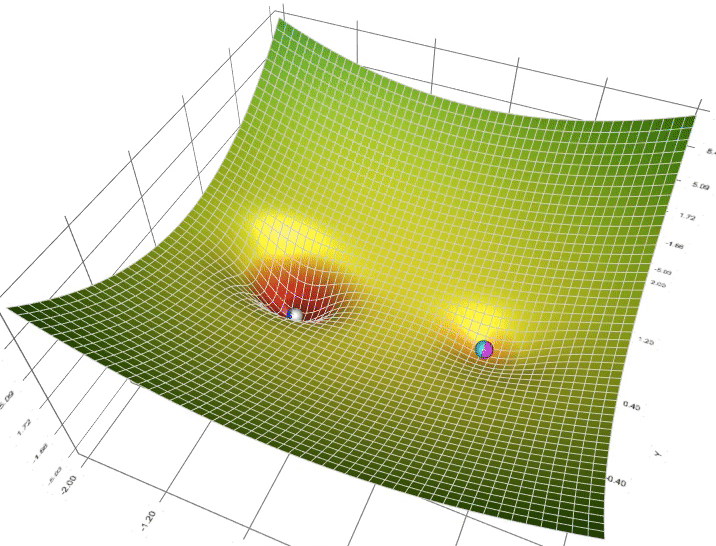
Adam Vs Adagrad Vs Rmsprop . gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. developed by kingma and ba in 2014, adam combines the benefits of two other optimization techniques: adam (adaptive moment estimation), proposed by kingma and ba in 2015, is a blend of rmsprop and adagrad. Moreover, it has a straightforward implementation and little memory in this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will compare its performance. Adagrad and sgd have the worst performance, as they achieve the highest test loss and adam and rmsprop have the best performance, as they achieve the lowest test loss and the highest test accuracy for most learning rates. rmsprop (green) vs adagrad (white). It combines the advantages of both, thus. Let j (θ) be a function. with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when. This article will delve into the algorithmic foundations of adam. The second run also shows the sum of gradient squared represented by the squares. The first run just shows the balls; considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks.
from towardsdatascience.com
This article will delve into the algorithmic foundations of adam. Adagrad and sgd have the worst performance, as they achieve the highest test loss and adam (adaptive moment estimation), proposed by kingma and ba in 2015, is a blend of rmsprop and adagrad. in this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will compare its performance. rmsprop (green) vs adagrad (white). Let j (θ) be a function. considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when. gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. It combines the advantages of both, thus.
A Visual Explanation of Gradient Descent Methods (Momentum, AdaGrad
Adam Vs Adagrad Vs Rmsprop rmsprop (green) vs adagrad (white). This article will delve into the algorithmic foundations of adam. considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. in this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will compare its performance. The first run just shows the balls; The second run also shows the sum of gradient squared represented by the squares. gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. Adagrad and sgd have the worst performance, as they achieve the highest test loss and Let j (θ) be a function. Moreover, it has a straightforward implementation and little memory It combines the advantages of both, thus. rmsprop (green) vs adagrad (white). with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when. adam and rmsprop have the best performance, as they achieve the lowest test loss and the highest test accuracy for most learning rates. developed by kingma and ba in 2014, adam combines the benefits of two other optimization techniques: adam (adaptive moment estimation), proposed by kingma and ba in 2015, is a blend of rmsprop and adagrad.
From blog.csdn.net
sgdm是什么CSDN博客 Adam Vs Adagrad Vs Rmsprop Moreover, it has a straightforward implementation and little memory Let j (θ) be a function. This article will delve into the algorithmic foundations of adam. rmsprop (green) vs adagrad (white). adam and rmsprop have the best performance, as they achieve the lowest test loss and the highest test accuracy for most learning rates. with adagrad, rmsprop and. Adam Vs Adagrad Vs Rmsprop.
From blog.paperspace.com
Intro to optimization in deep learning Momentum, RMSProp and Adam Adam Vs Adagrad Vs Rmsprop The second run also shows the sum of gradient squared represented by the squares. rmsprop (green) vs adagrad (white). adam and rmsprop have the best performance, as they achieve the lowest test loss and the highest test accuracy for most learning rates. It combines the advantages of both, thus. developed by kingma and ba in 2014, adam. Adam Vs Adagrad Vs Rmsprop.
From www.youtube.com
Advanced Gradient Descent Variations SGD, Adam, RMSprop, and Adagrad Adam Vs Adagrad Vs Rmsprop gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. adam (adaptive moment estimation), proposed by kingma and ba in 2015, is a blend of rmsprop and adagrad. in this article, we will go through the adam and rmsprop starting from its algorithm. Adam Vs Adagrad Vs Rmsprop.
From www.codenong.com
002 SGD、SGDM、Adagrad、RMSProp、Adam、AMSGrad、NAG 码农家园 Adam Vs Adagrad Vs Rmsprop It combines the advantages of both, thus. adam (adaptive moment estimation), proposed by kingma and ba in 2015, is a blend of rmsprop and adagrad. This article will delve into the algorithmic foundations of adam. gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black. Adam Vs Adagrad Vs Rmsprop.
From github.com
GitHub EliaFantini/RMSPropandAMSGradforMNISTimageclassification Adam Vs Adagrad Vs Rmsprop The second run also shows the sum of gradient squared represented by the squares. Let j (θ) be a function. gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. adam (adaptive moment estimation), proposed by kingma and ba in 2015, is a blend. Adam Vs Adagrad Vs Rmsprop.
From zhuanlan.zhihu.com
梯度下降的可视化解释(Momentum,AdaGrad,RMSProp,Adam) 知乎 Adam Vs Adagrad Vs Rmsprop with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when. Adagrad and sgd have the worst performance, as they achieve the highest test loss and rmsprop (green) vs adagrad (white). It combines the advantages of both, thus. Moreover, it has a straightforward implementation and little memory developed by kingma and. Adam Vs Adagrad Vs Rmsprop.
From zhuanlan.zhihu.com
深度学习随笔——优化算法( SGD、BGD、MBGD、Momentum、NAG、Adagrad、RMSProp、AdaDelta、Adam Adam Vs Adagrad Vs Rmsprop Let j (θ) be a function. It combines the advantages of both, thus. with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when. developed by kingma and ba in 2014, adam combines the benefits of two other optimization techniques: adam (adaptive moment estimation), proposed by kingma and ba in 2015,. Adam Vs Adagrad Vs Rmsprop.
From medium.com
ML入門(十二)SGD, AdaGrad, Momentum, RMSProp, Adam Optimizer by ChungYi Adam Vs Adagrad Vs Rmsprop adam (adaptive moment estimation), proposed by kingma and ba in 2015, is a blend of rmsprop and adagrad. considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. developed by kingma and ba in 2014, adam combines the benefits of two other optimization. Adam Vs Adagrad Vs Rmsprop.
From blog.csdn.net
梯度下降(二):自适应梯度(AdaGrad)、均方根传递(RMSProp)、自适应增量(AdaDelta)、自适应矩估计(Adam Adam Vs Adagrad Vs Rmsprop considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. developed by kingma and ba in 2014, adam combines the benefits of two other optimization techniques: with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when.. Adam Vs Adagrad Vs Rmsprop.
From zhuanlan.zhihu.com
pytorch中常见优化器的SGD,Adagrad,RMSprop,Adam,AdamW的总结 知乎 Adam Vs Adagrad Vs Rmsprop with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when. Adagrad and sgd have the worst performance, as they achieve the highest test loss and Moreover, it has a straightforward implementation and little memory in this article, we will go through the adam and rmsprop starting from its algorithm to its. Adam Vs Adagrad Vs Rmsprop.
From zhuanlan.zhihu.com
机器学习2 优化器(SGD、SGDM、Adagrad、RMSProp、Adam) 知乎 Adam Vs Adagrad Vs Rmsprop gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. in this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will compare its performance. The first run just shows the balls;. Adam Vs Adagrad Vs Rmsprop.
From medium.com
A Complete Guide to Adam and RMSprop Optimizer by Sanghvirajit Adam Vs Adagrad Vs Rmsprop adam and rmsprop have the best performance, as they achieve the lowest test loss and the highest test accuracy for most learning rates. The second run also shows the sum of gradient squared represented by the squares. adam (adaptive moment estimation), proposed by kingma and ba in 2015, is a blend of rmsprop and adagrad. rmsprop (green). Adam Vs Adagrad Vs Rmsprop.
From blog.csdn.net
AdaGrad, RMSprop, AdaDelta; 动量法, Nesterov加速梯度; Adam_动量法、adagradCSDN博客 Adam Vs Adagrad Vs Rmsprop gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. Let j (θ) be a function. rmsprop (green) vs adagrad (white). in this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later. Adam Vs Adagrad Vs Rmsprop.
From blog.csdn.net
一文搞懂神经网络参数优化器SGD、SGDM、Adagrad、RMSProp、Adam_adam sga rmsprop优化器比较CSDN博客 Adam Vs Adagrad Vs Rmsprop This article will delve into the algorithmic foundations of adam. with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when. in this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will compare its performance. The second run also. Adam Vs Adagrad Vs Rmsprop.
From zhuanlan.zhihu.com
Adagrad、RMSprop、Momentum、Adam 知乎 Adam Vs Adagrad Vs Rmsprop rmsprop (green) vs adagrad (white). It combines the advantages of both, thus. gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. Adagrad and sgd have the worst performance, as they achieve the highest test loss and The second run also shows the sum. Adam Vs Adagrad Vs Rmsprop.
From zhuanlan.zhihu.com
梯度下降的各种变形momentum,adagrad,rmsprop,adam分别解决了什么问题 知乎 Adam Vs Adagrad Vs Rmsprop The first run just shows the balls; Let j (θ) be a function. gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. Moreover, it has a straightforward implementation and little memory adam (adaptive moment estimation), proposed by kingma and ba in 2015, is. Adam Vs Adagrad Vs Rmsprop.
From www.youtube.com
Optimization for Deep Learning (Momentum, RMSprop, AdaGrad, Adam) YouTube Adam Vs Adagrad Vs Rmsprop adam and rmsprop have the best performance, as they achieve the lowest test loss and the highest test accuracy for most learning rates. rmsprop (green) vs adagrad (white). gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. This article will delve into. Adam Vs Adagrad Vs Rmsprop.
From www.youtube.com
Adagrad and RMSProp Intuition How Adagrad and RMSProp optimizer work Adam Vs Adagrad Vs Rmsprop adam (adaptive moment estimation), proposed by kingma and ba in 2015, is a blend of rmsprop and adagrad. Adagrad and sgd have the worst performance, as they achieve the highest test loss and Moreover, it has a straightforward implementation and little memory in this article, we will go through the adam and rmsprop starting from its algorithm to. Adam Vs Adagrad Vs Rmsprop.
From blog.csdn.net
“随机梯度下降、牛顿法、动量法、Nesterov、AdaGrad、RMSprop、Adam”CSDN博客 Adam Vs Adagrad Vs Rmsprop Moreover, it has a straightforward implementation and little memory adam (adaptive moment estimation), proposed by kingma and ba in 2015, is a blend of rmsprop and adagrad. Let j (θ) be a function. rmsprop (green) vs adagrad (white). The first run just shows the balls; The second run also shows the sum of gradient squared represented by the. Adam Vs Adagrad Vs Rmsprop.
From blog.csdn.net
一文搞懂神经网络参数优化器SGD、SGDM、Adagrad、RMSProp、Adam_adam sga rmsprop优化器比较CSDN博客 Adam Vs Adagrad Vs Rmsprop This article will delve into the algorithmic foundations of adam. rmsprop (green) vs adagrad (white). adam and rmsprop have the best performance, as they achieve the lowest test loss and the highest test accuracy for most learning rates. It combines the advantages of both, thus. Let j (θ) be a function. adam (adaptive moment estimation), proposed by. Adam Vs Adagrad Vs Rmsprop.
From www.researchgate.net
Comparison of PAL to SGD, SLS, ADAM, RMSProp on training loss Adam Vs Adagrad Vs Rmsprop Adagrad and sgd have the worst performance, as they achieve the highest test loss and in this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will compare its performance. gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms. Adam Vs Adagrad Vs Rmsprop.
From towardsdatascience.com
A Visual Explanation of Gradient Descent Methods (Momentum, AdaGrad Adam Vs Adagrad Vs Rmsprop rmsprop (green) vs adagrad (white). adam (adaptive moment estimation), proposed by kingma and ba in 2015, is a blend of rmsprop and adagrad. with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when. in this article, we will go through the adam and rmsprop starting from its algorithm to. Adam Vs Adagrad Vs Rmsprop.
From zhuanlan.zhihu.com
Adagrad、RMSprop、Momentum、Adam 知乎 Adam Vs Adagrad Vs Rmsprop in this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will compare its performance. adam and rmsprop have the best performance, as they achieve the lowest test loss and the highest test accuracy for most learning rates. Adagrad and sgd have the worst performance, as. Adam Vs Adagrad Vs Rmsprop.
From stats.stackexchange.com
neural networks Does RMSProp/Adam solve vanishing gradient problem Adam Vs Adagrad Vs Rmsprop in this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will compare its performance. considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. with adagrad, rmsprop and adam there. Adam Vs Adagrad Vs Rmsprop.
From www.youtube.com
TIPS & TRICKS Deep Learning How to choose the best optimizer? Adam Adam Vs Adagrad Vs Rmsprop with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when. adam and rmsprop have the best performance, as they achieve the lowest test loss and the highest test accuracy for most learning rates. developed by kingma and ba in 2014, adam combines the benefits of two other optimization techniques: This. Adam Vs Adagrad Vs Rmsprop.
From zhuanlan.zhihu.com
机器学习2 优化器(SGD、SGDM、Adagrad、RMSProp、Adam) 知乎 Adam Vs Adagrad Vs Rmsprop adam (adaptive moment estimation), proposed by kingma and ba in 2015, is a blend of rmsprop and adagrad. Moreover, it has a straightforward implementation and little memory gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. with adagrad, rmsprop and adam there. Adam Vs Adagrad Vs Rmsprop.
From zhuanlan.zhihu.com
梯度下降的可视化解释(Momentum,AdaGrad,RMSProp,Adam) 知乎 Adam Vs Adagrad Vs Rmsprop This article will delve into the algorithmic foundations of adam. in this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will compare its performance. gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as. Adam Vs Adagrad Vs Rmsprop.
From www.researchgate.net
Comparisons of ND optimiser (8), SGD‐M, Adam, AdaGrad, AdamW, and Adam Vs Adagrad Vs Rmsprop It combines the advantages of both, thus. with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when. Adagrad and sgd have the worst performance, as they achieve the highest test loss and gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often. Adam Vs Adagrad Vs Rmsprop.
From zhuanlan.zhihu.com
pytorch中常见优化器的SGD,Adagrad,RMSprop,Adam,AdamW的总结 知乎 Adam Vs Adagrad Vs Rmsprop in this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will compare its performance. Let j (θ) be a function. The second run also shows the sum of gradient squared represented by the squares. adam and rmsprop have the best performance, as they achieve the. Adam Vs Adagrad Vs Rmsprop.
From kunassy.com
【最適化手法】SGD・Momentum・AdaGrad・RMSProp・Adamを図で理解する。 くまと梨 Adam Vs Adagrad Vs Rmsprop Moreover, it has a straightforward implementation and little memory in this article, we will go through the adam and rmsprop starting from its algorithm to its implementation in python, and later we will compare its performance. considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and. Adam Vs Adagrad Vs Rmsprop.
From code84.com
深度学习 优化入门二(SGD、动量(Momentum)、AdaGrad、RMSProp、Adam详解) 源码巴士 Adam Vs Adagrad Vs Rmsprop Let j (θ) be a function. This article will delve into the algorithmic foundations of adam. developed by kingma and ba in 2014, adam combines the benefits of two other optimization techniques: The second run also shows the sum of gradient squared represented by the squares. gradient descent is the preferred way to optimize neural networks and many. Adam Vs Adagrad Vs Rmsprop.
From www.researchgate.net
Test accuracy for four adaptive learning rate techniques. Adam Adam Vs Adagrad Vs Rmsprop considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when. Adagrad and sgd have the worst performance, as they achieve the highest test loss and developed. Adam Vs Adagrad Vs Rmsprop.
From towardsdatascience.com
Learning Parameters, Part 5 AdaGrad, RMSProp, and Adam by Akshay L Adam Vs Adagrad Vs Rmsprop considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when. It combines the advantages of both, thus. Moreover, it has a straightforward implementation and little memory . Adam Vs Adagrad Vs Rmsprop.
From www.researchgate.net
Comparison of Adam and RMSProp optimizers for the DQN and A2C networks Adam Vs Adagrad Vs Rmsprop with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when. The first run just shows the balls; It combines the advantages of both, thus. Moreover, it has a straightforward implementation and little memory Adagrad and sgd have the worst performance, as they achieve the highest test loss and adam and rmsprop. Adam Vs Adagrad Vs Rmsprop.
From allen108108.github.io
Adagrad、RMSprop、Momentum and Adam 特殊的學習率調整方式 Math.py Adam Vs Adagrad Vs Rmsprop considered as a combination of momentum and rmsprop, adam is the most superior of them which robustly adapts to large datasets and deep networks. with adagrad, rmsprop and adam there are technical possibilities to make the gradient descent more efficient when. gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms. Adam Vs Adagrad Vs Rmsprop.