Similarity Test Statistics . Figure 1 shows two graphs that compare the means and medians of. One of the most common ways to measure similarity of two sets is to compare their data summary via mean and median. It is used in hypothesis testing, with a null hypothesis that. On the other hand, the dissimilarity measure is to tell. Testing hypothesis of no group differences. We can test this using a one sided f test for variance. Likelihood ratio, and lagrange multiplier tests in econometrics by robert f. In data science, the similarity measure is a way of measuring how data samples are related or closed to each other. Suppose i have $k$ samples from 2 independent experiments (service times by 2. The test statistic tells you how different two or more groups are from the overall population mean, or how different a linear slope is from the slope predicted by a null hypothesis. If the ratio var (x. (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null.
from www.onlinemathlearning.com
Suppose i have $k$ samples from 2 independent experiments (service times by 2. If the ratio var (x. We can test this using a one sided f test for variance. One of the most common ways to measure similarity of two sets is to compare their data summary via mean and median. It is used in hypothesis testing, with a null hypothesis that. Testing hypothesis of no group differences. In data science, the similarity measure is a way of measuring how data samples are related or closed to each other. The test statistic tells you how different two or more groups are from the overall population mean, or how different a linear slope is from the slope predicted by a null hypothesis. (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null. On the other hand, the dissimilarity measure is to tell.
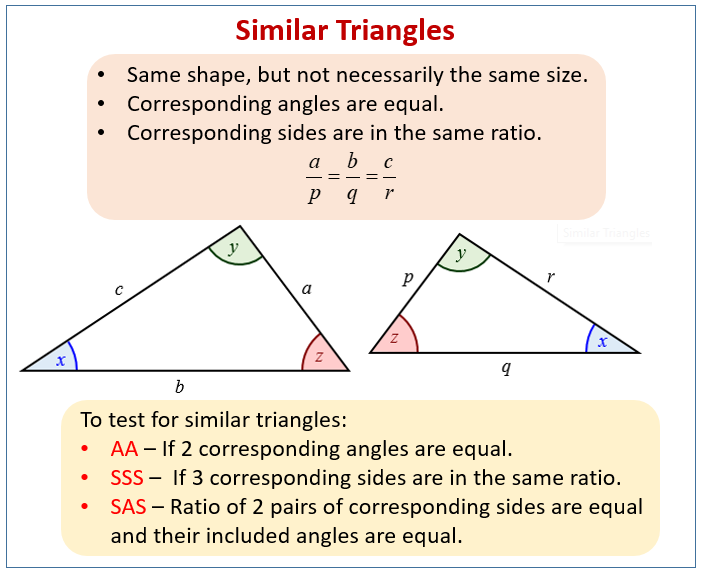
Using Similar Triangles (examples, solutions, videos, lessons
Similarity Test Statistics Testing hypothesis of no group differences. Testing hypothesis of no group differences. In data science, the similarity measure is a way of measuring how data samples are related or closed to each other. Likelihood ratio, and lagrange multiplier tests in econometrics by robert f. Suppose i have $k$ samples from 2 independent experiments (service times by 2. The test statistic tells you how different two or more groups are from the overall population mean, or how different a linear slope is from the slope predicted by a null hypothesis. Figure 1 shows two graphs that compare the means and medians of. One of the most common ways to measure similarity of two sets is to compare their data summary via mean and median. (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null. We can test this using a one sided f test for variance. If the ratio var (x. It is used in hypothesis testing, with a null hypothesis that. On the other hand, the dissimilarity measure is to tell.
From desklib.com
SAS Similarity Test for Triangles Similarity Test Statistics If the ratio var (x. Suppose i have $k$ samples from 2 independent experiments (service times by 2. One of the most common ways to measure similarity of two sets is to compare their data summary via mean and median. It is used in hypothesis testing, with a null hypothesis that. We can test this using a one sided f. Similarity Test Statistics.
From www.researchgate.net
Summary of similarity metric tests for the selected regions of Similarity Test Statistics Figure 1 shows two graphs that compare the means and medians of. Likelihood ratio, and lagrange multiplier tests in econometrics by robert f. Suppose i have $k$ samples from 2 independent experiments (service times by 2. (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null. In data science, the similarity measure is a. Similarity Test Statistics.
From www.youtube.com
Math2 video25 example of similarity of test YouTube Similarity Test Statistics If the ratio var (x. We can test this using a one sided f test for variance. (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null. It is used in hypothesis testing, with a null hypothesis that. Figure 1 shows two graphs that compare the means and medians of. One of the most. Similarity Test Statistics.
From www.statstest.com
Paired Samples TTest Similarity Test Statistics We can test this using a one sided f test for variance. The test statistic tells you how different two or more groups are from the overall population mean, or how different a linear slope is from the slope predicted by a null hypothesis. One of the most common ways to measure similarity of two sets is to compare their. Similarity Test Statistics.
From studylib.net
Table 4. Symbols used in statistics Similarity Test Statistics One of the most common ways to measure similarity of two sets is to compare their data summary via mean and median. The test statistic tells you how different two or more groups are from the overall population mean, or how different a linear slope is from the slope predicted by a null hypothesis. On the other hand, the dissimilarity. Similarity Test Statistics.
From worksheetdbchadic.z19.web.core.windows.net
Similar Triangles Cheat Sheet Similarity Test Statistics In data science, the similarity measure is a way of measuring how data samples are related or closed to each other. The test statistic tells you how different two or more groups are from the overall population mean, or how different a linear slope is from the slope predicted by a null hypothesis. It is used in hypothesis testing, with. Similarity Test Statistics.
From www.slideserve.com
PPT Similarity PowerPoint Presentation, free download ID5569472 Similarity Test Statistics Likelihood ratio, and lagrange multiplier tests in econometrics by robert f. We can test this using a one sided f test for variance. If the ratio var (x. It is used in hypothesis testing, with a null hypothesis that. One of the most common ways to measure similarity of two sets is to compare their data summary via mean and. Similarity Test Statistics.
From slideplayer.com
Similarity Tests for Triangles ppt download Similarity Test Statistics Suppose i have $k$ samples from 2 independent experiments (service times by 2. If the ratio var (x. Likelihood ratio, and lagrange multiplier tests in econometrics by robert f. (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null. It is used in hypothesis testing, with a null hypothesis that. On the other hand,. Similarity Test Statistics.
From www.bachelorprint.com
Statistical Tests Different Types & Examples Similarity Test Statistics (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null. Likelihood ratio, and lagrange multiplier tests in econometrics by robert f. The test statistic tells you how different two or more groups are from the overall population mean, or how different a linear slope is from the slope predicted by a null hypothesis. We. Similarity Test Statistics.
From www.researchgate.net
Similarity statistics for each pair of multimagnification images Similarity Test Statistics (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null. Likelihood ratio, and lagrange multiplier tests in econometrics by robert f. Figure 1 shows two graphs that compare the means and medians of. If the ratio var (x. The test statistic tells you how different two or more groups are from the overall population. Similarity Test Statistics.
From slideplayer.com
Similarity Tests for Triangles ppt download Similarity Test Statistics It is used in hypothesis testing, with a null hypothesis that. In data science, the similarity measure is a way of measuring how data samples are related or closed to each other. We can test this using a one sided f test for variance. Testing hypothesis of no group differences. Likelihood ratio, and lagrange multiplier tests in econometrics by robert. Similarity Test Statistics.
From www.youtube.com
Types of similarity tests for triangles and examples YouTube Similarity Test Statistics On the other hand, the dissimilarity measure is to tell. In data science, the similarity measure is a way of measuring how data samples are related or closed to each other. One of the most common ways to measure similarity of two sets is to compare their data summary via mean and median. Likelihood ratio, and lagrange multiplier tests in. Similarity Test Statistics.
From www.researchgate.net
Sampling for the niche similarity test. I and D are two distinct Similarity Test Statistics On the other hand, the dissimilarity measure is to tell. Testing hypothesis of no group differences. (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null. It is used in hypothesis testing, with a null hypothesis that. Suppose i have $k$ samples from 2 independent experiments (service times by 2. Likelihood ratio, and lagrange. Similarity Test Statistics.
From www.biochemia-medica.com
Comparing groups for statistical differences how to choose the right Similarity Test Statistics One of the most common ways to measure similarity of two sets is to compare their data summary via mean and median. Figure 1 shows two graphs that compare the means and medians of. In data science, the similarity measure is a way of measuring how data samples are related or closed to each other. Likelihood ratio, and lagrange multiplier. Similarity Test Statistics.
From www.researchgate.net
The similarity distribution and average similarity in the whole test Similarity Test Statistics On the other hand, the dissimilarity measure is to tell. One of the most common ways to measure similarity of two sets is to compare their data summary via mean and median. The test statistic tells you how different two or more groups are from the overall population mean, or how different a linear slope is from the slope predicted. Similarity Test Statistics.
From www.researchgate.net
Ttest of similarity comparison of validation results Download Similarity Test Statistics (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null. Testing hypothesis of no group differences. We can test this using a one sided f test for variance. On the other hand, the dissimilarity measure is to tell. Figure 1 shows two graphs that compare the means and medians of. It is used in. Similarity Test Statistics.
From studylib.net
9 O monthly test Jan sTATISTICS, SIMILARITY AND CONGRUENCY Similarity Test Statistics Likelihood ratio, and lagrange multiplier tests in econometrics by robert f. We can test this using a one sided f test for variance. It is used in hypothesis testing, with a null hypothesis that. Suppose i have $k$ samples from 2 independent experiments (service times by 2. In data science, the similarity measure is a way of measuring how data. Similarity Test Statistics.
From www.youtube.com
How To... Select the Correct ttest to Compare Two Sample Means YouTube Similarity Test Statistics In data science, the similarity measure is a way of measuring how data samples are related or closed to each other. Figure 1 shows two graphs that compare the means and medians of. It is used in hypothesis testing, with a null hypothesis that. On the other hand, the dissimilarity measure is to tell. Suppose i have $k$ samples from. Similarity Test Statistics.
From www.researchgate.net
ANOSIM (analysis of similarity) statistics for tests involving Similarity Test Statistics (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null. Testing hypothesis of no group differences. The test statistic tells you how different two or more groups are from the overall population mean, or how different a linear slope is from the slope predicted by a null hypothesis. Suppose i have $k$ samples from. Similarity Test Statistics.
From www.scribbr.com
Choosing the Right Statistical Test Types and Examples Similarity Test Statistics Likelihood ratio, and lagrange multiplier tests in econometrics by robert f. (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null. The test statistic tells you how different two or more groups are from the overall population mean, or how different a linear slope is from the slope predicted by a null hypothesis. Figure. Similarity Test Statistics.
From softhints.com
How to Create Similarity Matrix in Python (Cosine, Pearson) Similarity Test Statistics Testing hypothesis of no group differences. Figure 1 shows two graphs that compare the means and medians of. In data science, the similarity measure is a way of measuring how data samples are related or closed to each other. We can test this using a one sided f test for variance. If the ratio var (x. One of the most. Similarity Test Statistics.
From www.youtube.com
Bray Curtis Similarity Index Biostatistics Statistics Bio7 YouTube Similarity Test Statistics One of the most common ways to measure similarity of two sets is to compare their data summary via mean and median. Suppose i have $k$ samples from 2 independent experiments (service times by 2. On the other hand, the dissimilarity measure is to tell. We can test this using a one sided f test for variance. Testing hypothesis of. Similarity Test Statistics.
From learnche.org
2.12. Testing for differences and similarity — Process Improvement Similarity Test Statistics Suppose i have $k$ samples from 2 independent experiments (service times by 2. The test statistic tells you how different two or more groups are from the overall population mean, or how different a linear slope is from the slope predicted by a null hypothesis. Figure 1 shows two graphs that compare the means and medians of. We can test. Similarity Test Statistics.
From www.onlinemathlearning.com
Using Similar Triangles (examples, solutions, videos, lessons Similarity Test Statistics Figure 1 shows two graphs that compare the means and medians of. Suppose i have $k$ samples from 2 independent experiments (service times by 2. (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null. One of the most common ways to measure similarity of two sets is to compare their data summary via. Similarity Test Statistics.
From www.jmp.com
The tDistribution Introduction to Statistics JMP Similarity Test Statistics We can test this using a one sided f test for variance. If the ratio var (x. In data science, the similarity measure is a way of measuring how data samples are related or closed to each other. Testing hypothesis of no group differences. It is used in hypothesis testing, with a null hypothesis that. Likelihood ratio, and lagrange multiplier. Similarity Test Statistics.
From www.r-bloggers.com
Overview of statistical tests Rbloggers Similarity Test Statistics Testing hypothesis of no group differences. Likelihood ratio, and lagrange multiplier tests in econometrics by robert f. The test statistic tells you how different two or more groups are from the overall population mean, or how different a linear slope is from the slope predicted by a null hypothesis. On the other hand, the dissimilarity measure is to tell. Suppose. Similarity Test Statistics.
From towardsdatascience.com
17 types of similarity and dissimilarity measures used in data science Similarity Test Statistics If the ratio var (x. Figure 1 shows two graphs that compare the means and medians of. It is used in hypothesis testing, with a null hypothesis that. (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null. We can test this using a one sided f test for variance. Suppose i have $k$. Similarity Test Statistics.
From www.youtube.com
Similar triangles The SAS test of similarity YouTube Similarity Test Statistics Suppose i have $k$ samples from 2 independent experiments (service times by 2. If the ratio var (x. Testing hypothesis of no group differences. On the other hand, the dissimilarity measure is to tell. Figure 1 shows two graphs that compare the means and medians of. In data science, the similarity measure is a way of measuring how data samples. Similarity Test Statistics.
From www.researchgate.net
Procedure for mean different test and similarity analysis. Download Similarity Test Statistics On the other hand, the dissimilarity measure is to tell. It is used in hypothesis testing, with a null hypothesis that. Figure 1 shows two graphs that compare the means and medians of. Likelihood ratio, and lagrange multiplier tests in econometrics by robert f. One of the most common ways to measure similarity of two sets is to compare their. Similarity Test Statistics.
From www.researchgate.net
Similarity Test Results on Trials of Subject 1 Download Scientific Similarity Test Statistics Likelihood ratio, and lagrange multiplier tests in econometrics by robert f. One of the most common ways to measure similarity of two sets is to compare their data summary via mean and median. (tests whose) size does not depend upon the particular value of θ ∈ θ ∈ null. Testing hypothesis of no group differences. The test statistic tells you. Similarity Test Statistics.
From www.amathsdictionaryforkids.com
similarity tests for triangles A Maths Dictionary for Kids Quick Similarity Test Statistics On the other hand, the dissimilarity measure is to tell. If the ratio var (x. Likelihood ratio, and lagrange multiplier tests in econometrics by robert f. The test statistic tells you how different two or more groups are from the overall population mean, or how different a linear slope is from the slope predicted by a null hypothesis. One of. Similarity Test Statistics.
From learnche.org
2.12. Testing for differences and similarity — Process Improvement Similarity Test Statistics In data science, the similarity measure is a way of measuring how data samples are related or closed to each other. On the other hand, the dissimilarity measure is to tell. Suppose i have $k$ samples from 2 independent experiments (service times by 2. If the ratio var (x. The test statistic tells you how different two or more groups. Similarity Test Statistics.
From www.researchgate.net
Statistics of the similarity data. (A) Variations observed when the Similarity Test Statistics We can test this using a one sided f test for variance. One of the most common ways to measure similarity of two sets is to compare their data summary via mean and median. Testing hypothesis of no group differences. If the ratio var (x. Figure 1 shows two graphs that compare the means and medians of. It is used. Similarity Test Statistics.
From bookdown.org
11 Two Sample Inferential Statistics PSY317L & PSY120R Guidebook Similarity Test Statistics If the ratio var (x. Figure 1 shows two graphs that compare the means and medians of. On the other hand, the dissimilarity measure is to tell. Suppose i have $k$ samples from 2 independent experiments (service times by 2. Testing hypothesis of no group differences. We can test this using a one sided f test for variance. Likelihood ratio,. Similarity Test Statistics.
From www.qualitygurus.com
Two Sample t Test (Independent Samples) Quality Gurus Similarity Test Statistics Suppose i have $k$ samples from 2 independent experiments (service times by 2. It is used in hypothesis testing, with a null hypothesis that. On the other hand, the dissimilarity measure is to tell. If the ratio var (x. Likelihood ratio, and lagrange multiplier tests in econometrics by robert f. (tests whose) size does not depend upon the particular value. Similarity Test Statistics.