How To Set Number Of Partitions In Spark Dataframe . Repartition is a full shuffle operation, where whole data is taken out from existing. You can even set spark.sql.shuffle.partitions this property after. The textfile method also takes an optional second argument for controlling the number of partitions of the file. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name By default, spark creates one partition for each block of the file (blocks. The repartition method can be used to either increase or decrease the number of partitions in a dataframe. How does one calculate the 'optimal' number of partitions based on the size of the dataframe? You can call repartition() on dataframe for setting partitions. While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. Read the input data with the number of partitions, that matches your core count; I've heard from other engineers.
from docs-gcp.qubole.com
While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. The textfile method also takes an optional second argument for controlling the number of partitions of the file. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name Repartition is a full shuffle operation, where whole data is taken out from existing. I've heard from other engineers. You can even set spark.sql.shuffle.partitions this property after. Read the input data with the number of partitions, that matches your core count; By default, spark creates one partition for each block of the file (blocks. The repartition method can be used to either increase or decrease the number of partitions in a dataframe. You can call repartition() on dataframe for setting partitions.
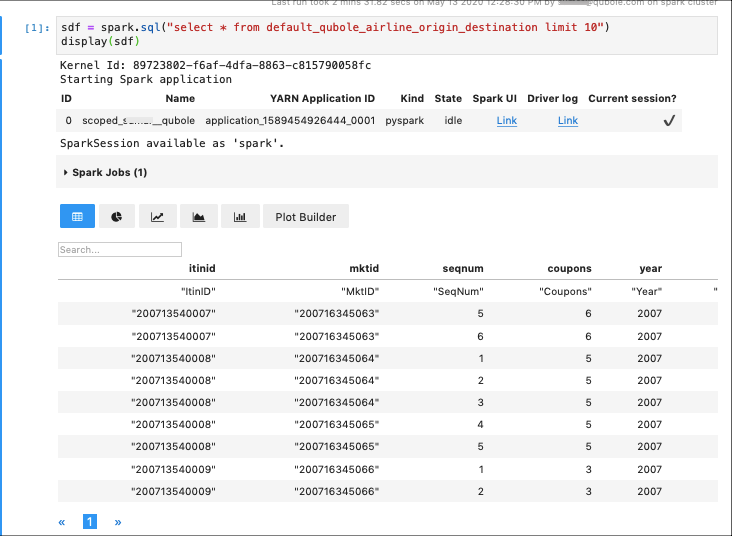
Visualizing Spark Dataframes — Qubole Data Service documentation
How To Set Number Of Partitions In Spark Dataframe The repartition method can be used to either increase or decrease the number of partitions in a dataframe. The repartition method can be used to either increase or decrease the number of partitions in a dataframe. Read the input data with the number of partitions, that matches your core count; While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. Repartition is a full shuffle operation, where whole data is taken out from existing. How does one calculate the 'optimal' number of partitions based on the size of the dataframe? Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name The textfile method also takes an optional second argument for controlling the number of partitions of the file. You can even set spark.sql.shuffle.partitions this property after. I've heard from other engineers. You can call repartition() on dataframe for setting partitions. By default, spark creates one partition for each block of the file (blocks.
From medium.com
Spark DataFrames. Spark SQL is a Spark module for… by Thejas Babu How To Set Number Of Partitions In Spark Dataframe Repartition is a full shuffle operation, where whole data is taken out from existing. While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. You can call repartition() on dataframe for setting partitions. How does one calculate the 'optimal' number of partitions. How To Set Number Of Partitions In Spark Dataframe.
From stackoverflow.com
Partition a Spark DataFrame based on values in an existing column into How To Set Number Of Partitions In Spark Dataframe The textfile method also takes an optional second argument for controlling the number of partitions of the file. By default, spark creates one partition for each block of the file (blocks. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name You can call repartition() on dataframe for setting partitions.. How To Set Number Of Partitions In Spark Dataframe.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames How To Set Number Of Partitions In Spark Dataframe The repartition method can be used to either increase or decrease the number of partitions in a dataframe. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name You can even set spark.sql.shuffle.partitions this property after. While working with spark/pyspark we often need to know the current number of partitions. How To Set Number Of Partitions In Spark Dataframe.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog How To Set Number Of Partitions In Spark Dataframe Read the input data with the number of partitions, that matches your core count; Repartition is a full shuffle operation, where whole data is taken out from existing. The textfile method also takes an optional second argument for controlling the number of partitions of the file. You can call repartition() on dataframe for setting partitions. You can even set spark.sql.shuffle.partitions. How To Set Number Of Partitions In Spark Dataframe.
From laptrinhx.com
Determining Number of Partitions in Apache Spark— Part I LaptrinhX How To Set Number Of Partitions In Spark Dataframe Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name By default, spark creates one partition for each block of the file (blocks. I've heard from other engineers. You can call repartition() on dataframe for setting partitions. How does one calculate the 'optimal' number of partitions based on the size. How To Set Number Of Partitions In Spark Dataframe.
From www.youtube.com
How to partition and write DataFrame in Spark without deleting How To Set Number Of Partitions In Spark Dataframe Read the input data with the number of partitions, that matches your core count; How does one calculate the 'optimal' number of partitions based on the size of the dataframe? You can even set spark.sql.shuffle.partitions this property after. You can call repartition() on dataframe for setting partitions. The repartition method can be used to either increase or decrease the number. How To Set Number Of Partitions In Spark Dataframe.
From sparkbyexamples.com
Calculate Size of Spark DataFrame & RDD Spark By {Examples} How To Set Number Of Partitions In Spark Dataframe You can even set spark.sql.shuffle.partitions this property after. Read the input data with the number of partitions, that matches your core count; The repartition method can be used to either increase or decrease the number of partitions in a dataframe. The textfile method also takes an optional second argument for controlling the number of partitions of the file. While working. How To Set Number Of Partitions In Spark Dataframe.
From medium.com
Managing Spark Partitions. How data is partitioned and when do you How To Set Number Of Partitions In Spark Dataframe While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. Repartition is a full shuffle operation, where whole data is taken out from existing. Read the input data with the number of partitions, that matches your core count; I've heard from other. How To Set Number Of Partitions In Spark Dataframe.
From www.youtube.com
Determining the number of partitions YouTube How To Set Number Of Partitions In Spark Dataframe While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. Repartition is a full shuffle operation, where whole data is taken out from existing. How does one calculate the 'optimal' number of partitions based on the size of the dataframe? Read the. How To Set Number Of Partitions In Spark Dataframe.
From www.youtube.com
Number of Partitions in Dataframe Spark Tutorial Interview Question How To Set Number Of Partitions In Spark Dataframe How does one calculate the 'optimal' number of partitions based on the size of the dataframe? You can call repartition() on dataframe for setting partitions. By default, spark creates one partition for each block of the file (blocks. Repartition is a full shuffle operation, where whole data is taken out from existing. You can even set spark.sql.shuffle.partitions this property after.. How To Set Number Of Partitions In Spark Dataframe.
From medium.com
Guide to Selection of Number of Partitions while reading Data Files in How To Set Number Of Partitions In Spark Dataframe Repartition is a full shuffle operation, where whole data is taken out from existing. You can call repartition() on dataframe for setting partitions. I've heard from other engineers. By default, spark creates one partition for each block of the file (blocks. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column. How To Set Number Of Partitions In Spark Dataframe.
From laptrinhx.com
Managing Partitions Using Spark Dataframe Methods LaptrinhX / News How To Set Number Of Partitions In Spark Dataframe How does one calculate the 'optimal' number of partitions based on the size of the dataframe? Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name By default, spark creates one partition for each block of the file (blocks. While working with spark/pyspark we often need to know the current. How To Set Number Of Partitions In Spark Dataframe.
From www.youtube.com
Create First Apache Spark DataFrame Spark DataFrame Practical Scala How To Set Number Of Partitions In Spark Dataframe The textfile method also takes an optional second argument for controlling the number of partitions of the file. While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. By default, spark creates one partition for each block of the file (blocks. Pyspark.sql.dataframe.repartition(). How To Set Number Of Partitions In Spark Dataframe.
From www.jetbrains.com
Spark DataFrame coding assistance PyCharm Documentation How To Set Number Of Partitions In Spark Dataframe Read the input data with the number of partitions, that matches your core count; Repartition is a full shuffle operation, where whole data is taken out from existing. While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. Pyspark.sql.dataframe.repartition() method is used. How To Set Number Of Partitions In Spark Dataframe.
From www.projectpro.io
DataFrames number of partitions in spark scala in Databricks How To Set Number Of Partitions In Spark Dataframe How does one calculate the 'optimal' number of partitions based on the size of the dataframe? By default, spark creates one partition for each block of the file (blocks. The textfile method also takes an optional second argument for controlling the number of partitions of the file. You can even set spark.sql.shuffle.partitions this property after. The repartition method can be. How To Set Number Of Partitions In Spark Dataframe.
From www.youtube.com
Apache Spark Data Partitioning Example YouTube How To Set Number Of Partitions In Spark Dataframe While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. The repartition method can be used to either increase or decrease the number of partitions in a dataframe. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of. How To Set Number Of Partitions In Spark Dataframe.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient How To Set Number Of Partitions In Spark Dataframe The repartition method can be used to either increase or decrease the number of partitions in a dataframe. Read the input data with the number of partitions, that matches your core count; The textfile method also takes an optional second argument for controlling the number of partitions of the file. How does one calculate the 'optimal' number of partitions based. How To Set Number Of Partitions In Spark Dataframe.
From docs-gcp.qubole.com
Visualizing Spark Dataframes — Qubole Data Service documentation How To Set Number Of Partitions In Spark Dataframe The textfile method also takes an optional second argument for controlling the number of partitions of the file. You can even set spark.sql.shuffle.partitions this property after. How does one calculate the 'optimal' number of partitions based on the size of the dataframe? The repartition method can be used to either increase or decrease the number of partitions in a dataframe.. How To Set Number Of Partitions In Spark Dataframe.
From sparkbyexamples.com
Spark Create DataFrame with Examples Spark By {Examples} How To Set Number Of Partitions In Spark Dataframe Read the input data with the number of partitions, that matches your core count; Repartition is a full shuffle operation, where whole data is taken out from existing. I've heard from other engineers. You can call repartition() on dataframe for setting partitions. How does one calculate the 'optimal' number of partitions based on the size of the dataframe? The repartition. How To Set Number Of Partitions In Spark Dataframe.
From www.youtube.com
Why should we partition the data in spark? YouTube How To Set Number Of Partitions In Spark Dataframe How does one calculate the 'optimal' number of partitions based on the size of the dataframe? Read the input data with the number of partitions, that matches your core count; Repartition is a full shuffle operation, where whole data is taken out from existing. The repartition method can be used to either increase or decrease the number of partitions in. How To Set Number Of Partitions In Spark Dataframe.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo How To Set Number Of Partitions In Spark Dataframe How does one calculate the 'optimal' number of partitions based on the size of the dataframe? Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name Repartition is a full shuffle operation, where whole data is taken out from existing. By default, spark creates one partition for each block of. How To Set Number Of Partitions In Spark Dataframe.
From sparkbyexamples.com
PySpark Create DataFrame with Examples Spark By {Examples} How To Set Number Of Partitions In Spark Dataframe Repartition is a full shuffle operation, where whole data is taken out from existing. I've heard from other engineers. How does one calculate the 'optimal' number of partitions based on the size of the dataframe? Read the input data with the number of partitions, that matches your core count; While working with spark/pyspark we often need to know the current. How To Set Number Of Partitions In Spark Dataframe.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames How To Set Number Of Partitions In Spark Dataframe Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name You can even set spark.sql.shuffle.partitions this property after. While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. You can call repartition(). How To Set Number Of Partitions In Spark Dataframe.
From www.newsletter.swirlai.com
SAI 26 Partitioning and Bucketing in Spark (Part 1) How To Set Number Of Partitions In Spark Dataframe Repartition is a full shuffle operation, where whole data is taken out from existing. You can even set spark.sql.shuffle.partitions this property after. How does one calculate the 'optimal' number of partitions based on the size of the dataframe? The repartition method can be used to either increase or decrease the number of partitions in a dataframe. While working with spark/pyspark. How To Set Number Of Partitions In Spark Dataframe.
From best-practice-and-impact.github.io
Managing Partitions — Spark at the ONS How To Set Number Of Partitions In Spark Dataframe Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name You can call repartition() on dataframe for setting partitions. While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. I've heard from. How To Set Number Of Partitions In Spark Dataframe.
From www.youtube.com
How to Add Row Number to Spark Dataframe Unique ID Window YouTube How To Set Number Of Partitions In Spark Dataframe I've heard from other engineers. You can call repartition() on dataframe for setting partitions. Read the input data with the number of partitions, that matches your core count; While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. How does one calculate. How To Set Number Of Partitions In Spark Dataframe.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo How To Set Number Of Partitions In Spark Dataframe You can call repartition() on dataframe for setting partitions. While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. The repartition method can be used to either increase or decrease the number of partitions in a dataframe. Pyspark.sql.dataframe.repartition() method is used to. How To Set Number Of Partitions In Spark Dataframe.
From techvidvan.com
Introduction on Apache Spark SQL DataFrame TechVidvan How To Set Number Of Partitions In Spark Dataframe You can even set spark.sql.shuffle.partitions this property after. You can call repartition() on dataframe for setting partitions. Read the input data with the number of partitions, that matches your core count; Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name The textfile method also takes an optional second argument. How To Set Number Of Partitions In Spark Dataframe.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna How To Set Number Of Partitions In Spark Dataframe Repartition is a full shuffle operation, where whole data is taken out from existing. Read the input data with the number of partitions, that matches your core count; You can call repartition() on dataframe for setting partitions. The textfile method also takes an optional second argument for controlling the number of partitions of the file. While working with spark/pyspark we. How To Set Number Of Partitions In Spark Dataframe.
From sparkbyexamples.com
Spark Get Current Number of Partitions of DataFrame Spark By {Examples} How To Set Number Of Partitions In Spark Dataframe How does one calculate the 'optimal' number of partitions based on the size of the dataframe? You can call repartition() on dataframe for setting partitions. While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. I've heard from other engineers. Repartition is. How To Set Number Of Partitions In Spark Dataframe.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders How To Set Number Of Partitions In Spark Dataframe While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name You can call repartition() on dataframe for setting partitions. I've heard from. How To Set Number Of Partitions In Spark Dataframe.
From www.youtube.com
Spark Application Partition By in Spark Chapter 2 LearntoSpark How To Set Number Of Partitions In Spark Dataframe The repartition method can be used to either increase or decrease the number of partitions in a dataframe. While working with spark/pyspark we often need to know the current number of partitions on dataframe/rdd as changing the size/length of the partition is one of the key. You can call repartition() on dataframe for setting partitions. Pyspark.sql.dataframe.repartition() method is used to. How To Set Number Of Partitions In Spark Dataframe.
From medium.com
Simple Method to choose Number of Partitions in Spark by Tharun Kumar How To Set Number Of Partitions In Spark Dataframe How does one calculate the 'optimal' number of partitions based on the size of the dataframe? The repartition method can be used to either increase or decrease the number of partitions in a dataframe. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name The textfile method also takes an. How To Set Number Of Partitions In Spark Dataframe.
From www.coditation.com
How to Tune Spark Performance Dynamic Partitioning Strategies for How To Set Number Of Partitions In Spark Dataframe Repartition is a full shuffle operation, where whole data is taken out from existing. You can call repartition() on dataframe for setting partitions. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name Read the input data with the number of partitions, that matches your core count; The textfile method. How To Set Number Of Partitions In Spark Dataframe.
From www.projectpro.io
How Data Partitioning in Spark helps achieve more parallelism? How To Set Number Of Partitions In Spark Dataframe The repartition method can be used to either increase or decrease the number of partitions in a dataframe. The textfile method also takes an optional second argument for controlling the number of partitions of the file. Repartition is a full shuffle operation, where whole data is taken out from existing. By default, spark creates one partition for each block of. How To Set Number Of Partitions In Spark Dataframe.