the dataframewriter. Difference Between Partitioning And Bucketing In Spark.
From thoughtfulworks.dev
Partitions and Bucketing in Spark thoughtful works Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing. Partitioning involves dividing your dataset into directories or subdirectories based. Difference Between Partitioning And Bucketing In Spark.
From medium.com
Spark Partitioning vs Bucketing partitionBy vs bucketBy Medium Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified. Difference Between Partitioning And Bucketing In Spark.
From sparkbyexamples.com
Hive Partitioning vs Bucketing with Examples? Spark By {Examples} Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Partitioning and bucketing are two powerful techniques that can significantly. Difference Between Partitioning And Bucketing In Spark.
From www.youtube.com
Partitioning and Bucketing in Hive 1 YouTube Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing. Difference Between Partitioning And Bucketing In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column. Difference Between Partitioning And Bucketing In Spark.
From medium.com
Partitioning vs Bucketing — In Apache Spark by Siddharth Ghosh Medium Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing. Let’s delve into these concepts and see how they work with some. Partitioning. Difference Between Partitioning And Bucketing In Spark.
From www.newsletter.swirlai.com
SAI 26 Partitioning and Bucketing in Spark (Part 1) Difference Between Partitioning And Bucketing In Spark Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Partitioning and bucketing are two different techniques in apache spark for optimizing. Difference Between Partitioning And Bucketing In Spark.
From sparkbyexamples.com
Apache Hive Archives Page 3 of 5 Spark By {Examples} Difference Between Partitioning And Bucketing In Spark Let’s delve into these concepts and see how they work with some. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing. Partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Partitioning. Difference Between Partitioning And Bucketing In Spark.
From www.okera.com
Bucketing in Hive Hive Bucketing Example With Okera Okera Difference Between Partitioning And Bucketing In Spark Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing. Let’s delve into these concepts and see how they work with some.. Difference Between Partitioning And Bucketing In Spark.
From bigdatansql.com
Bucketing_With_Partitioning Big Data and SQL Difference Between Partitioning And Bucketing In Spark Let’s delve into these concepts and see how they work with some. Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing,. Difference Between Partitioning And Bucketing In Spark.
From www.scaler.com
The Differences Between Hive Partitioning And Bucketing Scaler Topics Difference Between Partitioning And Bucketing In Spark Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in spark and hive. Partitioning and bucketing in pyspark refer to two different techniques for organizing. Difference Between Partitioning And Bucketing In Spark.
From data-flair.training
Hive Partitioning vs Bucketing Advantages and Disadvantages DataFlair Difference Between Partitioning And Bucketing In Spark Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Let’s delve into these concepts and see how they work with some. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Partitioning and bucketing are two powerful techniques that can significantly improve query performance in. Difference Between Partitioning And Bucketing In Spark.
From www.youtube.com
Spark SQL Bucketing at Facebook Cheng Su (Facebook) YouTube Difference Between Partitioning And Bucketing In Spark Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing. Partitioning involves dividing your dataset into directories or subdirectories based on one or more columns. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance. Difference Between Partitioning And Bucketing In Spark.
From www.youtube.com
Why should we partition the data in spark? YouTube Difference Between Partitioning And Bucketing In Spark Apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the number of buckets specified and on the bucketing column while writing. Partitioning and bucketing are two different techniques in apache spark for optimizing the performance of data processing, particularly in. Let’s delve into these concepts and see how they work. Difference Between Partitioning And Bucketing In Spark.