Training Set Variance . First example here, in technical term is called low. Split the dataset randomly into two subsets: Generally speaking, best practice is to use only the training set to figure out how to scale / normalize, then blindly apply the same. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. It is a tool to find out how much we benefit from adding more training data. So, same as you'd apply. Yes, that's what it means. A learning curve shows the validation and training score of an estimator for varying numbers of training samples. Basically, mean_t1 and var_t1 become part of the model that you're learning. So you have a dataset that contains the labels (y) and predictors (features x).
from www.cs.cornell.edu
Generally speaking, best practice is to use only the training set to figure out how to scale / normalize, then blindly apply the same. Yes, that's what it means. Split the dataset randomly into two subsets: So, same as you'd apply. Basically, mean_t1 and var_t1 become part of the model that you're learning. So you have a dataset that contains the labels (y) and predictors (features x). It is a tool to find out how much we benefit from adding more training data. A learning curve shows the validation and training score of an estimator for varying numbers of training samples. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. First example here, in technical term is called low.
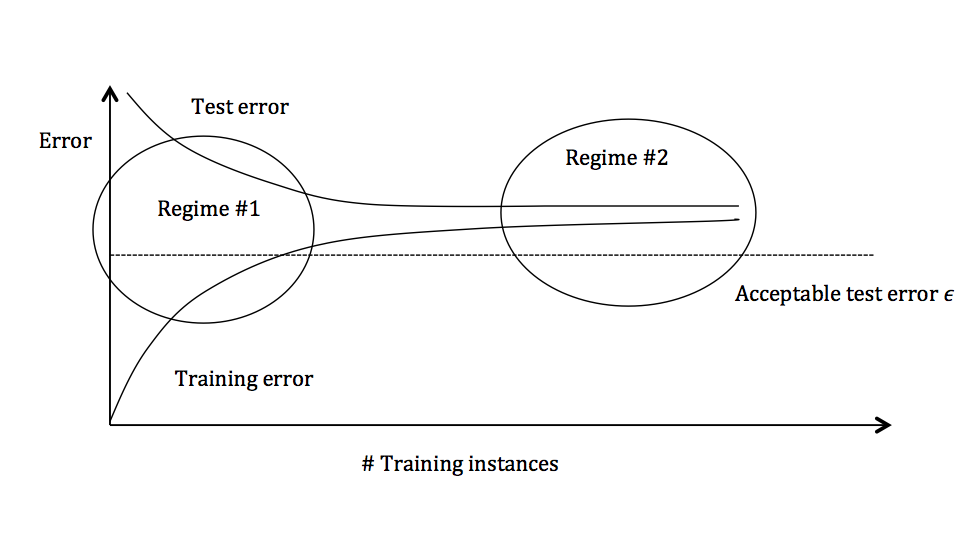
13 Bias/Variance and Model Selection
Training Set Variance Yes, that's what it means. Basically, mean_t1 and var_t1 become part of the model that you're learning. It is a tool to find out how much we benefit from adding more training data. A learning curve shows the validation and training score of an estimator for varying numbers of training samples. So, same as you'd apply. Yes, that's what it means. Generally speaking, best practice is to use only the training set to figure out how to scale / normalize, then blindly apply the same. So you have a dataset that contains the labels (y) and predictors (features x). First example here, in technical term is called low. Split the dataset randomly into two subsets: If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory.
From rasbt.github.io
Biasvariance for classification Training Set Variance A learning curve shows the validation and training score of an estimator for varying numbers of training samples. First example here, in technical term is called low. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. Yes, that's what it means. Generally speaking, best practice is to use only. Training Set Variance.
From www.youtube.com
Variance Clearly Explained (How To Calculate Variance) YouTube Training Set Variance If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. So, same as you'd apply. Generally speaking, best practice is to use only the training set to figure out how to scale / normalize, then blindly apply the same. Basically, mean_t1 and var_t1 become part of the model that you're. Training Set Variance.
From mathsathome.com
How to Calculate Variance Training Set Variance Split the dataset randomly into two subsets: It is a tool to find out how much we benefit from adding more training data. So, same as you'd apply. First example here, in technical term is called low. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. Basically, mean_t1 and. Training Set Variance.
From www.researchgate.net
Principal components and their explained variance ratios from the Training Set Variance Generally speaking, best practice is to use only the training set to figure out how to scale / normalize, then blindly apply the same. Yes, that's what it means. Split the dataset randomly into two subsets: So, same as you'd apply. It is a tool to find out how much we benefit from adding more training data. If you take. Training Set Variance.
From www.wikihow.com
3 Easy Ways to Calculate Variance wikiHow Training Set Variance Generally speaking, best practice is to use only the training set to figure out how to scale / normalize, then blindly apply the same. Yes, that's what it means. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. So, same as you'd apply. First example here, in technical term. Training Set Variance.
From medium.com
BiasVariance TradeOff. In machine learning, the biasvariance… by Training Set Variance A learning curve shows the validation and training score of an estimator for varying numbers of training samples. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. Basically, mean_t1 and var_t1 become part of the model that you're learning. First example here, in technical term is called low. Yes,. Training Set Variance.
From www.v7labs.com
Train Test Validation Split How To & Best Practices [2023] Training Set Variance So, same as you'd apply. Split the dataset randomly into two subsets: A learning curve shows the validation and training score of an estimator for varying numbers of training samples. It is a tool to find out how much we benefit from adding more training data. First example here, in technical term is called low. Yes, that's what it means.. Training Set Variance.
From www.researchgate.net
Explained variance of modified PCs by PCA (category 1 of training Training Set Variance If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. So, same as you'd apply. So you have a dataset that contains the labels (y) and predictors (features x). A learning curve shows the validation and training score of an estimator for varying numbers of training samples. Basically, mean_t1 and. Training Set Variance.
From mathsathome.com
How to Calculate Variance Training Set Variance So, same as you'd apply. Yes, that's what it means. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. Split the dataset randomly into two subsets: So you have a dataset that contains the labels (y) and predictors (features x). First example here, in technical term is called low.. Training Set Variance.
From www.linkedin.com
BiasVariance Tradeoff in Machine Learning Training Set Variance Split the dataset randomly into two subsets: Basically, mean_t1 and var_t1 become part of the model that you're learning. So, same as you'd apply. First example here, in technical term is called low. Generally speaking, best practice is to use only the training set to figure out how to scale / normalize, then blindly apply the same. Yes, that's what. Training Set Variance.
From www.cs.cornell.edu
13 Bias/Variance and Model Selection Training Set Variance Basically, mean_t1 and var_t1 become part of the model that you're learning. So, same as you'd apply. A learning curve shows the validation and training score of an estimator for varying numbers of training samples. First example here, in technical term is called low. Generally speaking, best practice is to use only the training set to figure out how to. Training Set Variance.
From blog.grio.com
An Introduction to Machine Learning Grio Blog Training Set Variance Basically, mean_t1 and var_t1 become part of the model that you're learning. Split the dataset randomly into two subsets: Yes, that's what it means. First example here, in technical term is called low. So you have a dataset that contains the labels (y) and predictors (features x). If you take the mean and variance of the whole dataset you'll be. Training Set Variance.
From www.teachoo.com
Example 9 Find variance and standard deviation Class 11 Training Set Variance So you have a dataset that contains the labels (y) and predictors (features x). It is a tool to find out how much we benefit from adding more training data. Split the dataset randomly into two subsets: So, same as you'd apply. Yes, that's what it means. Generally speaking, best practice is to use only the training set to figure. Training Set Variance.
From www.wikihow.com
3 Ways to Calculate Variance wikiHow Training Set Variance If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. A learning curve shows the validation and training score of an estimator for varying numbers of training samples. So, same as you'd apply. First example here, in technical term is called low. So you have a dataset that contains the. Training Set Variance.
From www.wikihow.com
3 Easy Ways to Calculate Variance wikiHow Training Set Variance A learning curve shows the validation and training score of an estimator for varying numbers of training samples. So you have a dataset that contains the labels (y) and predictors (features x). Split the dataset randomly into two subsets: So, same as you'd apply. Generally speaking, best practice is to use only the training set to figure out how to. Training Set Variance.
From articles.outlier.org
How To Calculate Variance In 4 Simple Steps Outlier Training Set Variance If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. Split the dataset randomly into two subsets: First example here, in technical term is called low. So, same as you'd apply. Generally speaking, best practice is to use only the training set to figure out how to scale / normalize,. Training Set Variance.
From ogrisel.github.io
2.3.3. Machine Learning 102 Practical Advice — scikitlearn 0.11git Training Set Variance So you have a dataset that contains the labels (y) and predictors (features x). Split the dataset randomly into two subsets: It is a tool to find out how much we benefit from adding more training data. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. Basically, mean_t1 and. Training Set Variance.
From www.youtube.com
Input variables, target variable, train and test data intuition Training Set Variance Yes, that's what it means. Split the dataset randomly into two subsets: Generally speaking, best practice is to use only the training set to figure out how to scale / normalize, then blindly apply the same. It is a tool to find out how much we benefit from adding more training data. So, same as you'd apply. So you have. Training Set Variance.
From www.researchgate.net
Explained variance for each principal component from PCA in the Training Set Variance Basically, mean_t1 and var_t1 become part of the model that you're learning. It is a tool to find out how much we benefit from adding more training data. Generally speaking, best practice is to use only the training set to figure out how to scale / normalize, then blindly apply the same. If you take the mean and variance of. Training Set Variance.
From mathsathome.com
How to Calculate Variance Training Set Variance A learning curve shows the validation and training score of an estimator for varying numbers of training samples. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. Yes, that's what it means. Basically, mean_t1 and var_t1 become part of the model that you're learning. So you have a dataset. Training Set Variance.
From medium.com
Bias and Variance in Machine Learning by Renu Khandelwal Data Training Set Variance Yes, that's what it means. Basically, mean_t1 and var_t1 become part of the model that you're learning. So you have a dataset that contains the labels (y) and predictors (features x). A learning curve shows the validation and training score of an estimator for varying numbers of training samples. It is a tool to find out how much we benefit. Training Set Variance.
From www.youtube.com
How To Calculate Variance YouTube Training Set Variance So, same as you'd apply. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. So you have a dataset that contains the labels (y) and predictors (features x). Basically, mean_t1 and var_t1 become part of the model that you're learning. A learning curve shows the validation and training score. Training Set Variance.
From www.researchgate.net
Sample variance explained by the MLR estimation approach for the Training Set Variance Basically, mean_t1 and var_t1 become part of the model that you're learning. So, same as you'd apply. It is a tool to find out how much we benefit from adding more training data. First example here, in technical term is called low. If you take the mean and variance of the whole dataset you'll be introducing future information into the. Training Set Variance.
From www.researchgate.net
Training of dimensionality reduction techniques. (a) Explained variance Training Set Variance So you have a dataset that contains the labels (y) and predictors (features x). Split the dataset randomly into two subsets: A learning curve shows the validation and training score of an estimator for varying numbers of training samples. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. First. Training Set Variance.
From www.researchgate.net
Sample variance explained by the MLR estimation approach for the Training Set Variance It is a tool to find out how much we benefit from adding more training data. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. A learning curve shows the validation and training score of an estimator for varying numbers of training samples. Generally speaking, best practice is to. Training Set Variance.
From www.researchgate.net
Qualitative evidence of high variance. Examples from training set Training Set Variance It is a tool to find out how much we benefit from adding more training data. Split the dataset randomly into two subsets: First example here, in technical term is called low. So you have a dataset that contains the labels (y) and predictors (features x). Yes, that's what it means. Generally speaking, best practice is to use only the. Training Set Variance.
From www.researchgate.net
Variance of the components in the training set. Download Scientific Training Set Variance First example here, in technical term is called low. Generally speaking, best practice is to use only the training set to figure out how to scale / normalize, then blindly apply the same. Yes, that's what it means. It is a tool to find out how much we benefit from adding more training data. If you take the mean and. Training Set Variance.
From www.researchgate.net
7 Difference between testing and training variance. GR4J model Training Set Variance A learning curve shows the validation and training score of an estimator for varying numbers of training samples. It is a tool to find out how much we benefit from adding more training data. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory. Basically, mean_t1 and var_t1 become part. Training Set Variance.
From slideplayer.com
CS639 Data Management for Data Science ppt download Training Set Variance Yes, that's what it means. It is a tool to find out how much we benefit from adding more training data. A learning curve shows the validation and training score of an estimator for varying numbers of training samples. So you have a dataset that contains the labels (y) and predictors (features x). Generally speaking, best practice is to use. Training Set Variance.
From www.teachoo.com
Example 10 Calculate mean, variance, standard deviation Training Set Variance Basically, mean_t1 and var_t1 become part of the model that you're learning. Split the dataset randomly into two subsets: So you have a dataset that contains the labels (y) and predictors (features x). A learning curve shows the validation and training score of an estimator for varying numbers of training samples. Yes, that's what it means. If you take the. Training Set Variance.
From deepai.org
Optimal Training of Mean Variance Estimation Neural Networks DeepAI Training Set Variance Generally speaking, best practice is to use only the training set to figure out how to scale / normalize, then blindly apply the same. So, same as you'd apply. Split the dataset randomly into two subsets: First example here, in technical term is called low. Basically, mean_t1 and var_t1 become part of the model that you're learning. So you have. Training Set Variance.
From www.researchgate.net
Results of Analysis of Variance of Training for the Internal Training Set Variance Basically, mean_t1 and var_t1 become part of the model that you're learning. Split the dataset randomly into two subsets: First example here, in technical term is called low. A learning curve shows the validation and training score of an estimator for varying numbers of training samples. If you take the mean and variance of the whole dataset you'll be introducing. Training Set Variance.
From www.researchgate.net
The variance between the data features. Eighty percent of the variance Training Set Variance A learning curve shows the validation and training score of an estimator for varying numbers of training samples. Generally speaking, best practice is to use only the training set to figure out how to scale / normalize, then blindly apply the same. It is a tool to find out how much we benefit from adding more training data. First example. Training Set Variance.
From www.researchgate.net
Factor Analysis Total Variance Explained, Sample 1 Variance Explained Training Set Variance It is a tool to find out how much we benefit from adding more training data. Generally speaking, best practice is to use only the training set to figure out how to scale / normalize, then blindly apply the same. So you have a dataset that contains the labels (y) and predictors (features x). First example here, in technical term. Training Set Variance.
From www.researchgate.net
Biasvariance tradeoff in machine learning. This figure illustrates Training Set Variance So you have a dataset that contains the labels (y) and predictors (features x). Basically, mean_t1 and var_t1 become part of the model that you're learning. It is a tool to find out how much we benefit from adding more training data. So, same as you'd apply. First example here, in technical term is called low. A learning curve shows. Training Set Variance.