Drop Multiple Partitions In Spark . Alter table my_table drop partition(p_col > 0) // does. // deletes all data, but keeps partitions in metastore. We have another problem — there are a lot of recommendations to limit amount of partitions in about 10000. Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c). Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: With this clause, the drop partitions command will only execute if the partition exists in the hive table. This is a key area. On spark, hive, and small files: Get the list of partitions and conditionally filter them. Either drop the individual partitions one by one, or pass them as a.
from erikerlandson.github.io
Either drop the individual partitions one by one, or pass them as a. Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c). Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: Alter table my_table drop partition(p_col > 0) // does. Get the list of partitions and conditionally filter them. On spark, hive, and small files: We have another problem — there are a lot of recommendations to limit amount of partitions in about 10000. // deletes all data, but keeps partitions in metastore. With this clause, the drop partitions command will only execute if the partition exists in the hive table. This is a key area.
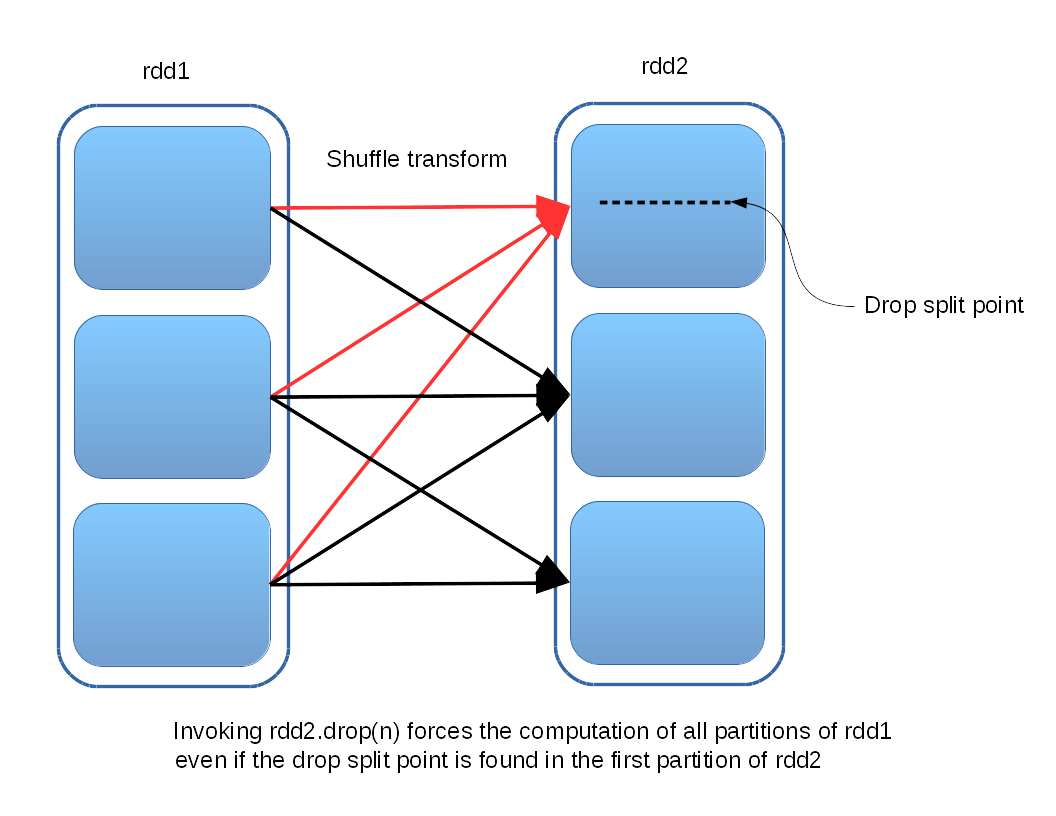
Some Implications of Supporting the Scala drop Method for Spark RDDs
Drop Multiple Partitions In Spark Get the list of partitions and conditionally filter them. This is a key area. Either drop the individual partitions one by one, or pass them as a. // deletes all data, but keeps partitions in metastore. Alter table my_table drop partition(p_col > 0) // does. On spark, hive, and small files: Get the list of partitions and conditionally filter them. With this clause, the drop partitions command will only execute if the partition exists in the hive table. We have another problem — there are a lot of recommendations to limit amount of partitions in about 10000. Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c). Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect:
From sparkbyexamples.com
How to Update or Drop a Hive Partition? Spark By {Examples} Drop Multiple Partitions In Spark On spark, hive, and small files: Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c). Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: Alter table my_table drop partition(p_col > 0) // does.. Drop Multiple Partitions In Spark.
From leecy.me
Spark partitions A review Drop Multiple Partitions In Spark With this clause, the drop partitions command will only execute if the partition exists in the hive table. Get the list of partitions and conditionally filter them. Alter table my_table drop partition(p_col > 0) // does. Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date,. Drop Multiple Partitions In Spark.
From www.projectpro.io
How Data Partitioning in Spark helps achieve more parallelism? Drop Multiple Partitions In Spark Alter table my_table drop partition(p_col > 0) // does. This is a key area. Get the list of partitions and conditionally filter them. With this clause, the drop partitions command will only execute if the partition exists in the hive table. Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect:. Drop Multiple Partitions In Spark.
From blog.flowpoint.ai
[solved] Is there a way to drop multiple partitions of a BigQuery table Drop Multiple Partitions In Spark Either drop the individual partitions one by one, or pass them as a. // deletes all data, but keeps partitions in metastore. Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: With this clause, the drop partitions command will only execute if the partition exists in the hive table. Hive. Drop Multiple Partitions In Spark.
From www.youtube.com
How to partition and write DataFrame in Spark without deleting Drop Multiple Partitions In Spark We have another problem — there are a lot of recommendations to limit amount of partitions in about 10000. Either drop the individual partitions one by one, or pass them as a. On spark, hive, and small files: With this clause, the drop partitions command will only execute if the partition exists in the hive table. Alter table my_table drop. Drop Multiple Partitions In Spark.
From erikerlandson.github.io
Some Implications of Supporting the Scala drop Method for Spark RDDs Drop Multiple Partitions In Spark This is a key area. Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: // deletes all data, but keeps partitions in metastore. Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c). With. Drop Multiple Partitions In Spark.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Drop Multiple Partitions In Spark We have another problem — there are a lot of recommendations to limit amount of partitions in about 10000. This is a key area. Alter table my_table drop partition(p_col > 0) // does. Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c). Welcome. Drop Multiple Partitions In Spark.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders Drop Multiple Partitions In Spark Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: Get the list of partitions and conditionally filter them. This is a key area. We have another problem — there are a lot of recommendations to limit amount of partitions in about 10000. Alter table my_table drop partition(p_col > 0) //. Drop Multiple Partitions In Spark.
From www.researchgate.net
(PDF) Spark as Data Supplier for MPI Deep Learning Processes Drop Multiple Partitions In Spark On spark, hive, and small files: Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: Alter table my_table drop partition(p_col > 0) // does. We have another problem — there are a lot of recommendations to limit amount of partitions in about 10000. Either drop the individual partitions one by. Drop Multiple Partitions In Spark.
From sparkbyexamples.com
Spark Partitioning & Partition Understanding Spark By {Examples} Drop Multiple Partitions In Spark Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c). On spark, hive, and small files: Get the list of partitions and conditionally filter them. // deletes all data, but keeps partitions in metastore. With this clause, the drop partitions command will only execute. Drop Multiple Partitions In Spark.
From www.youtube.com
How to find Data skewness in spark / How to get count of rows from each Drop Multiple Partitions In Spark Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c). Alter table my_table drop partition(p_col > 0) // does. Get the list of partitions and conditionally filter them. With this clause, the drop partitions command will only execute if the partition exists in the. Drop Multiple Partitions In Spark.
From www.youtube.com
Why should we partition the data in spark? YouTube Drop Multiple Partitions In Spark Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c). On spark, hive, and small files: Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: Either drop the individual partitions one by one, or. Drop Multiple Partitions In Spark.
From dzone.com
Dynamic Partition Pruning in Spark 3.0 DZone Drop Multiple Partitions In Spark Alter table my_table drop partition(p_col > 0) // does. We have another problem — there are a lot of recommendations to limit amount of partitions in about 10000. Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: Hive partitions are used to split the larger table into several smaller parts. Drop Multiple Partitions In Spark.
From cloud-fundis.co.za
Dynamically Calculating Spark Partitions at Runtime Cloud Fundis Drop Multiple Partitions In Spark Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: Either drop the individual partitions one by one, or pass them as a. With this clause, the drop partitions command will only execute if the partition exists in the hive table. Get the list of partitions and conditionally filter them. This. Drop Multiple Partitions In Spark.
From sparkbyexamples.com
Get the Size of Each Spark Partition Spark By {Examples} Drop Multiple Partitions In Spark Alter table my_table drop partition(p_col > 0) // does. Get the list of partitions and conditionally filter them. Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c). Welcome to our deep dive into the world of apache spark, where we'll be focusing on. Drop Multiple Partitions In Spark.
From garrens.com
Spark File Format Showdown CSV vs JSON vs Parquet Garren's [Big Drop Multiple Partitions In Spark With this clause, the drop partitions command will only execute if the partition exists in the hive table. // deletes all data, but keeps partitions in metastore. Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: This is a key area. On spark, hive, and small files: We have another. Drop Multiple Partitions In Spark.
From timilearning.com
MIT 6.824 Lecture 15 Spark Drop Multiple Partitions In Spark We have another problem — there are a lot of recommendations to limit amount of partitions in about 10000. This is a key area. On spark, hive, and small files: With this clause, the drop partitions command will only execute if the partition exists in the hive table. Welcome to our deep dive into the world of apache spark, where. Drop Multiple Partitions In Spark.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Drop Multiple Partitions In Spark Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: Get the list of partitions and conditionally filter them. With this clause, the drop partitions command will only execute if the partition exists in the hive table. This is a key area. On spark, hive, and small files: Alter table my_table. Drop Multiple Partitions In Spark.
From sparkbyexamples.com
Spark Read Multiple CSV Files Spark By {Examples} Drop Multiple Partitions In Spark Either drop the individual partitions one by one, or pass them as a. We have another problem — there are a lot of recommendations to limit amount of partitions in about 10000. With this clause, the drop partitions command will only execute if the partition exists in the hive table. Welcome to our deep dive into the world of apache. Drop Multiple Partitions In Spark.
From medium.com
Spark Dynamic Partition Inserts — Part 1 by Itai Yaffe NielsenTel Drop Multiple Partitions In Spark Get the list of partitions and conditionally filter them. With this clause, the drop partitions command will only execute if the partition exists in the hive table. On spark, hive, and small files: // deletes all data, but keeps partitions in metastore. Either drop the individual partitions one by one, or pass them as a. This is a key area.. Drop Multiple Partitions In Spark.
From medium.com
Spark Partitioning Partition Understanding Medium Drop Multiple Partitions In Spark Alter table my_table drop partition(p_col > 0) // does. On spark, hive, and small files: With this clause, the drop partitions command will only execute if the partition exists in the hive table. Either drop the individual partitions one by one, or pass them as a. Welcome to our deep dive into the world of apache spark, where we'll be. Drop Multiple Partitions In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Drop Multiple Partitions In Spark Either drop the individual partitions one by one, or pass them as a. Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: This is a key area. Alter table my_table drop partition(p_col > 0) // does. Get the list of partitions and conditionally filter them. On spark, hive, and small. Drop Multiple Partitions In Spark.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient Drop Multiple Partitions In Spark Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c). Either drop the individual partitions one by one, or pass them as a. Get the list of partitions and conditionally filter them. We have another problem — there are a lot of recommendations to. Drop Multiple Partitions In Spark.
From www.mssqltips.com
Spark Engine File Format Options and the Associated Pros and Cons Drop Multiple Partitions In Spark Get the list of partitions and conditionally filter them. Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: Alter table my_table drop partition(p_col > 0) // does. On spark, hive, and small files: Hive partitions are used to split the larger table into several smaller parts based on one or. Drop Multiple Partitions In Spark.
From www.waitingforcode.com
What's new in Apache Spark 3.0 shuffle partitions coalesce on Drop Multiple Partitions In Spark Alter table my_table drop partition(p_col > 0) // does. Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c). // deletes all data, but keeps partitions in metastore. Either drop the individual partitions one by one, or pass them as a. With this clause,. Drop Multiple Partitions In Spark.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Drop Multiple Partitions In Spark Get the list of partitions and conditionally filter them. This is a key area. Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: Either drop the individual partitions one by one, or pass them as a. Alter table my_table drop partition(p_col > 0) // does. With this clause, the drop. Drop Multiple Partitions In Spark.
From erikerlandson.github.io
Some Implications of Supporting the Scala drop Method for Spark RDDs Drop Multiple Partitions In Spark // deletes all data, but keeps partitions in metastore. Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c). Get the list of partitions and conditionally filter them. Either drop the individual partitions one by one, or pass them as a. We have another. Drop Multiple Partitions In Spark.
From laptrinhx.com
How to use Spark clusters for parallel processing Big Data LaptrinhX Drop Multiple Partitions In Spark Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c). Either drop the individual partitions one by one, or pass them as a. Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: With this. Drop Multiple Partitions In Spark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Drop Multiple Partitions In Spark On spark, hive, and small files: Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: // deletes all data, but keeps partitions in metastore. With this clause, the drop partitions command will only execute if the partition exists in the hive table. We have another problem — there are a. Drop Multiple Partitions In Spark.
From 0x0fff.com
Spark Architecture Shuffle Distributed Systems Architecture Drop Multiple Partitions In Spark On spark, hive, and small files: This is a key area. Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: Alter table my_table drop partition(p_col > 0) // does. Get the list of partitions and conditionally filter them. // deletes all data, but keeps partitions in metastore. We have another. Drop Multiple Partitions In Spark.
From blog.csdn.net
Spark基础 之 Partition_spark partitionCSDN博客 Drop Multiple Partitions In Spark Alter table my_table drop partition(p_col > 0) // does. With this clause, the drop partitions command will only execute if the partition exists in the hive table. Either drop the individual partitions one by one, or pass them as a. Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition. Drop Multiple Partitions In Spark.
From www.researchgate.net
Spark partition an LMDB Database Download Scientific Diagram Drop Multiple Partitions In Spark Alter table my_table drop partition(p_col > 0) // does. This is a key area. With this clause, the drop partitions command will only execute if the partition exists in the hive table. Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: Get the list of partitions and conditionally filter them.. Drop Multiple Partitions In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Drop Multiple Partitions In Spark This is a key area. Either drop the individual partitions one by one, or pass them as a. Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: We have another problem — there are a lot of recommendations to limit amount of partitions in about 10000. With this clause, the. Drop Multiple Partitions In Spark.
From www.simplilearn.com
Spark Parallelize The Essential Element of Spark Drop Multiple Partitions In Spark On spark, hive, and small files: Either drop the individual partitions one by one, or pass them as a. // deletes all data, but keeps partitions in metastore. Alter table my_table drop partition(p_col > 0) // does. We have another problem — there are a lot of recommendations to limit amount of partitions in about 10000. This is a key. Drop Multiple Partitions In Spark.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Drop Multiple Partitions In Spark With this clause, the drop partitions command will only execute if the partition exists in the hive table. Alter table my_table drop partition(p_col > 0) // does. Either drop the individual partitions one by one, or pass them as a. Welcome to our deep dive into the world of apache spark, where we'll be focusing on a crucial aspect: This. Drop Multiple Partitions In Spark.